hadoop——压缩和本地库
2016-07-12 15:38
190 查看
为什么经常把hadoop的本地库和压缩一起说,原来hadoop是使用Java语言开发的,但是一些需求和操作并不适合使用java(性能问题)或某些java类库的缺失,所以就引入了本地库(c/c++编写)的概念,而压缩的一些格式就正好需要使用本地库。
hadoop中常用到的压缩格式有lzo,lz4,gzip,snappy,bzip2,关于这几种压缩格式的比较如下表
详细参考来源: http://www.linuxidc.com/Linux/2014-05/101230.htm
下表给出了每种压缩格式的java内置实现和原生库实现
可以使用hadoop checknative查看本地库的安装情况,截图显示已安装
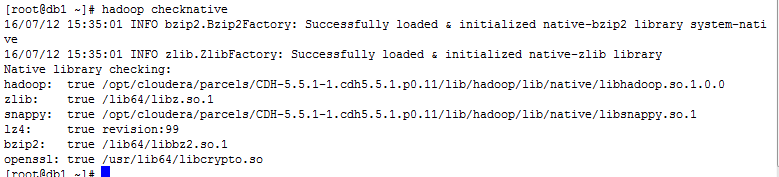
以上待续…
1. 压缩
hadoop中为什么使用压缩,因为压缩既减少了占用磁盘的空间又加快了文件的传输速度。hadoop中常用到的压缩格式有lzo,lz4,gzip,snappy,bzip2,关于这几种压缩格式的比较如下表
| 压缩格式 | 文件扩展名 | 是否可切分(split) | native | 压缩率 | 速度 | 是否hadoop自带 | linux命令 | 换成压缩格式后,原来的应用程序是否要修改 |
|---|---|---|---|---|---|---|---|---|
| gzip | .gz | 否 | 是 | 很高 | 比较快 | 是 | 有 | 和文本处理一样,不需要修改 |
| lzo | .lzo | 是 | 是 | 比较高 | 很快 | 否,需要安装 | 有 | 需要建索引,还需要指定输入格式 |
| snappy | .snappy | 否 | 是 | 比较高 | 很快 | 否,需要安装 | 没有 | 和文本处理一样,不需要修改 |
| bzip2 | .bz2 | 是 | 否 | 最高 | 慢 | 是 | 有 | 和文本处理一样,不需要修改 |
hadoop中的codec实现了压缩-解压缩算法
| 压缩格式 | 对应的压缩-解压缩处理类 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
实际使用举例:
按小时收集服务器日志,并且清洗数据后输出。解决方案:
因为日志格式是文本文档且量大,所以收集后采用压缩率最高但是速度比较慢的bzip2格式压缩存储,并且bzip2格式压缩支持对输入文件的分片(虽然我们的数据还没到需要分片的地步),在MR执行任务时,会在读取时自动解压缩文件;同时可以对map任务的输出和reduce的输出做bzip2格式的压缩处理。2. 本地库(Native Libraries)
压缩使用native库往往比使用内置java实现压缩解压缩速度快。默认情况下,hadoop会搜索本地库,如果找到就会自动加载,但通常本地库因为版本的原因需要重新安装编译,所以如果使用gzip/LZO/Snappy格式之前需要安装相应库。下表给出了每种压缩格式的java内置实现和原生库实现
| 压缩格式 | 是否hadoop自带java实现 | 是否有原生实现 |
|---|---|---|
| DEFLATE | 是 | 是 |
| gzip | 是 | 是 |
| bzip2 | 是 | 否 |
| LZO | 否 | 是 |
| LZ4 | 否 | 是 |
| Snappy | 否 | 是 |
以上待续…

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- 如何在 Ubuntu Linux 中使用 RAR 文件
- C#使用DeflateStream解压缩数据文件的方法
- C# 利用ICSharpCode.SharpZipLib实现在线压缩和解压缩
- C#使用WinRar命令进行压缩和解压缩操作的实现方法
- C#调用WinRar执行rar、zip压缩的方法
- C语言压缩文件和用MD5算法校验文件完整性的实例教程
- hadoop常见错误以及处理方法详解
- C#实现页面GZip或Deflate压缩的方法
- C#使用iCSharpcode进行文件压缩实现方法
- C#图片切割、图片压缩、缩略图生成代码汇总
- C#实现压缩HTML代码的方法
- Asp.net在线备份、压缩和修复Access数据库示例代码
- 使用UglifyJS合并/压缩JavaScript的方法
- 高性能WEB开发 JS、CSS的合并、压缩、缓存管理
- 脚本分析、压缩、混淆工具 JSA新版本发布,压缩效率提高大约10%
- 发布一个高效的JavaScript分析、压缩工具 JavaScript Analyser