搭建企业级大数据分析平台也可以很简单!
2016-07-12 10:27
525 查看
对于大数据分析平台的建设,往往不是某个产品就能够满足,而是需要多种不同的产品一起搭建。例如,搭建大数据平台需要大规模数据存储平台,需要数据处理和挖掘工具,分析结果需要通过展现工具体现大数据分析的价值。所以,没有一个完善的BigData生态系统,大数据分析平台是搭建不起来的。
IBM作为大数据分析领域的领导者,有着其他厂商或开源无法比拟的完整BigData生态系统。下面然让我们来看看这个生态系统包括哪些产品。
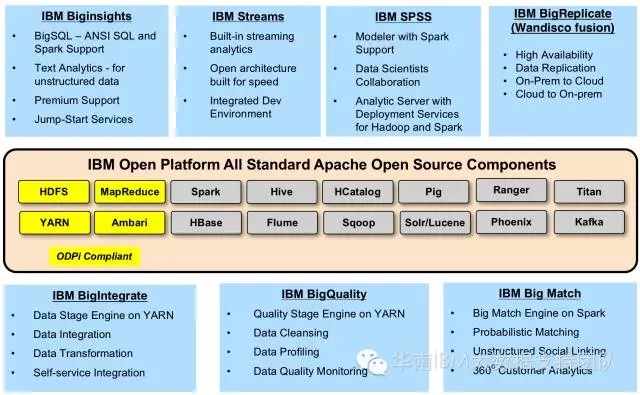
IBM Open Platform with Apache Hadoop
IOP是IBM遵循Open Data Platform Initiative 联盟标准构建,以开源技术为核心的产品包。所包含的内容100%开源,包括HDFS、Spark、HBase、Kafka等。用户如果想使用IOP,完全可以免费下载和使用,包括在生产环境上使用。在免费使用的基础上,IBM还提供了有偿的技术支持。

IBM BigInsights
IBM BigInsights 是实现IBM大数据战略的重要旗舰产品,它包含了开源部分-即IOP,和增值部分。BigInsights增值部分则包括了BigSQL-业界最先进、最成熟的SQL on Hadoop引擎,Text Analytics-基于拖拽的文本分析工具,Big Sheet -类似电子表格的数据处理工具,BigR -适合在分布式平台运行的R改进版本等高级功能。

IBM Streams
IBM Streams
是一个高级流计算平台,帮助用户开发的应用程序快速摄取、分析和关联来自数千个实时源的信息。它可处理非常高的数据吞吐率,最高可达每秒数百万个事件或消息。Streams 旨在从一个几分钟到几小时的窗口中的移动信息(数据流)中揭示有意义的模式。该平台能够获取低延迟洞察,并为注重时效的应用程序(比如欺诈检测或网络管理)获取更好的成果,从而提供业务价值。

IBM SPSS
我们常说的SPSS包含SPSS Modeler 和SPSS Analytic Server。SPSS Modeler是一款数据挖掘分析的行业软件,其采用数据流的方式来展示数据挖掘的操作过程,并结合CRISP-DM 工业标准打造了一个支持众多数据挖掘操作的应用平台。SPSS Analytic Server是大数据分析的解决方案,它提供了一个易于实现的框架,从而能够在分布式文件系统上来执行大数据分析。它将IBM
SPSS 现有的商业分析技术与大数据技术相结合,使得用户能够使用复杂的分析算法以高可伸缩的方式来解决基于大数据的分析问题。

IBM Big Replicate
Big Replicate集成了Wandisco Fusion技术,为Hadoop集群实现数据复制和高可用方案。BigReplicate为跨任意距离的Hadoop集群提供了单一虚拟命名空间,从而打破信息孤岛,实现Hadoop集群之间的自由、灵活数据复制。

IBM Big Integrate
Big Integrate是IBM InfoSphere Information Server(DataStage)的Hadoop版本,为大数据平台提供企业级ETL方案。

IBM BigQuality
BigQuality采用Data Quality 引擎,为Hadoop环境提供数据分析、清洗和数据质量监控的功能。

IBM Big Match
Big Match使用IBM InfoSphere MDM的相同算法,帮助用户解决Hadoop环境中跨非结构化和结构化数据的客户身份匹配的挑战。

结束语
IBM 提供了企业级Hadoop方案-BigInsights,而且提供了完善的生态系统,为用户建设大数据平台提供完整的产品支持。
下面给大家提供一个Biginsights试用链接,感兴趣的朋友可以尝试一下:
http://bigdata.evget.com/product/385.html
IBM作为大数据分析领域的领导者,有着其他厂商或开源无法比拟的完整BigData生态系统。下面然让我们来看看这个生态系统包括哪些产品。
IBM Open Platform with Apache Hadoop
IOP是IBM遵循Open Data Platform Initiative 联盟标准构建,以开源技术为核心的产品包。所包含的内容100%开源,包括HDFS、Spark、HBase、Kafka等。用户如果想使用IOP,完全可以免费下载和使用,包括在生产环境上使用。在免费使用的基础上,IBM还提供了有偿的技术支持。
IBM BigInsights
IBM BigInsights 是实现IBM大数据战略的重要旗舰产品,它包含了开源部分-即IOP,和增值部分。BigInsights增值部分则包括了BigSQL-业界最先进、最成熟的SQL on Hadoop引擎,Text Analytics-基于拖拽的文本分析工具,Big Sheet -类似电子表格的数据处理工具,BigR -适合在分布式平台运行的R改进版本等高级功能。
IBM Streams
IBM Streams
是一个高级流计算平台,帮助用户开发的应用程序快速摄取、分析和关联来自数千个实时源的信息。它可处理非常高的数据吞吐率,最高可达每秒数百万个事件或消息。Streams 旨在从一个几分钟到几小时的窗口中的移动信息(数据流)中揭示有意义的模式。该平台能够获取低延迟洞察,并为注重时效的应用程序(比如欺诈检测或网络管理)获取更好的成果,从而提供业务价值。
IBM SPSS
我们常说的SPSS包含SPSS Modeler 和SPSS Analytic Server。SPSS Modeler是一款数据挖掘分析的行业软件,其采用数据流的方式来展示数据挖掘的操作过程,并结合CRISP-DM 工业标准打造了一个支持众多数据挖掘操作的应用平台。SPSS Analytic Server是大数据分析的解决方案,它提供了一个易于实现的框架,从而能够在分布式文件系统上来执行大数据分析。它将IBM
SPSS 现有的商业分析技术与大数据技术相结合,使得用户能够使用复杂的分析算法以高可伸缩的方式来解决基于大数据的分析问题。
IBM Big Replicate
Big Replicate集成了Wandisco Fusion技术,为Hadoop集群实现数据复制和高可用方案。BigReplicate为跨任意距离的Hadoop集群提供了单一虚拟命名空间,从而打破信息孤岛,实现Hadoop集群之间的自由、灵活数据复制。
IBM Big Integrate
Big Integrate是IBM InfoSphere Information Server(DataStage)的Hadoop版本,为大数据平台提供企业级ETL方案。
IBM BigQuality
BigQuality采用Data Quality 引擎,为Hadoop环境提供数据分析、清洗和数据质量监控的功能。
IBM Big Match
Big Match使用IBM InfoSphere MDM的相同算法,帮助用户解决Hadoop环境中跨非结构化和结构化数据的客户身份匹配的挑战。
结束语
IBM 提供了企业级Hadoop方案-BigInsights,而且提供了完善的生态系统,为用户建设大数据平台提供完整的产品支持。
下面给大家提供一个Biginsights试用链接,感兴趣的朋友可以尝试一下:
http://bigdata.evget.com/product/385.html

相关文章推荐
- email 发送邮箱修改密码
- HDFS
- 大数据
- linker command failed with exit code 1 (use -v to see invocation)
- 新浪云计算SAE部署代码过程
- 【打CF,学算法——二星级】Codeforces 22B Bargaining Table(区域和)
- Installation error: INSTALL_FAILED_UPDATE_INCOMPATIBLE解决方法
- [Cloud Computing]Mechanisms: Failover System
- 如何在简历中编写Spark大数据项目经验
- saiku2.x刷新缓存的方法
- Mybaits深入了解(三)----mybatis开发Dao的方法
- 自定义Canvas
- paint Canvas画笔、画布
- Web QQ API 分析
- HDU2057 A + B Again
- LeetCode 217. Contains Duplicate
- codeforces 690C3 C3. Brain Network (hard)(lca)
- Paint之函数大汇总
- codeforces 690C2 C2. Brain Network (medium)(bfs+树的直径)
- 【转】session setup failed: NT_STATUS_LOGON_FAILURE -- 不错