CS224d笔记2——word2vec
2016-07-15 09:33
274 查看
假期学习了斯坦福的CS224d课程,该课程的主要内容是神经网络在自然语言处理领域的应用。 这里记录相关的学习笔记,大概分成以下几个部分:word2vec,窗口分类,神经网络,循环神经网络,递归神经网络,卷积 神经网络。
人工设计的特征常常定义过多,不完整并且需要花费大量的时间去设计和验证
自动学习的特征容易自适应,并且可以很快的学习
深度学习提供了一个弹性的,通用的学习框架用来表征自然的,视觉的和语言的信息。
深度学习可以用来学习非监督的(来自于生文本)和有监督的(带有特别标记的文本, 例如正向和负向标记)
在2006年深度学习技术开始在一些任务中表现出众,为什么现在才热起来?
深度学习技术受益于越来越多的数据
更快的机器与更多核CPU/GPU对深度学习的普及起了很大的促进作用
新的模型,算法和idea层出不穷
通过深度学习技术提升效果首先发生在语音识别和机器视觉领域,然后开始过渡到NLP领 域
深度学习在所有的NLP层次(音素、形态学、句法、语义)都得到了应用,在所有的NLP层 次的表示都涉及到向量(Vectors),下面主要讲如何用向量来表示词。
语义词典资源很棒但是可能在一些细微之处有缺失,例如这些同义词准确吗:adept, expert, good, practiced, proficient,skillful?
新词缺失(无法及时更新)
人为构建,具有一定的主观性
需要耗费大量的人力来构建
很难用来计算词与词的相似度
进行编号,ont-hot向量把每个词表示成一个|V|维(词表大小为|V|
)的向量,该向量只有特定词的编号对应的位置为1,其他位置全部为0。这种方法把每个词表示成独立的个体,无法通过one-hot向量直接到词之间的关系。解决 方法是通过一个词的上下文来表示一个词。
,然后对X进行奇异值分解得到USVT,U
的每一行对应一个词的向量表示,SVD更多信息参考这里。 共现矩阵一般分为词-文档共现矩阵和词-词共现矩阵。
,文档数量为|M|,那么词-文档共现矩阵规模为|V|×|M|,矩阵元素Xij
表示词i在文 档j中的出现次数,只要对所有文档循环一次就可以统计得到该矩阵
表示两个词的共现次数,X是一个|V|×|V|
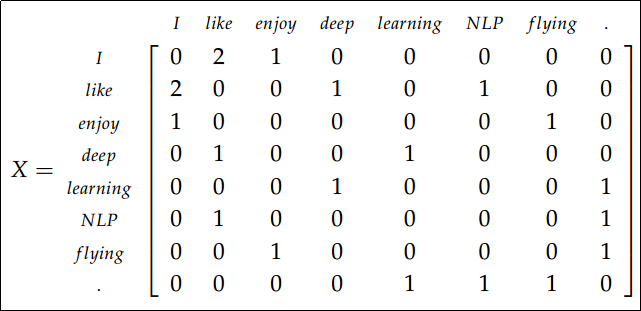
的方阵。窗口一般是对称的,长度一般为 5-10。下面举一个简单的例子,例子中窗口大小为1,语料如下:
I enjoy flying.
I like NLP.
I like deep learning.
得到共现矩阵如下:
对该矩阵进行SVD分解:
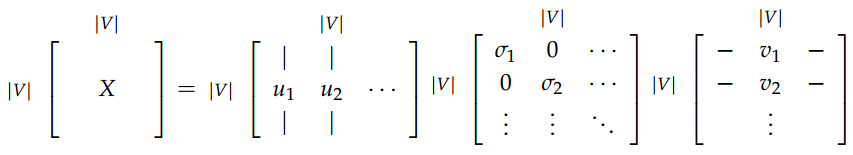
之后区U
的前k列作为所有单词的k
维向量表示。

这种基于共现矩阵进行SVD分解的方法存在问题:
矩阵的维度经常发生变化(新词和新文档的加入)
矩阵非常稀疏
矩阵过大
SVD分解的计算复杂度大,对于n×m
的矩阵进行分解的复杂度为O(mn2)
需要对X
矩阵进行一些修正来修复词频分布不均匀问题
对X
矩阵的一些修正:
功能词(the, he, has)过于频繁,对语法有很大影响,解决办法是降低使用或完全忽略功能词
采用带权重的窗口,距离当前词距离越近共现权重越大
用皮尔逊相关系数代替计数,并置负数为0
表示,中心词用one-hot向量y(i)表示,CBOW中预测的中心词只有一个所以直接把输出向量表示成y
。
随机初始化两个矩阵(一般用正态分布进行初始化)W(1)∈Rn×|V|
和W(2)∈R|V|×n分别用来存储输入向量和输出向量,最后训练完每个词有两个向量,一个是当作输入时的向量,一个是当作输出时的向量。n为词向量的维度;W(1)的第i列表示词w(i)当作输入时的向量表示,记作u(i);W(2)的第j行表示词w(j)当作输出时的向量表示,记作v(j)
。利用上下文预测中心词的步骤如下:
把大小为C
的上下文用one-hot向量表示 (x(i−C),…,x(i−1),x(i+1),…,x(i+C))
把W(1)分别和2C个one-hot向量相乘,得到上下文的输入向量,例如
x(i−C)作为输入时的向量为u(i−C)=W(1)x(i−C)
将上下文中的向量进行平均h=u(i−C)+u(i−C+1)+…+u(i+C)2C
生成得分向量z=W(2)h
利用softmax函数将得分转换成概率y^=softmax(z)
我们的目标是希望预测的概率y^和真实的中心词one-hot向量y
一致
我们希望模型输出的概率分布和真实分布的尽量相似,可以利用信息论中的交叉熵来衡量两个概率分布的距离,离散情况下两个概率分布的交叉熵H(y^,y)
如下:
H(y,y^)=−∑j=1|V|yjlog(y^j)
考虑CBOW中的情况,此时y
是一个one-hot向量,假设y的第i
维为1,那么交叉熵可以简化成:
H(y,y^)=−yilog(y^i)=−log(y^i)
可以看出交叉熵的最小值为0,优化目标就是最小化交叉熵:
minJ=−logP(w(i)|w(i−C),…,w(i−1),w(i+1),…,w(i+C))=−logP(v(i)|h)=−logexp(v(i)⋅h)∑|V|j=1exp(v(j)⋅h)=−v(i)⋅h+log∑j=1|V|exp(v(j)⋅h)
由上描述可知整个模型的未知参数就是W(1)
和W(2),即对于每个输出向量v(j)和上下文中的输入向量(u(i−C),…,u(i−1),u(i+1),…,u(i+C))
求导。
首先是∂J∂v(j)
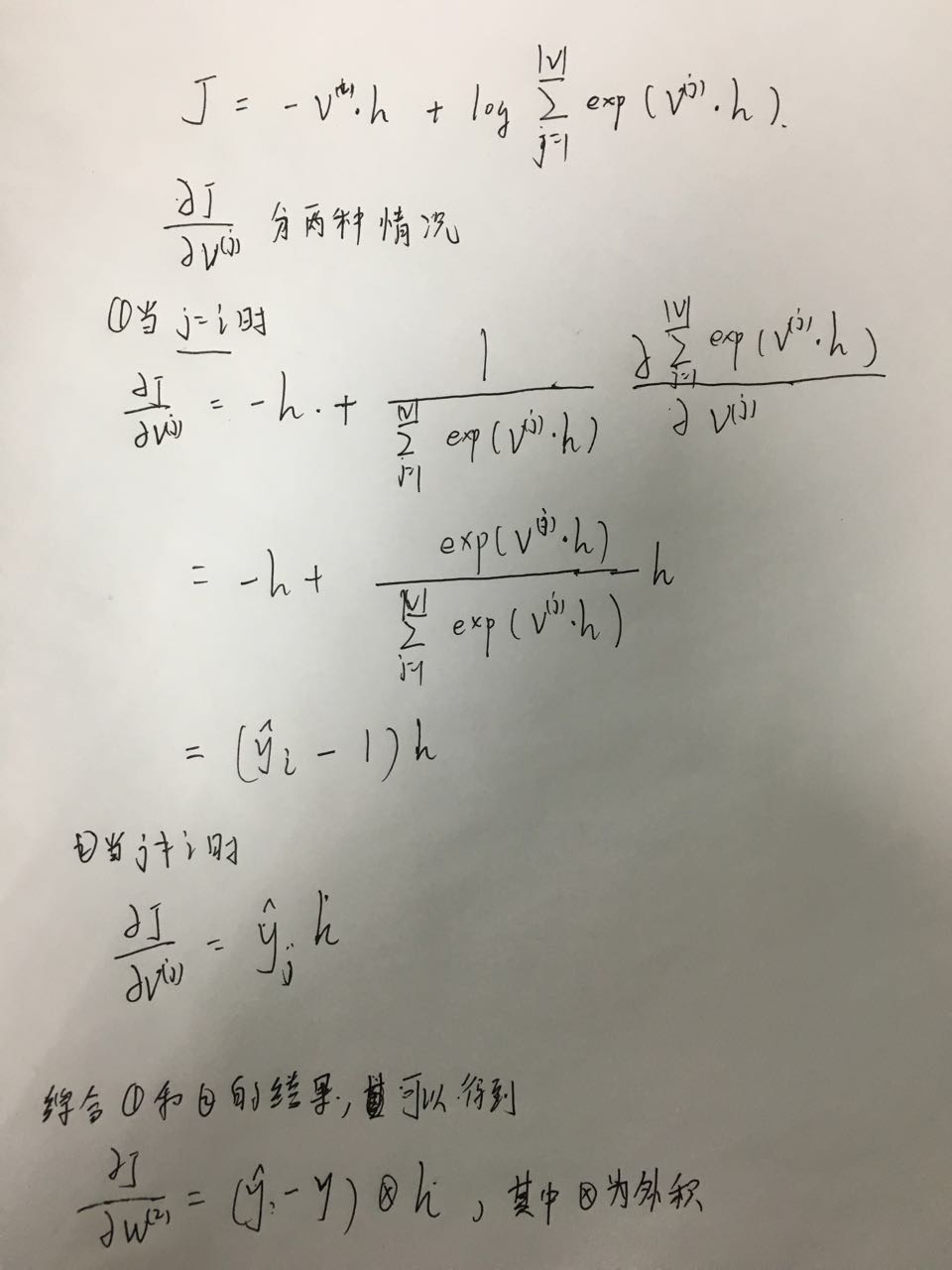
然后对窗口内的其中一个输入向量求导∂J∂u(i−C)
,其他输入向量求导方法与之相同,最后结果相等
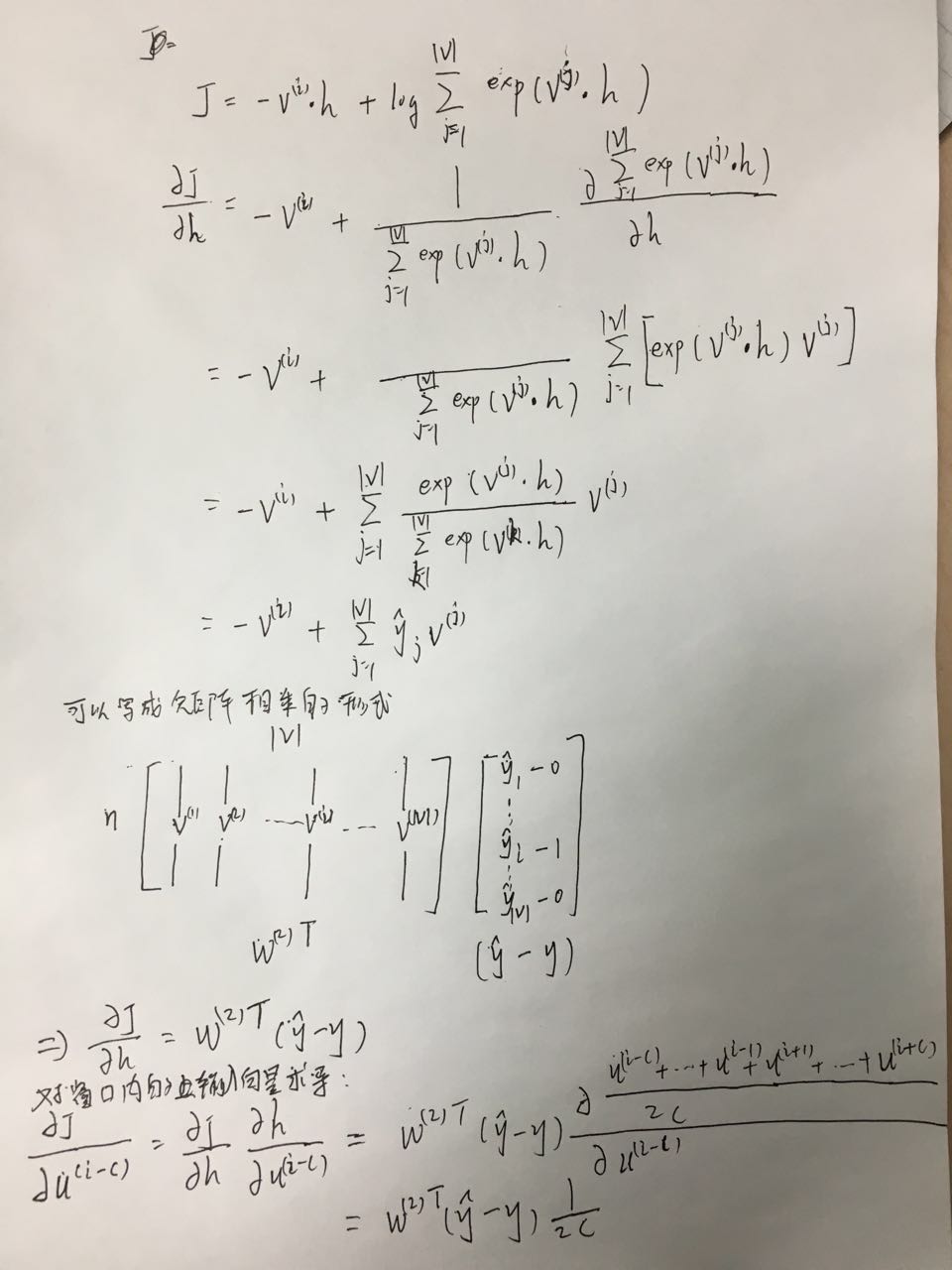
内的其他词,此时模型的输入是中心词one-hot向量x,窗口内的词one-hot向量为(y(i−C),…,y(i−1),y(i+1),…,y(i+C))
。 利用中心词预测周边词的过程如下:
输入one-hot向量为x
x的输入向量表示为u(i)=W(1)x
只有一个输入所以不需要像CBOW一样对向量进行平均,h=u(i)
生成得分向量z=W(2)h
利用softmax函数将得分转换成概率y^=softmax(z)
我们的目标是希望预测的概率y^和真实的概率(y(i−C),…,y(i−1),y(i+1),…,y(i+C))
一致
这里把P(w(i−C),…,w(i−1),w(i+1),…,w(i+C)|w(i))
整体看成一个分布, 然后用朴素贝叶斯假设来简化这个条件概率的求解,即:
minJ=−logP(w(i−C),…,w(i−1),w(i+1),…,w(i+C)|w(i))=−logΠ2Cj=0,j≠CP(w(i−C+j)|w(i))=−logΠ2Cj=0,j≠CP(v(i−C+j)|u(i))=−logΠ2Cj=0,j≠Cexp(v(i−C+j)⋅h)∑|V|k=1exp(v(k)⋅h)=−∑j=0,j≠C2Cv(i−C+j)⋅h+2Clog∑k=1|V|exp(v(k)⋅h)
对于这个损失函数我们可以先不考虑对窗口内的所有词求和,假设我们现在只针对窗口内的特定词w(j)
进行预测, 此时
J=−v(j)⋅h+log∑k=1|V|exp(v(k)⋅h)
该损失函数对于每个输出向量的导数的求解结果与CBOW类似,损失函数对于输入向量的求导结果也和CBOW类似。唯一的区别在于skip-gram的输入向量只有一个,所以J
对于u(i)的导数直接为W(2)T(y^−y)不需要除以2C
。
规模的,这个计算非常耗时,英文的词汇表规模大概是1300万。负采样是基于Skip-Gram模型,但是和优化目标和Skip-Gram不同。给定一对词(w,c),其中w是中心词,c代表w的上下文窗口内出现的另一个词,用P(D=1|w,c)表示(w,c)确实出现在语料中的概率,相应的P(D=0|w,c)表示(w,c)没有出现在语料中的概率。用sigmoid函数(下文用σ表示sigmoid函数)来表示P(D=1|w,c)这个概率,这里用vc表示输出向量,uw
表示输入向量。
P(D=1|w,c,θ)=11+exp(−vTcuw)
我们期望优化的目标是希望真实存在语料中(w,c)
对P(D=1|w,c)最大化,同时不存在语料中的(w,c)对P(D=0|w,c)概率最大化,公式中的θ包括了上面提到的两个矩阵W(1)和W(2),我们希望θ满足下列公式:
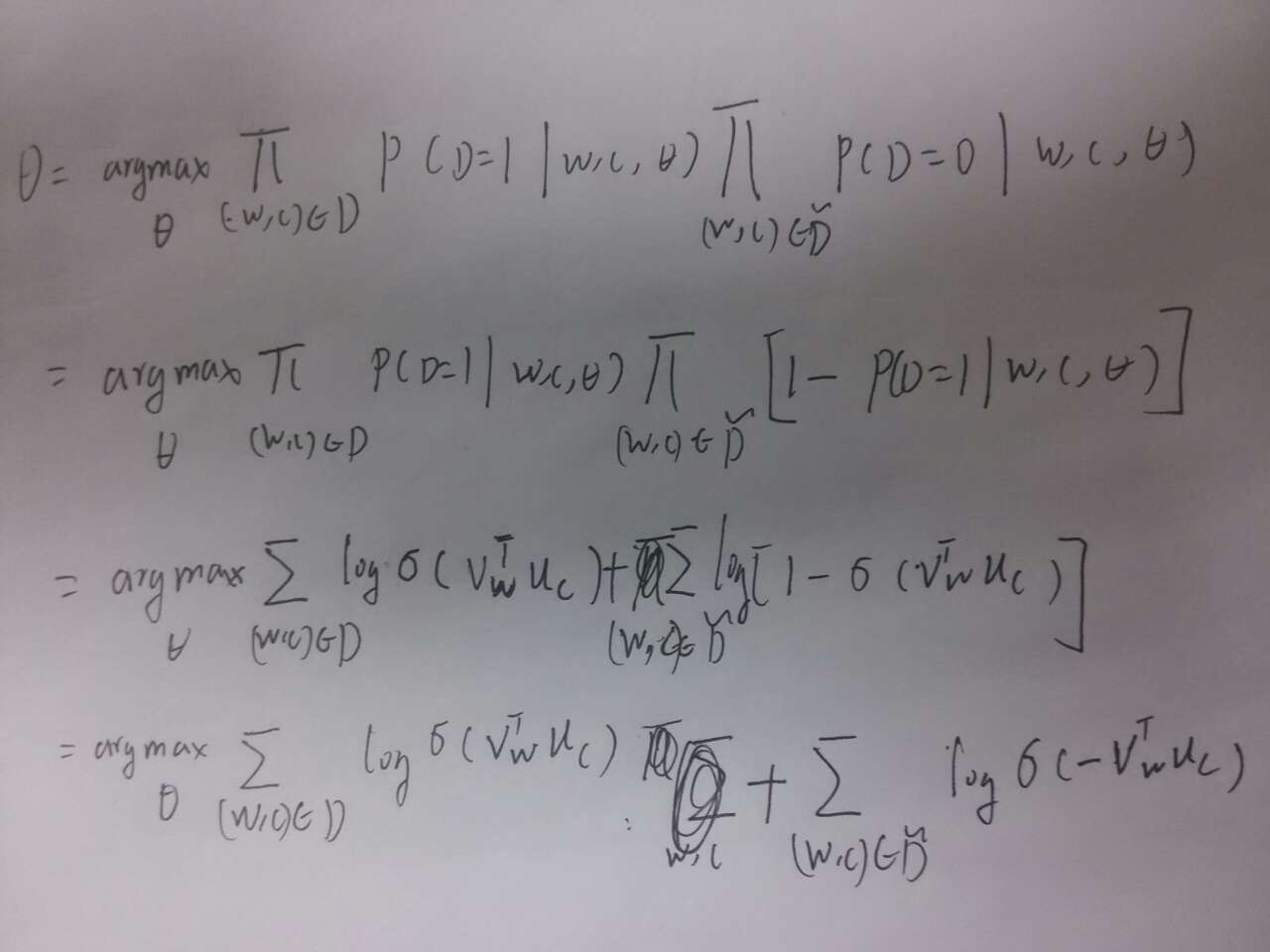
上述推导中用到需要用到了一个等式1−σ(x)=σ(−x),这个等式比较好验证,其中D~
为负样本。由此可得新的 目标函数
minJ=−logσ(vTcuw)−∑k=1Klogσ(−vTkuw)
在这个目标函数中vk
是从Pn(w)从采样出来的,这个Pn(w)是unigram概率U(w)的3/4
次方, 这样可以增大一些概率很小的词被采样出来的概率。
可以求得∂J∂uw
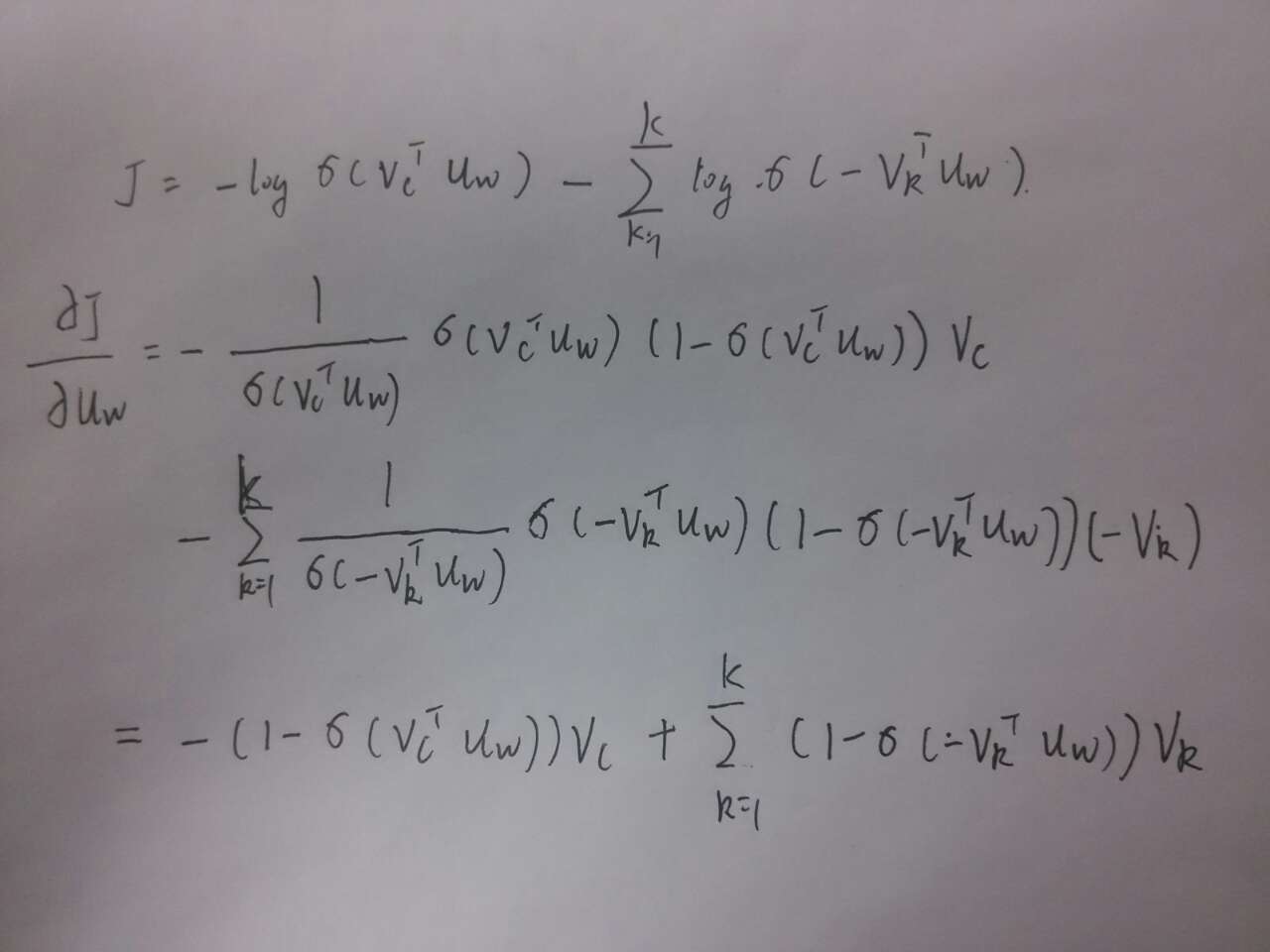
然后是J
对相关的输出向量求导
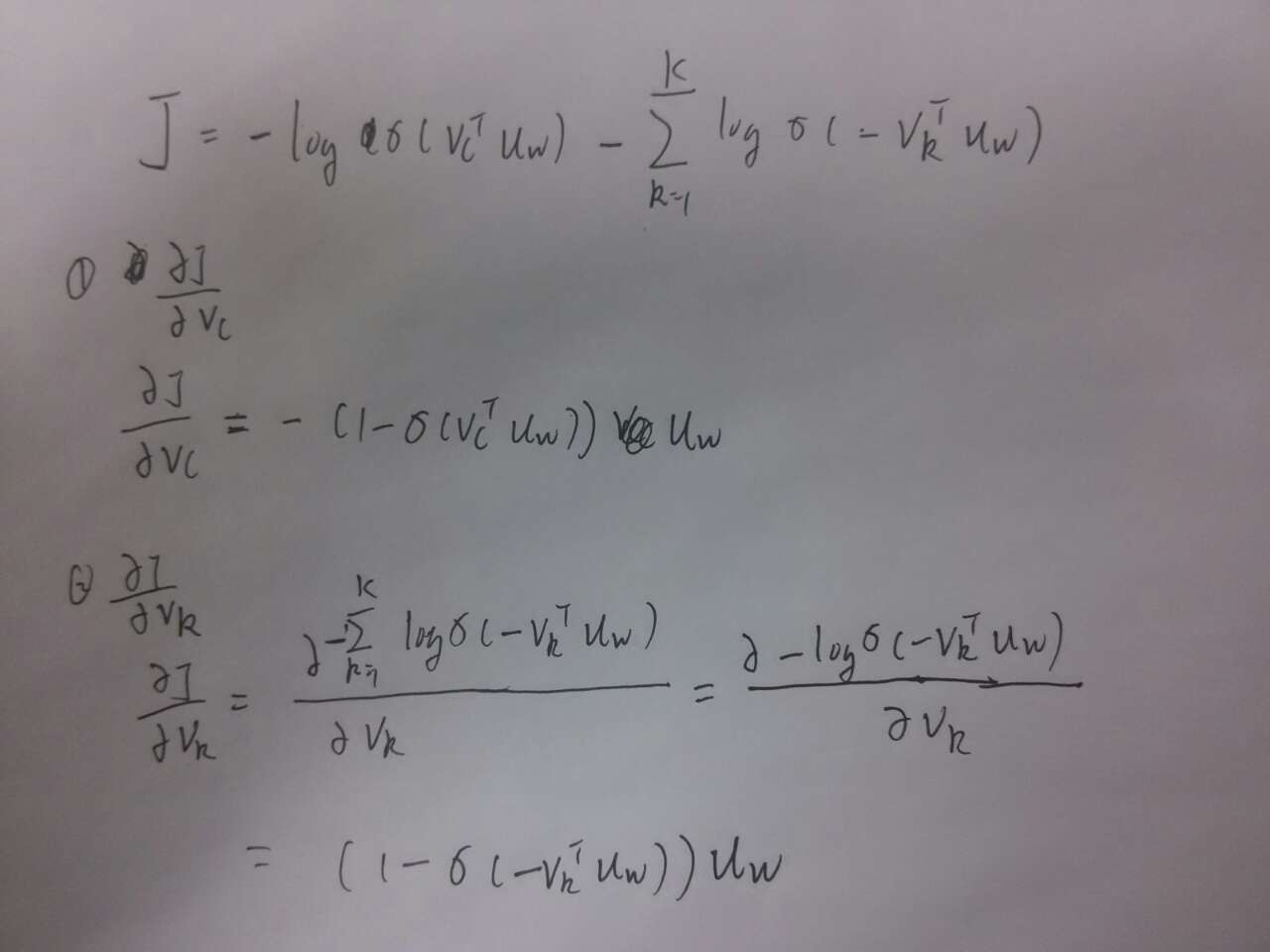
求得梯度之后可以采用随机梯度下降优化目标函数,得到向量表示。上述三种方法训练完成之后对于每个词都会得到两个向量,一个是作为模型输入时的向量,一个是作为模型输出时的向量,最后的向量表示是把这两种向量相加使用,即对于词w(i)
的向量为v(i)+u(i)
。
内部评测:
在一个特定的子任务中进行评测
计算迅速
有助于理解相关的系统
不太清楚是否有助于真实任务除非和实际的NLP任务的相关性已经建立起来
外部评测:
在一个真实任务中进行评测
需要花很长的实际来计算精度
不太清楚是否是这个子系统或者其他子系统引起的问题
如果用这个子系统替换原有的系统后获得精度提升–>有效(Winning!)
词向量类比的基本思想如下

目前评测的数据集主要是word2vec项目提供的数据集包含了语义类比和语法类比两种。语义类比的数据有州名包含城市名、首都和国家, 语法类比的数据是比较级类比和时态类比。
词向量相关度的数据集例如WordSim353,该数据集是人为地给两个词的相关度打分(从0-10),然后通过计算词向量的Cosine相似度与 这个相关度进行对比。
为什么需要深度学习
传统的机器学习方法都是认为的设计特征或者表示,深度学习的目的是希望能够通过神经网络让机器自动学习到有效的特征表示,这里所说的深度学习更偏向于关注各种类型的神经网络。探索机器学习的原因主要有以下几方面:人工设计的特征常常定义过多,不完整并且需要花费大量的时间去设计和验证
自动学习的特征容易自适应,并且可以很快的学习
深度学习提供了一个弹性的,通用的学习框架用来表征自然的,视觉的和语言的信息。
深度学习可以用来学习非监督的(来自于生文本)和有监督的(带有特别标记的文本, 例如正向和负向标记)
在2006年深度学习技术开始在一些任务中表现出众,为什么现在才热起来?
深度学习技术受益于越来越多的数据
更快的机器与更多核CPU/GPU对深度学习的普及起了很大的促进作用
新的模型,算法和idea层出不穷
通过深度学习技术提升效果首先发生在语音识别和机器视觉领域,然后开始过渡到NLP领 域
深度学习在所有的NLP层次(音素、形态学、句法、语义)都得到了应用,在所有的NLP层 次的表示都涉及到向量(Vectors),下面主要讲如何用向量来表示词。
词向量
在传统意义上会使用WordNet来表示词的含义,通过WordNet可以查询词之间的上下位关系、一个词的同义词、度量词之间的相似度等。但是WordNet是由人工维护,存在 一些问题:语义词典资源很棒但是可能在一些细微之处有缺失,例如这些同义词准确吗:adept, expert, good, practiced, proficient,skillful?
新词缺失(无法及时更新)
人为构建,具有一定的主观性
需要耗费大量的人力来构建
很难用来计算词与词的相似度
One-hot向量
首先我们把词表中的词从0到|V|−1进行编号,ont-hot向量把每个词表示成一个|V|维(词表大小为|V|
)的向量,该向量只有特定词的编号对应的位置为1,其他位置全部为0。这种方法把每个词表示成独立的个体,无法通过one-hot向量直接到词之间的关系。解决 方法是通过一个词的上下文来表示一个词。
基于SVD分解的方法
这种方法的基本思想是通过大量的数据统计到词的累计共现矩阵X,然后对X进行奇异值分解得到USVT,U
的每一行对应一个词的向量表示,SVD更多信息参考这里。 共现矩阵一般分为词-文档共现矩阵和词-词共现矩阵。
词-文档共现矩阵
这种共现矩阵的思想认为相关的词会出现在同一个文档中。假设词表大小为|V|,文档数量为|M|,那么词-文档共现矩阵规模为|V|×|M|,矩阵元素Xij
表示词i在文 档j中的出现次数,只要对所有文档循环一次就可以统计得到该矩阵
词-词共现矩阵
词-词共现矩阵的思想是词i的窗口内出现了j,那么认为i和j的共现次数加一,Xij表示两个词的共现次数,X是一个|V|×|V|
的方阵。窗口一般是对称的,长度一般为 5-10。下面举一个简单的例子,例子中窗口大小为1,语料如下:
I enjoy flying.
I like NLP.
I like deep learning.
得到共现矩阵如下:
对该矩阵进行SVD分解:
之后区U
的前k列作为所有单词的k
维向量表示。
这种基于共现矩阵进行SVD分解的方法存在问题:
矩阵的维度经常发生变化(新词和新文档的加入)
矩阵非常稀疏
矩阵过大
SVD分解的计算复杂度大,对于n×m
的矩阵进行分解的复杂度为O(mn2)
需要对X
矩阵进行一些修正来修复词频分布不均匀问题
对X
矩阵的一些修正:
功能词(the, he, has)过于频繁,对语法有很大影响,解决办法是降低使用或完全忽略功能词
采用带权重的窗口,距离当前词距离越近共现权重越大
用皮尔逊相关系数代替计数,并置负数为0
Word2vec
Word2vec的基本思想与共现计数不同,word2vec主要分为两种,采用当前词来预测窗口中 的其他词(skip-gram),另一种是用窗口中的词来预测当前词(cbow)。CBOW
CBOW(Continuous Bag of Words)的基本思想是用窗口中的词的向量求平均之后来预测中心词。训练语料是上下文和对应的中心词的对,上下文窗口内的每个词都用一个one-hot向量x(i)表示,中心词用one-hot向量y(i)表示,CBOW中预测的中心词只有一个所以直接把输出向量表示成y
。
随机初始化两个矩阵(一般用正态分布进行初始化)W(1)∈Rn×|V|
和W(2)∈R|V|×n分别用来存储输入向量和输出向量,最后训练完每个词有两个向量,一个是当作输入时的向量,一个是当作输出时的向量。n为词向量的维度;W(1)的第i列表示词w(i)当作输入时的向量表示,记作u(i);W(2)的第j行表示词w(j)当作输出时的向量表示,记作v(j)
。利用上下文预测中心词的步骤如下:
把大小为C
的上下文用one-hot向量表示 (x(i−C),…,x(i−1),x(i+1),…,x(i+C))
把W(1)分别和2C个one-hot向量相乘,得到上下文的输入向量,例如
x(i−C)作为输入时的向量为u(i−C)=W(1)x(i−C)
将上下文中的向量进行平均h=u(i−C)+u(i−C+1)+…+u(i+C)2C
生成得分向量z=W(2)h
利用softmax函数将得分转换成概率y^=softmax(z)
我们的目标是希望预测的概率y^和真实的中心词one-hot向量y
一致
我们希望模型输出的概率分布和真实分布的尽量相似,可以利用信息论中的交叉熵来衡量两个概率分布的距离,离散情况下两个概率分布的交叉熵H(y^,y)
如下:
H(y,y^)=−∑j=1|V|yjlog(y^j)
考虑CBOW中的情况,此时y
是一个one-hot向量,假设y的第i
维为1,那么交叉熵可以简化成:
H(y,y^)=−yilog(y^i)=−log(y^i)
可以看出交叉熵的最小值为0,优化目标就是最小化交叉熵:
minJ=−logP(w(i)|w(i−C),…,w(i−1),w(i+1),…,w(i+C))=−logP(v(i)|h)=−logexp(v(i)⋅h)∑|V|j=1exp(v(j)⋅h)=−v(i)⋅h+log∑j=1|V|exp(v(j)⋅h)
由上描述可知整个模型的未知参数就是W(1)
和W(2),即对于每个输出向量v(j)和上下文中的输入向量(u(i−C),…,u(i−1),u(i+1),…,u(i+C))
求导。
首先是∂J∂v(j)
然后对窗口内的其中一个输入向量求导∂J∂u(i−C)
,其他输入向量求导方法与之相同,最后结果相等
Skip-Gram
Skip-Gram的基本思想用当前词预测窗口长度为C内的其他词,此时模型的输入是中心词one-hot向量x,窗口内的词one-hot向量为(y(i−C),…,y(i−1),y(i+1),…,y(i+C))
。 利用中心词预测周边词的过程如下:
输入one-hot向量为x
x的输入向量表示为u(i)=W(1)x
只有一个输入所以不需要像CBOW一样对向量进行平均,h=u(i)
生成得分向量z=W(2)h
利用softmax函数将得分转换成概率y^=softmax(z)
我们的目标是希望预测的概率y^和真实的概率(y(i−C),…,y(i−1),y(i+1),…,y(i+C))
一致
这里把P(w(i−C),…,w(i−1),w(i+1),…,w(i+C)|w(i))
整体看成一个分布, 然后用朴素贝叶斯假设来简化这个条件概率的求解,即:
minJ=−logP(w(i−C),…,w(i−1),w(i+1),…,w(i+C)|w(i))=−logΠ2Cj=0,j≠CP(w(i−C+j)|w(i))=−logΠ2Cj=0,j≠CP(v(i−C+j)|u(i))=−logΠ2Cj=0,j≠Cexp(v(i−C+j)⋅h)∑|V|k=1exp(v(k)⋅h)=−∑j=0,j≠C2Cv(i−C+j)⋅h+2Clog∑k=1|V|exp(v(k)⋅h)
对于这个损失函数我们可以先不考虑对窗口内的所有词求和,假设我们现在只针对窗口内的特定词w(j)
进行预测, 此时
J=−v(j)⋅h+log∑k=1|V|exp(v(k)⋅h)
该损失函数对于每个输出向量的导数的求解结果与CBOW类似,损失函数对于输入向量的求导结果也和CBOW类似。唯一的区别在于skip-gram的输入向量只有一个,所以J
对于u(i)的导数直接为W(2)T(y^−y)不需要除以2C
。
负采样
上述的CBOW和Skip-Gram模型都存在一个问题,就是损失函数都有一个求和是|V|规模的,这个计算非常耗时,英文的词汇表规模大概是1300万。负采样是基于Skip-Gram模型,但是和优化目标和Skip-Gram不同。给定一对词(w,c),其中w是中心词,c代表w的上下文窗口内出现的另一个词,用P(D=1|w,c)表示(w,c)确实出现在语料中的概率,相应的P(D=0|w,c)表示(w,c)没有出现在语料中的概率。用sigmoid函数(下文用σ表示sigmoid函数)来表示P(D=1|w,c)这个概率,这里用vc表示输出向量,uw
表示输入向量。
P(D=1|w,c,θ)=11+exp(−vTcuw)
我们期望优化的目标是希望真实存在语料中(w,c)
对P(D=1|w,c)最大化,同时不存在语料中的(w,c)对P(D=0|w,c)概率最大化,公式中的θ包括了上面提到的两个矩阵W(1)和W(2),我们希望θ满足下列公式:
上述推导中用到需要用到了一个等式1−σ(x)=σ(−x),这个等式比较好验证,其中D~
为负样本。由此可得新的 目标函数
minJ=−logσ(vTcuw)−∑k=1Klogσ(−vTkuw)
在这个目标函数中vk
是从Pn(w)从采样出来的,这个Pn(w)是unigram概率U(w)的3/4
次方, 这样可以增大一些概率很小的词被采样出来的概率。
可以求得∂J∂uw
然后是J
对相关的输出向量求导
求得梯度之后可以采用随机梯度下降优化目标函数,得到向量表示。上述三种方法训练完成之后对于每个词都会得到两个向量,一个是作为模型输入时的向量,一个是作为模型输出时的向量,最后的向量表示是把这两种向量相加使用,即对于词w(i)
的向量为v(i)+u(i)
。
词向量评测
词向量的评测方法可以分为内部(intrinsic)评测和外部(extrinsic)评测,两种评测的对比如下:内部评测:
在一个特定的子任务中进行评测
计算迅速
有助于理解相关的系统
不太清楚是否有助于真实任务除非和实际的NLP任务的相关性已经建立起来
外部评测:
在一个真实任务中进行评测
需要花很长的实际来计算精度
不太清楚是否是这个子系统或者其他子系统引起的问题
如果用这个子系统替换原有的系统后获得精度提升–>有效(Winning!)
词向量内部评测方法
词向量内部评测方法主要有词向量类比、词向量相关度,这两种方法有相应的数据集。词向量类比的基本思想如下
目前评测的数据集主要是word2vec项目提供的数据集包含了语义类比和语法类比两种。语义类比的数据有州名包含城市名、首都和国家, 语法类比的数据是比较级类比和时态类比。
词向量相关度的数据集例如WordSim353,该数据集是人为地给两个词的相关度打分(从0-10),然后通过计算词向量的Cosine相似度与 这个相关度进行对比。
词向量外部评测方法
简单来说就是把词向量应用于具体的任务中来评测不同的词向量对于任务整体性能的影响。这里需要注意的问题是,应用于具体任务的时候是否还需要调整词向量, 一般来说调整词向量会降低向量的范化能力。所以一般具体任务的训练集足够大时才考虑调整词向量。
相关文章推荐
- 在命令行中运行eclipse中创建的java项目
- 使用Jquery.cookie实现cookie
- java 打包过程及如何使用第三方jar包
- NSKeyedArchiver归档
- yii下面如何实现文件上传
- U盘启动安装WIN7(包含资源的地址)
- MBProgressHUD 动画
- 使用 ObjectDataSource 缓存数据
- 基于JDBC封装的BaseDao(实例代码)
- node.js中的http.response.writeHead方法
- 夜神云手机技术正式发布,App试玩时代开启
- 标记 mac使用tree
- UVA 315 无向图 求割点
- Android点击两次返回键退出
- React-native ListView不滚动
- TreeMap利用Comparator接口排序
- jar包与lib包的区别
- hdu 5510 -Bazinga(kmp)
- Ubuntu查看内存条信息
- 在office中嵌入mathtype