基于Scrapy框架的python网络爬虫(1)
2016-07-08 17:27
344 查看
1、搭建环境
这里我使用的是anaconda,anaconda里面集成了很多关于python科学计算的第三方库,主要是安装方便,anaconda中自带Spyder。这里下载anaconda
比较推荐使用Python2.7
在anaconda下安装Scrapy也很简单!CMD进入命令行,直接输入conda install scrapy,然后点“y”,很简单就可以安装成功。
这样就搭建好了环境。
2、初步了解Scrapy
Scrapy官网教程,建议看看哦首先应该解决的是如何创建一个新的scrapy项目
从命令行进入要创建新项目的目录下,scrapy startproject newone
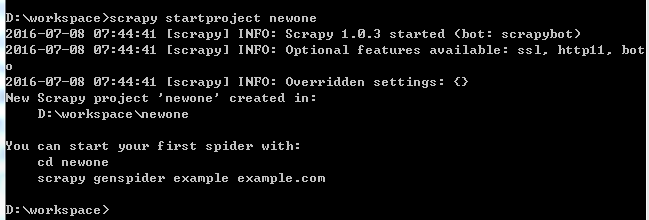
打开目录即可看到一个新的文件夹,打开文件夹可以看到:
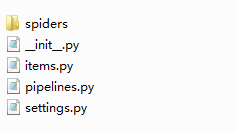
其中,items.py中的items作为加载所爬取数据的容器,它的结构像Python中的字典一样。打开你的items.py可以看到如下代码:
name = scrapy.Field()就是一个典型的item,用来作为所爬取的name项的容器
class NewoneItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
介绍了存储爬取数据的容器,那么怎么爬取数据呢。在这之前我们需要一些XPath的知识
XPath教程
举一些简单的小例子来看一下XPath的用法:
/html/head/title 选择目录HTML下head元素下的title元素
/html/head/title/text() 选择title元素的文本内容
//td 选择所有的td元素
//div[@class=”mine”] 选择所有属性class=”mine”的div元素
为了方便使用XPaths,Scrapy提供Selector 类,在Scrapy里面,Selectors 有四种基础的方法:
xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
extract():返回一个unicode字符串,为选中的数据
re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
通过一个实际的例子更深刻的了解一下吧!
使用下面这个网站来作为示例
http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
使用shell爬取网页来观察XPath的功能
在命令行中输入:
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
在Shell载入后,你将获得response回应,存储在本地变量 response中。
所以如果你输入response.body,你将会看到response的body部分,也就是抓取到的页面内容:
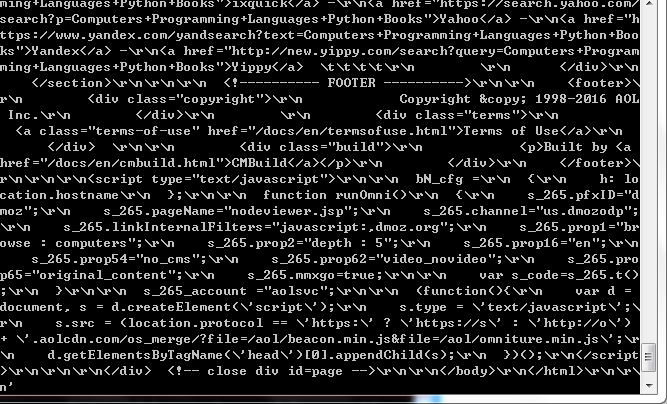
类似的可以输入response.headers:
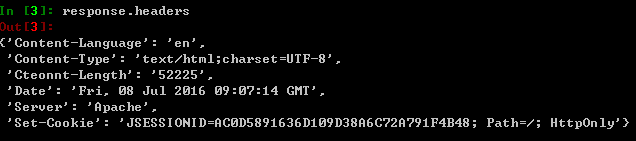
接下来观察一下网页:
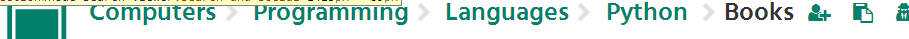
我们来爬取Computers,Programming,Languages,Python这几个元素,在浏览器上右键审查元素来观察这段HTML代码。
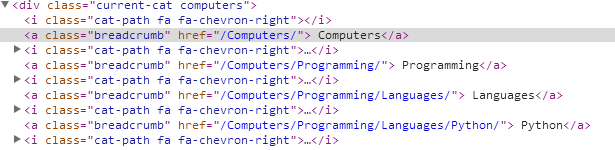
根据这段代码写出
sel.xpath('//a[@class="breadcrumb"]/text()').extract()其中sel是selector对象

xpath很灵活,可以用不同的写法得出相同结果。
接下来需要来写实际爬取数据的代码,我们可以通过实际例子来学习,敬请期待ing

相关文章推荐
- 用tcpdump抓取Android的网络数据包
- HTTP协议的响应头,请求头详解
- ios 网络通信过程cookie的使用
- 用Wininet以Https的post方式登录
- C#Wince加载网络图片
- Google语音搜索在无网络下进入,不断弹出无网络的toast,按返回键无效
- iOS安全系列之一:HTTPS
- 博客迁移到http://pengliu.cf
- Nginx+Tomcat+SSL 识别 https还是http
- HttpClient网络请求
- linux下的网络配置
- 网络编程的异常及处理
- 卷积神经网络
- 用libevent实现httpserver
- TCP选项之SO_LINGER
- Layer3 OSPF网络类型和LSA1、2
- 银行卡网络安全系统的三级密钥体系
- Caffe之学习网络参数
- 计算机网络基础知识笔记(四)
- HTTP缓存头Last-Modified和ETag介绍