一种新型内存(SCM)的简单应用思考
2016-07-16 13:05
351 查看
1.写在前面
在上一篇博客中,我们介绍了SCM的产生及其所具有一些特点,并初步展望了它在实际中可能存在的应用场景和巨大潜力。SCM(Storage-class Memory),它具有大容量、非易失、可字节寻址、存取速度快(几乎与DRAM相当)的突出优势,这使得SCM取代磁盘disk及固态硬盘SSD成为了可能。甚至在不远的将来,当SCM的存取性能超越DRAM,它还可以彻底改变现有的存储器体系结构。
然而,在目前这一阶段,我们更多地还是考虑DRAM/SCM混合内存架构。将DRAM彻底替换掉将是一个渐变的漫长的过程,因为现有的操作系统的很多设计机制是将内存特性考虑进去的,不能一口气吃个胖子。于此类似地,许多应用是面向块的(block-oriented),及将磁盘IO作为主要考量内容融入软件设计中,所以要用SCM替换DISK也是一个不小的挑战,这就需要软件设计者充分利用SCM的存取特点及优势来重新设计byte-oriented的软件。
2.内存计算与大数据
现如今,内存计算是计算机领域一个非常热门的研究方向。不仅学术界如此,工业界更是如此。一篇2015年的TKDE顶级期刊论文survey高屋建瓴地介绍了时下热门的大数据内存计算(和管理技术)
比如在分布式计算方面,基于MapReduce框架实现的开源Hadoop平台就是面向磁盘的,每算完一轮数据就要传中间结果给HDFS(Hadoop Distributed File System),需要大量的磁盘IO,这就造成了Hadoop在进行分布式大数据处理时的性能瓶颈。而Spark则通过将全部数据放入内存中计算,中间结果也保存在内存中极大地提高了系统性能。尤其是在进行迭代式数据处理时,Spark比Hadoop要快几乎一百倍。
在Database存储与恢复方面,传统的数据库系统操作都是磁盘中进行的,而现在许多研究者开始试图将Database放入内存中进行计算和处理,并加入某些特殊的机制来保证数据可靠性和一致性。比如典型的KV-Store内存架构实现有Memcache,MassTree,Redis等等。
简单归结起来,将计算过程从传统的Disk或者SSD中引入到DRAM中,正是利用了DRAM的高速存取特性来加速计算过程,从而提高系统性能。然而DRAM因为掉电易失,不支持数据的持久存储,因此需要格外注意数据容错和恢复方面的设计,这是一个非常具有探索价值的研究领域。
有一篇上海交通大学计算机系并行与分布式计算实验室中的2016FAST会议论文就是利用传统的PBR(Primary-backup Replication)技术与EC(Erasure Coding)相结合来进行数据的容错处理,提高了内存的利用率。
3.NVM在内存计算方面的尝试
许多研究者注意到了NVM可能会对现有的计算机体系产生深远的革命性的影响,并试图做一些基于NVM的设计研发工作,我最近所了解的大多是应用层级的改良操作。比如将KV-Store(一种哈希表数据存储数据库)实现在NVM或者DRAM/NVM混合内存中,将典型的in-memory database 结合NVM保证数据持久存储等。接下来重点挑几篇论文介绍一下研究者们的工作进展。Exploring Storage Class Memory with Key Value Stores是一篇2013年的论文,是据我所知(也是据该项目研究者所知)第一个将KV-Store引入DRAM/SCM—Disk等级结构的研究。他们提出了一个叫做Echo的KV-Store系统,利用了SCM的非易失与可字节寻址的特性。那么,如何才能使DRAM与SCM珠联璧合,发挥各自最大的优势呢?该研究的核心思想是计算操作与持久存储操作的分离,如下图所示:
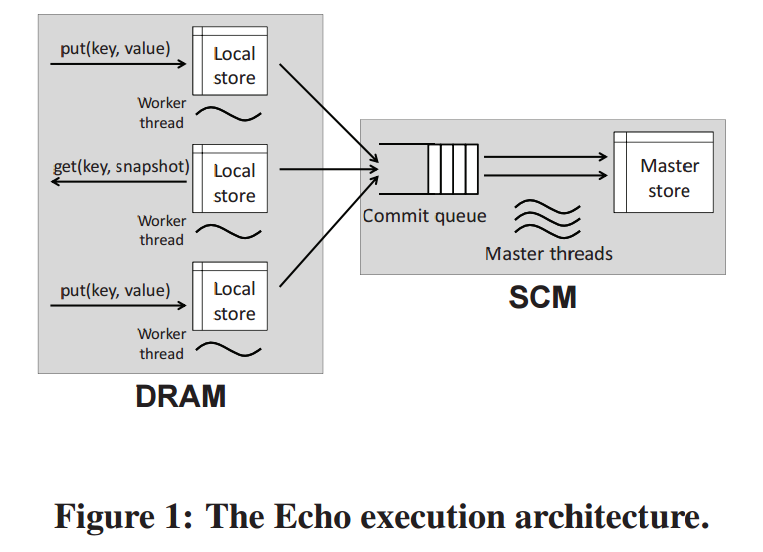
get操作和set操作都由Worker thread来处理,分散的KV数据就存在DRAM中的Local store结构中,当一个(或一组特定的)操作完成时,便可以通过Commit来提交当前操作造成的变化给Master thread所管理的Master store。注意,Master store存储持久的数据,它位于SCM,并且负责多版本的数据管理;而每个不同的Local store之间数据是相互独立的,它们必须通过Master store中存储的持久数据来保持总的同步认知。作者对于引入SCM后的种种设计,如持久内存使用API,版本与存储管理,失败恢复模型,一致性模型,都或详或略地做了比较清晰的介绍。
总体来讲,这篇文章对我还是相当有启发的。比如,在一致性问题的探讨上,Echo依赖的是snapshot,如果替换成timestamp就可以节省相当大的开销;在版本管理和回退方面,作者并没有深入探讨,我认为可以借鉴git使用的类指针标号管理机制,而且允许对不同版本的数据进行读写操作,分别更新至不同的下一版本(不同分支)。若是能引入branch merge操作,对于KV-Store数据版本化管理就可以更加强大和完善,而且切换速度非常快,没有造成多余的开销。而且SCM具有大容量的优点,因此存档多个数据版本并不会造成太高的内存消耗。或者,换一种思路,使用in-place update(原地更新)的方式是一种更加迅速的KV-store更新操作,可以扩展该系统的功能,使之可插拔(既能管理多版本,又能支持原地更新即覆盖上一版本的数据内容)。在故障恢复方面需要再细致考虑cache line操作的数据是否真正被持久存储,以及重启机器后利用映射机制快速定位到系统崩溃前的数据存放位置区,以恢复被打断的任务处理过程。其他思考点其实还在于如何在保证可靠性的前提性再尽可能提高整个系统的执行效率,这才是最后比拼性能时必须面对的实际问题。
像Leveraging Non-volatile Memory for Instant Restarts of In-Memory Database Systems与Persistent Transactional Memory这两篇论文都是比较短小(只有4-5页)的研究汇报,所以它们分别针对内存数据库系统恢复问题与事物内存探讨了与NVM结合的机遇与挑战。但是这两篇论文所提出的研究点依然足够深刻,以至于在数据库和Transaction机制方面欠缺基础的人很难读懂。这里就不再过多介绍(我看的也不是很懂)。
Let’s Talk About Storage & Recovery Methods for Non-Volatile Memory Database Systems这篇论文深刻而细致地讨论了将数据库系统移植到NVM上所面临的存储与恢复问题,并对比了三种方式下(in-place update with logging, copy-on-write without logging, log-structured updates)NVM数据库系统的性能表现。

相关文章推荐
- Tomcat端口被占用解决方法(不用重启)
- 康诺云推出三款智能硬件产品,为健康管理业务搭建数据池
- “传奇”图象数据存储方式
- 超大数据量存储常用数据库分表分库算法总结
- SQL Server误区30日谈 第18天 有关FileStream的存储,垃圾回收以及其它
- MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
- 简单谈谈node.js 版本控制 nvm和 n
- C++实现图的邻接表存储和广度优先遍历实例分析
- 详解Android文件存储
- C#调用sql2000存储过程方法小结
- PHP 存储文本换行实现方法
- 注册表中存储数据库链接字符串的方法
- Mysql中存储UUID去除横线的方法
- MySQLMerge存储引擎
- Redis教程(十):持久化详解
- 深入PHP变量存储的详解
- MySQL存储毫秒数据的方法
- MySQL存储过程中使用动态行转列
- Android App将数据写入内部存储和外部存储的示例
- 简介Android应用中sharedPreferences类存储数据的用法