centos中spark1.3.1环境搭建
2016-07-06 14:32
507 查看
一、Java安装
1、安装包准备:
首先到官网下载jdk,http://www.oracle.com/technetwork/java/javase/downloads /jdk7-downloads-1880260.html,我下载jdk-7u79-linux-x64.tar.gz,下载到主目录
2、解压安装包
通过终端在/usr/local目录下新建java文件夹,命令行:
sudo mkdir /usr/local/java
然后将下载到压缩包拷贝到java文件夹中,命令行:
进入jdk压缩包所在目录
cp jdk-7u79-linux-x64.tar.gz /usr/local/java
然后进入java目录,命令行:
cd /usr/local/java
解压压缩包,命令行:
sudo tar xvf jdk-7u79-linux-x64.tar.gz
然后可以把压缩包删除,命令行:
sudo rm jdk-7u79-linux-x64.tar.gz
3、设置jdk环境变量
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
4、检验是否安装成功
在终端
java -version
显示如下
二、scala2.11.4安装
1、安装包准备:
首先到官网下载scala,http://www.scala-lang.org/,下载scala-2.11.4.tgz,并复制到/usr/lib
2、解压安装包
tar -zxf scala-2.11.4.tgz
3、设置scala环境变量
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
4、检验是否安装成功
在终端
scala -version
显示如下
[root@master scala-2.11.6]# scala
三、hadoop2.3安装
1、安装包准备:
hadoop版本有点混乱,除了http://hadoop.apache.org/有 众多版本之外,还有Cloudera公司的CDH版本,请从观望下载hadoop-2.3.0.tar.gz或者下载CDH版本hadoop- 2.3.0-cdh5.0.0.tar.gz,本文环境是在hadoop-2.3.0-cdh5.0.0.tar.gz之上建立。
2、解压安装包
下载安装包之后复制到/usr目录。
tar -zxf hadoop-2.3.0-cdh5.0.0.tar.gz
解压后生成hadoop-2.3.0-cdh5.0.0,重命名为hadoop-2.3.0。
3、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
vi /etc/profile
打开之后在末尾添加
使profile生效
3、建立hadoop用户
useradd hadoop
passwd hadoop
3、配置SSH免登录
四、spark1.3.1安装
1、安装包准备:
spark官网下载spark-1.3.1-bin-hadoop2.3.tgz。
2、解压安装包
下载安装包之后复制到/usr目录。
解压后生成spark-1.3.1-bin-hadoop2.3,重命名为spark-1.3.1-hadoop2.3。
3、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
4、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
配置Spark环境变量
配置Slave
到此为止,前面所有的安装配置动作,在你的另一个机器上(所有的slave机器)同样的做一遍,即我这里的181机器
HADOOP_CONF_DIR是Hadoop配置文件目录,SPARK_MASTER_IP主机IP地址,SPARK_WORKER_MEMORY是worker使用的最大内存
完成配置后,将spark目录copy slave机器
5、启动Spark Master
6、启动Spark Slave
7、进入spark-1.2.0-bin-hadoop2.4/sbin/目录
如果没有设置ssh免密码登陆,会要求输入密码
这时候jps查看多了个master和worker
8、浏览器查看集群信息
master地址+8099端口
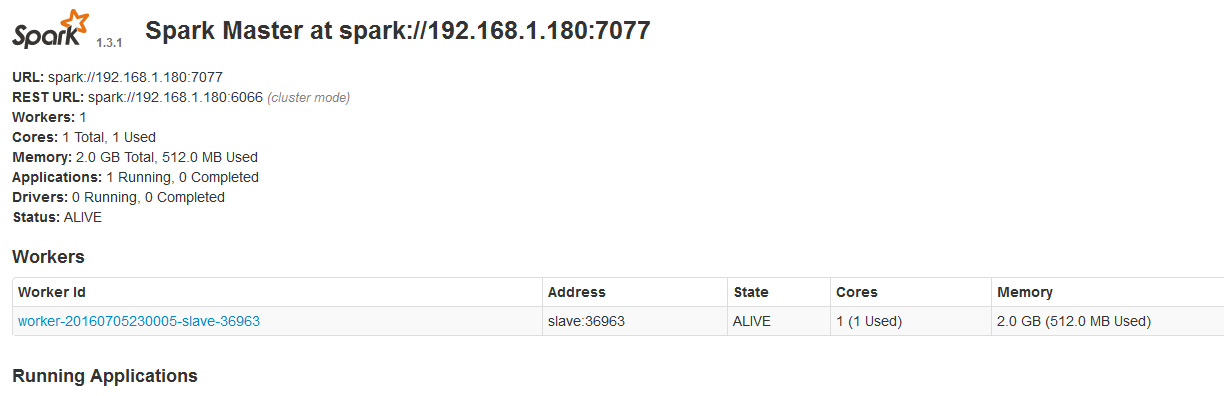
9、启动Running Applications
在bin目录下执行:
MASTER=spark://192.168.1.180:7077 ./spark-shell 这时候就可以看到运行的app


欢迎交流学习!
1、安装包准备:
首先到官网下载jdk,http://www.oracle.com/technetwork/java/javase/downloads /jdk7-downloads-1880260.html,我下载jdk-7u79-linux-x64.tar.gz,下载到主目录
2、解压安装包
通过终端在/usr/local目录下新建java文件夹,命令行:
sudo mkdir /usr/local/java
然后将下载到压缩包拷贝到java文件夹中,命令行:
进入jdk压缩包所在目录
cp jdk-7u79-linux-x64.tar.gz /usr/local/java
然后进入java目录,命令行:
cd /usr/local/java
解压压缩包,命令行:
sudo tar xvf jdk-7u79-linux-x64.tar.gz
然后可以把压缩包删除,命令行:
sudo rm jdk-7u79-linux-x64.tar.gz
3、设置jdk环境变量
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
export JAVA_HOME=/usr/local/java/jdk1.7.0_79 export JRE_HOME=/usr/local/java/jdk1.7.0_79/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin: $PATH 使profile生效 source /etc/profile
4、检验是否安装成功
在终端
java -version
显示如下
java version "1.7.0_79" Java(TM) SE Runtime Environment (build 1.7.0_79-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
二、scala2.11.4安装
1、安装包准备:
首先到官网下载scala,http://www.scala-lang.org/,下载scala-2.11.4.tgz,并复制到/usr/lib
2、解压安装包
tar -zxf scala-2.11.4.tgz
3、设置scala环境变量
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
export SCALA_HOME=/usr/lib/scala-2.11.4 export PATH=$SCALA_HOME/bin:$PATH 使profile生效 source /etc/profile
4、检验是否安装成功
在终端
scala -version
显示如下
Scala code runner version 2.11.4 -- Copyright 2002-2013, LAMP/EPFL
[root@master scala-2.11.6]# scala
Welcome to Scala version 2.11.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71). Type in expressions to have them evaluated. Type :help for more information.
三、hadoop2.3安装
1、安装包准备:
hadoop版本有点混乱,除了http://hadoop.apache.org/有 众多版本之外,还有Cloudera公司的CDH版本,请从观望下载hadoop-2.3.0.tar.gz或者下载CDH版本hadoop- 2.3.0-cdh5.0.0.tar.gz,本文环境是在hadoop-2.3.0-cdh5.0.0.tar.gz之上建立。
2、解压安装包
下载安装包之后复制到/usr目录。
tar -zxf hadoop-2.3.0-cdh5.0.0.tar.gz
解压后生成hadoop-2.3.0-cdh5.0.0,重命名为hadoop-2.3.0。
3、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
vi /etc/profile
打开之后在末尾添加
export HADOOP_HOME=/home/zero/hadoop/hadoop-2.3.0 export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使profile生效
source /etc/profile
3、建立hadoop用户
useradd hadoop
passwd hadoop
3、配置SSH免登录
su hadoop //切换到hadoop用户目录下 ssh-keygen-t rsa(一路回车 生成密钥) cd/home/hadoop/.ssh/ scp id_rsa.pub hadoop@slave1:/home/hadoop/.ssh/ mv id_rsa.pub authorized_keys
四、spark1.3.1安装
1、安装包准备:
spark官网下载spark-1.3.1-bin-hadoop2.3.tgz。
2、解压安装包
下载安装包之后复制到/usr目录。
tar -zxf spark-1.3.1-bin-hadoop2.3.tgz tar zxvf spark-1.3.1-bin-hadoop2.3.tgz
解压后生成spark-1.3.1-bin-hadoop2.3,重命名为spark-1.3.1-hadoop2.3。
3、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
export SPARK_HOME=/usr/spark-1.3.1-hadoop2.3 export PATH=$SPARK_HOME/bin:$PATH 使profile生效 source /etc/profile
4、配置环境
这里采用全局设置方法,就是修改etc/profile,它是是所有用户的共用的环境变量
sudo vi /etc/profile
打开之后在末尾添加
export SPARK_HOME=/usr/spark-1.3.1-hadoop2.3 export PATH=$SPARK_HOME/bin:$PATH 使profile生效 source /etc/profile
配置Spark环境变量
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh 添加以下内容:
export JAVA_HOME=/usr/local/java-1.7.0_79
export HADOOP_HOME=/usr/hadoop-2.3.0
export HADOOP_CONF_DIR=/etc/hadoop/conf
export SCALA_HOME=/usr/lib/scala-2.11.4
export SPARK_HOME=/usr/spark-1.3.1-hadoop2.3
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3 //每个Worker使用的CPU核数
export SPARK_WORKER_INSTANCES=1 //每个Slave中启动几个Worker实例
export SPARK_WORKER_MEMORY=10G //每个Worker使用多大的内存
export SPARK_WORKER_WEBUI_PORT=8081 //Worker的WebUI端口号
export SPARK_EXECUTOR_CORES=1 //每个Executor使用使用的核数
export SPARK_EXECUTOR_MEMORY=1G //每个Executor使用的内存
export SPARK_CLASSPATH=/usr/spark-1.3
bd08
.1-hadoop2.3/lib/sequoiadb-driver-1.12.jar:/usr/spark-1.3.1-hadoop2.3/lib/spark-sequoiadb_2.11.2-1.12.jar //使用巨衫数据库
export SPARK_CLASSPATH=$SPARK_CLASSPATH:$CLASSPATH
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/nativ配置Slave
cp slaves.template slaves vi slaves 添加以下内容: 192.168.1.180 192.168.1.181
到此为止,前面所有的安装配置动作,在你的另一个机器上(所有的slave机器)同样的做一遍,即我这里的181机器
HADOOP_CONF_DIR是Hadoop配置文件目录,SPARK_MASTER_IP主机IP地址,SPARK_WORKER_MEMORY是worker使用的最大内存
完成配置后,将spark目录copy slave机器
scp -r ~/opt/spark-1.2.0-bin-hadoop2.4 spark@10.126.45.56:~/opt/
5、启动Spark Master
cd $SPARK_HOME/sbin/ ./start-master.sh
6、启动Spark Slave
cd $SPARK_HOME/sbin/ ./start-slaves.sh
7、进入spark-1.2.0-bin-hadoop2.4/sbin/目录
执行:./start-all.sh
如果没有设置ssh免密码登陆,会要求输入密码
这时候jps查看多了个master和worker
8、浏览器查看集群信息
master地址+8099端口
9、启动Running Applications
在bin目录下执行:
MASTER=spark://192.168.1.180:7077 ./spark-shell 这时候就可以看到运行的app
欢迎交流学习!

相关文章推荐
- centos7 安装mysql5.6
- linux添加自启服务(程序)
- centos samba服务器的配置和使用
- 处理大并发之四 libevent demo详细分析(对比epoll)
- CentOS 7下的 Mysql 主从配置
- sed实战之——删除空行(包括由空格组成的空行)
- 用Xmanager连接红旗linux的远程桌面
- Linux C OSS音频编程
- Linux C OSS音频编程
- Linux C OSS音频编程
- Linux后台进程管理
- linux中字符串转换函数 simple_strtoul
- Linux驱动开发学习的一些必要步骤
- Centos7 下Boost 1.61.0源码 配置开发环境
- Linux下安装informix11.5数据库
- 在 CentOS7 上安裝 VMware vSphere CLI (vcli)
- 一步一步学ROP之linux_x86篇
- linux C 获取当前的工作目录
- linux C 获取当前的工作目录
- linux C 获取当前的工作目录