性能优化之mysql索引优化
2016-07-07 19:38
579 查看
sql及索引优化
如何通过慢查询日志发现有问题的sql?
查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询
IO大的sql
注意pt-query-digest分析中的rows examine项
未命中索引的sql
注意pt-query-digest分析中rows examine 和 rows send的对比
磁盘IO与预读:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间,旋转时间,传输时间三个部分。虽然平常理论上来说没什么压力,
但是数据库如果动辄十万百万乃至千万级数据,显然是个灾难。
了解下mysql的B+树:一种为了减少IO操作快速搜索到数据的数据结构,如下图:
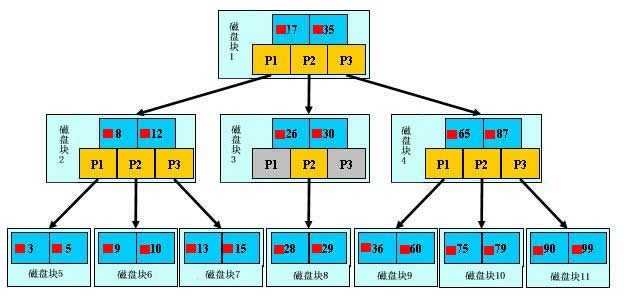
说明:
蓝色部分磁盘块
黄色部分指针
深蓝色目标数据块
分析一下查找的过程:
如果要查询数据为29的值:
1.将磁盘一加入到内存中此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针
2.通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO
3. 29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询
总结:总计三次IO,真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,
每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
解释下什么叫二分法:其实就是一种通过不断排除不可能的东西,来最终找到需要的东西的一种方法,所以可以理解成排除法。之所以叫二分,是因为
每次排除都把所有的情况分为“可能”和不可能两种,然后抛弃所有“不可能”的情况。
优化sql实际上主要目的是为了减少IO操作:
1.如果想在mysql配置方面减少IO的操作:尽可能使用缓存,减少读写对数据库的随机IO的请求,同时减少写的随机IO的随时发生,利用各种buffer去缓存。
2.创建索引:合理的索引是为了少量IO操作达到数据的获取。
建立索引的几大原则:
1.在where 从句,group by从句,on从句中出现的列
2.最左前缀匹配,非常重要的原则,mysql会一直向左匹配直到遇到范围查询(>,<,between,like)就停止匹配
eg:a=1 and b=2 and c=3 and d=4 索引 add index (a,b,c,d) 这样创建d是用不到索引的
eg:a=1 and b=2 and c=3 and d=4 索引 add index(a,b,d,c) 这样创建则都可以用到,a,b,d的顺序可以任意调整
3.离散度大的列放到联合索引的前面
计算离散度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
select * from payment where staff_id=2 and customer_id=584;
是index(sftaff_id,customer_id)好?还是index(customer_id,staff_id)?
由于customer_id的离散度更大,所以应该使用index(customer_id,staff_id)
4.索引列不能参与计算,保持列干净
索引列不能参与计算,保持列干净,在where语句中索引字段不要使用函数,进行检索的时候需要把所有元素都应用函数才能比较,先人成本太大。
5.索引字段越小越好
使用短索引,如果对字符串列进行索引,应该指定一个前缀长度,可节省大量索引空间,提升查询速度。
6.尽量的扩展索引,不要新建索引。
说了这么多索引的优点但是索引也是有负面的:
每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能
2.在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,所花的时间越长。
什么叫做好的索引:
查询频繁(业务逻辑决定)
区分度高
长度小(与区分度保持一个平衡就是一个最优的效果)
尽量能覆盖常用查询字段(并不表示所有字段都建立索引)
sql及索引优化
如何通过慢查询日志发现有问题的sql?
查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询
IO大的sql
注意pt-query-digest分析中的rows examine项
未命中索引的sql
注意pt-query-digest分析中rows examine 和 rows send的对比
磁盘IO与预读:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间,旋转时间,传输时间三个部分。虽然平常理论上来说没什么压力,
但是数据库如果动辄十万百万乃至千万级数据,显然是个灾难。
了解下mysql的B+树:一种为了减少IO操作快速搜索到数据的数据结构,如下图:

说明:
蓝色部分磁盘块
黄色部分指针
深蓝色目标数据块
分析一下查找的过程:
如果要查询数据为29的值:
1.将磁盘一加入到内存中此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针
2.通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO
3. 29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询
总结:总计三次IO,真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,
每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
解释下什么叫二分法:其实就是一种通过不断排除不可能的东西,来最终找到需要的东西的一种方法,所以可以理解成排除法。之所以叫二分,是因为
每次排除都把所有的情况分为“可能”和不可能两种,然后抛弃所有“不可能”的情况。
优化sql实际上主要目的是为了减少IO操作:
1.如果想在mysql配置方面减少IO的操作:尽可能使用缓存,减少读写对数据库的随机IO的请求,同时减少写的随机IO的随时发生,利用各种buffer去缓存。
2.创建索引:合理的索引是为了少量IO操作达到数据的获取。
建立索引的几大原则:
1.在where 从句,group by从句,on从句中出现的列
2.最左前缀匹配,非常重要的原则,mysql会一直向左匹配直到遇到范围查询(>,<,between,like)就停止匹配
eg:a=1 and b=2 and c=3 and d=4 索引 add index (a,b,c,d) 这样创建d是用不到索引的
eg:a=1 and b=2 and c=3 and d=4 索引 add index(a,b,d,c) 这样创建则都可以用到,a,b,d的顺序可以任意调整
3.离散度大的列放到联合索引的前面
计算离散度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
select * from payment where staff_id=2 and customer_id=584;
是index(sftaff_id,customer_id)好?还是index(customer_id,staff_id)?
由于customer_id的离散度更大,所以应该使用index(customer_id,staff_id)
4.索引列不能参与计算,保持列干净
索引列不能参与计算,保持列干净,在where语句中索引字段不要使用函数,进行检索的时候需要把所有元素都应用函数才能比较,先人成本太大。
5.索引字段越小越好
使用短索引,如果对字符串列进行索引,应该指定一个前缀长度,可节省大量索引空间,提升查询速度。
6.尽量的扩展索引,不要新建索引。
说了这么多索引的优点但是索引也是有负面的:
每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能
2.在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,所花的时间越长。
什么叫做好的索引:
查询频繁(业务逻辑决定)
区分度高
长度小(与区分度保持一个平衡就是一个最优的效果)
尽量能覆盖常用查询字段(并不表示所有字段都建立索引)
如何通过慢查询日志发现有问题的sql?
查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询
IO大的sql
注意pt-query-digest分析中的rows examine项
未命中索引的sql
注意pt-query-digest分析中rows examine 和 rows send的对比
磁盘IO与预读:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间,旋转时间,传输时间三个部分。虽然平常理论上来说没什么压力,
但是数据库如果动辄十万百万乃至千万级数据,显然是个灾难。
了解下mysql的B+树:一种为了减少IO操作快速搜索到数据的数据结构,如下图:
说明:
蓝色部分磁盘块
黄色部分指针
深蓝色目标数据块
分析一下查找的过程:
如果要查询数据为29的值:
1.将磁盘一加入到内存中此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针
2.通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO
3. 29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询
总结:总计三次IO,真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,
每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
解释下什么叫二分法:其实就是一种通过不断排除不可能的东西,来最终找到需要的东西的一种方法,所以可以理解成排除法。之所以叫二分,是因为
每次排除都把所有的情况分为“可能”和不可能两种,然后抛弃所有“不可能”的情况。
优化sql实际上主要目的是为了减少IO操作:
1.如果想在mysql配置方面减少IO的操作:尽可能使用缓存,减少读写对数据库的随机IO的请求,同时减少写的随机IO的随时发生,利用各种buffer去缓存。
2.创建索引:合理的索引是为了少量IO操作达到数据的获取。
建立索引的几大原则:
1.在where 从句,group by从句,on从句中出现的列
2.最左前缀匹配,非常重要的原则,mysql会一直向左匹配直到遇到范围查询(>,<,between,like)就停止匹配
eg:a=1 and b=2 and c=3 and d=4 索引 add index (a,b,c,d) 这样创建d是用不到索引的
eg:a=1 and b=2 and c=3 and d=4 索引 add index(a,b,d,c) 这样创建则都可以用到,a,b,d的顺序可以任意调整
3.离散度大的列放到联合索引的前面
计算离散度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
select * from payment where staff_id=2 and customer_id=584;
是index(sftaff_id,customer_id)好?还是index(customer_id,staff_id)?
由于customer_id的离散度更大,所以应该使用index(customer_id,staff_id)
4.索引列不能参与计算,保持列干净
索引列不能参与计算,保持列干净,在where语句中索引字段不要使用函数,进行检索的时候需要把所有元素都应用函数才能比较,先人成本太大。
5.索引字段越小越好
使用短索引,如果对字符串列进行索引,应该指定一个前缀长度,可节省大量索引空间,提升查询速度。
6.尽量的扩展索引,不要新建索引。
说了这么多索引的优点但是索引也是有负面的:
每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能
2.在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,所花的时间越长。
什么叫做好的索引:
查询频繁(业务逻辑决定)
区分度高
长度小(与区分度保持一个平衡就是一个最优的效果)
尽量能覆盖常用查询字段(并不表示所有字段都建立索引)
sql及索引优化
如何通过慢查询日志发现有问题的sql?
查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询
IO大的sql
注意pt-query-digest分析中的rows examine项
未命中索引的sql
注意pt-query-digest分析中rows examine 和 rows send的对比
磁盘IO与预读:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间,旋转时间,传输时间三个部分。虽然平常理论上来说没什么压力,
但是数据库如果动辄十万百万乃至千万级数据,显然是个灾难。
了解下mysql的B+树:一种为了减少IO操作快速搜索到数据的数据结构,如下图:
说明:
蓝色部分磁盘块
黄色部分指针
深蓝色目标数据块
分析一下查找的过程:
如果要查询数据为29的值:
1.将磁盘一加入到内存中此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针
2.通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO
3. 29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询
总结:总计三次IO,真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,
每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
解释下什么叫二分法:其实就是一种通过不断排除不可能的东西,来最终找到需要的东西的一种方法,所以可以理解成排除法。之所以叫二分,是因为
每次排除都把所有的情况分为“可能”和不可能两种,然后抛弃所有“不可能”的情况。
优化sql实际上主要目的是为了减少IO操作:
1.如果想在mysql配置方面减少IO的操作:尽可能使用缓存,减少读写对数据库的随机IO的请求,同时减少写的随机IO的随时发生,利用各种buffer去缓存。
2.创建索引:合理的索引是为了少量IO操作达到数据的获取。
建立索引的几大原则:
1.在where 从句,group by从句,on从句中出现的列
2.最左前缀匹配,非常重要的原则,mysql会一直向左匹配直到遇到范围查询(>,<,between,like)就停止匹配
eg:a=1 and b=2 and c=3 and d=4 索引 add index (a,b,c,d) 这样创建d是用不到索引的
eg:a=1 and b=2 and c=3 and d=4 索引 add index(a,b,d,c) 这样创建则都可以用到,a,b,d的顺序可以任意调整
3.离散度大的列放到联合索引的前面
计算离散度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
select * from payment where staff_id=2 and customer_id=584;
是index(sftaff_id,customer_id)好?还是index(customer_id,staff_id)?
由于customer_id的离散度更大,所以应该使用index(customer_id,staff_id)
4.索引列不能参与计算,保持列干净
索引列不能参与计算,保持列干净,在where语句中索引字段不要使用函数,进行检索的时候需要把所有元素都应用函数才能比较,先人成本太大。
5.索引字段越小越好
使用短索引,如果对字符串列进行索引,应该指定一个前缀长度,可节省大量索引空间,提升查询速度。
6.尽量的扩展索引,不要新建索引。
说了这么多索引的优点但是索引也是有负面的:
每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能
2.在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,所花的时间越长。
什么叫做好的索引:
查询频繁(业务逻辑决定)
区分度高
长度小(与区分度保持一个平衡就是一个最优的效果)
尽量能覆盖常用查询字段(并不表示所有字段都建立索引)

相关文章推荐
- mysql 根据某些字段之和排序
- mysql 源码--xpchild
- Mysql学习总结(20)——MySQL数据库优化的最佳实践
- Mysql学习总结(20)——MySQL数据库优化的最佳实践
- mysql索引
- mysql压缩版安装 修改默认字符集
- mysql更改已有数据表的字符集,保留原有数据内容
- 怎样在mysql里面修改数据库名称
- mysql事务管理
- MySQL 去除字段中的换行和回车符
- MYSQL的慢查询分析
- 对实体 "characterEncoding" 的引用必须以 ';' 分隔符结尾。
- DB2错误码
- WARN: Establishing SSL connection without server's identity verification is not recommended.
- MySql 存储过程
- mysql格式化日期
- mysql删除某个字段重复的数据
- mac下mysql的安装与使用
- Toad for Mysql 连接远程服务器的数据库问题记录
- MySQL触发器 Update触发Insert失败