APUE [Linux C 编程开发环境(工具链,编译,汇编,链接,库)基础知识与实践]
2016-07-05 10:53
686 查看
前言
本博文包括对下面书籍的学习笔记,以及实际上机编程练习,程序运行分析等的总结,作为日后工作的参考:
《UNIX 环境高级编程(第三版)》
《深度探索 Linux 操作系统:系统构建和原理解析》
《深入理解计算机系统(原书第二版)》
一个典型的 Linux 进程“能看到”的虚拟地址空间如下图:
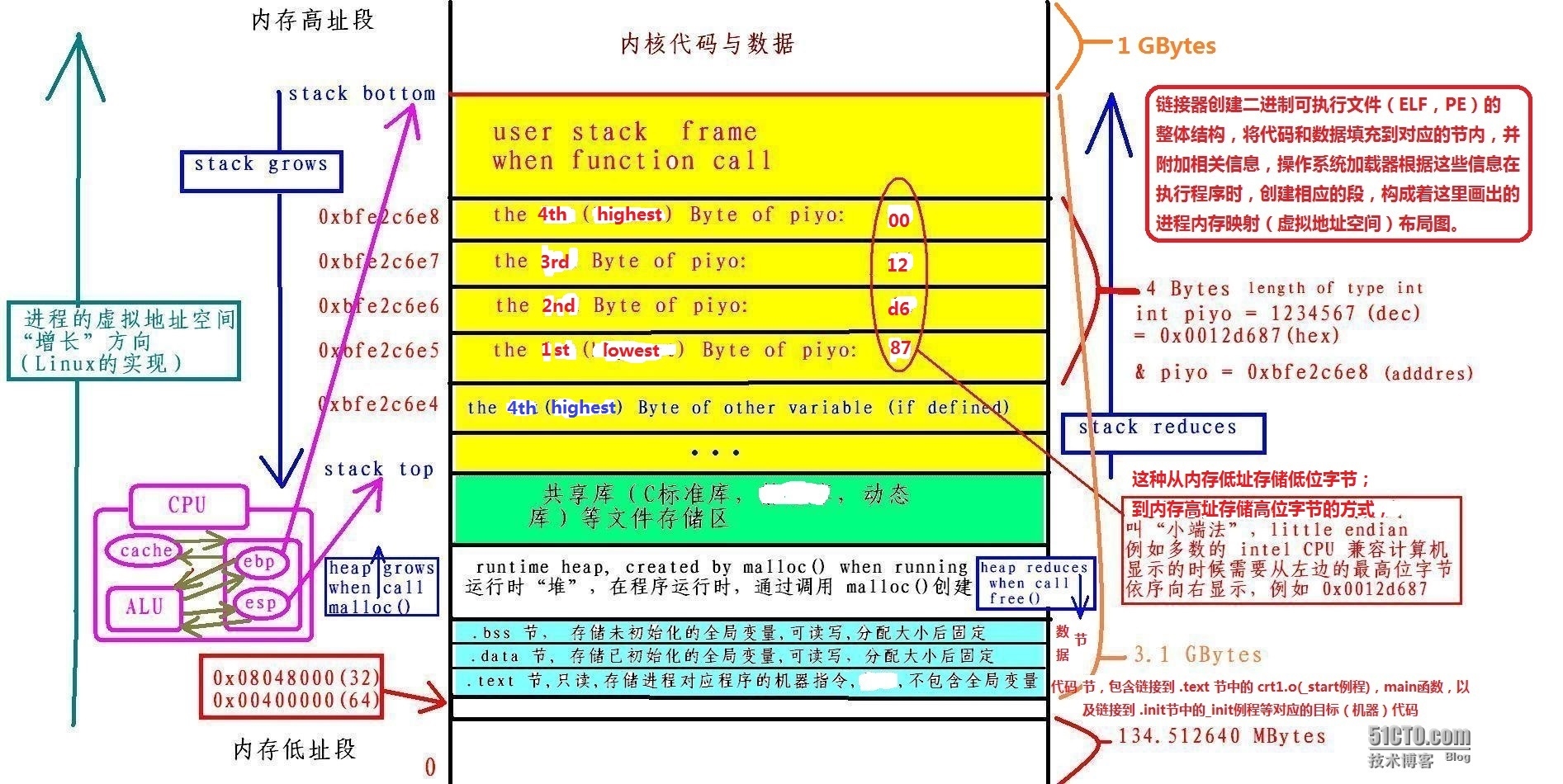
从第一张图可以看出:
每个 Linux 程序都有一个“运行时存储器映像”(即进程的虚拟地址空间),在 32位 Linux 系统中,代码段(上图中的 .text 节,准确的名称应为 .text 段,“节”是磁盘上程序代码的叫法;“段”是程序代码载入内存后的叫法,因此上图有些不准确)总是从地址 0x08048000
处开始;
数据段(上图中的 .data 节,准确的名称应为 .data 段)是在接下来的下一个 4KB 对齐的地址处;
(4096 dec = 1000 hex,0x08048000 + 0x00001000 = 0x08049000 )
运行时“堆”在数据段之后的第一个 4KB 对齐的地址处,并在调用 malloc() 库函数时,往内存高址段增长;
还有一个“段”,是为共享库保留的(静态库与共享库的区别将在后面解释);
用户栈总是从最大(高)的合法内存地址开始,向内存低址(下)增长的;
用户栈上方的“段”是为操作系统驻留存储器的部分(内核)的代码和数据保留的;
从第一张图可以看出,指针是特殊的内存块,其中存放着其它内存块的地址,叫做指针的值;
指针自身也有地址,因为32位处理器用于寻址的地址总线为32位宽,所以内存地址的长度为32位(4字节),这意味着,指针自身必须占用连续的4字节内存地址,然后每个1字节的内存地址存放目标内存块的1字节内存地址;
换言之,指针自身占用4字节的内存地址;这4个1字节的存储区域用于存放其它内存地址,即指针值
以第一张图为例,假设将
0xbfe2c6e8 ~ 0xbfe2c6e5 这连续4字节的内存单元定义为指针,那么当指针指向另一个内存块的地址时,假设指针指向
0xbfe2c6e0 这个内存地址,那么存储规则如下:
(假设计算机为运行 32 位 Linux 的 Intel IA32 架构 CPU,小端法机器)
地址 0xbfe2c6e8 存储字节 e0
地址 0xbfe2c6e7 存储字节 c6
地址 0xbfe2c6e6 存储字节 e2
地址 0xbfe2c6e5 存储字节 bf
注意,在基于 64 位 Linux / Intel x86-64 CPU 这种操作系统/处理器架构的计算机上,指针的长度为8字节
*****如果声明一个指针却没有初始化,那么,这个指针自身可能位于声明它的函数所在的栈帧中的某个4字节连续地址,但是,这4字节连续地址存储的内容,即指针值,或者叫指针指向的内存地址,却是在进程虚拟地址空间的 .bss 节,
也就是说,在离栈区很远(往内存低址方向)的 .bss 节中,分配存储空间,其中没有内容(未初始化,或者保留了之前未清除的不明数据)
为了能透彻理解这一点,考虑如下 C 源码:
以 gcc 编译上述源程序并运行,得到下面输出结果:
结合上面内容,我们发现,在 main 函数中声明一个指针时,它自身的地址就在 main 函数栈帧的某个4字节连续地址处:例如从
0xbf9e6054 开始的4字节地址
(参考第一张图,以 0xbf 开头的内存地址,就是函数调用时展开栈帧使用的地址段)
但是这里我们没有对 pointer_to_hoge 进行初始化,所以它指向一个离自己“家里”(声明它的 main 函数的栈帧)很远的地方——地址
0x08048229 处,
通过 * 符号对 pointer_to_hoge 进行解引用操作后,我们发现
这个地址存储的数据(0x696c5f5f)是未知的,可能是前面程序留下的垃圾数据;
从第一张图可以看出:
一,这2个地址至少相距 3 GBytes 以上,验证计算:
[b]0xbf9e6054 - 0x08048229 = b799de2b ,
[/b]
0x[b]b799de2b(hex) = 3080314411(dec),[/b]
3080314411 Bytes = 3.08 GBytes
这似乎说明了 Linux 操作系统为每个进程维护“虚拟的” 4 GBytes 地址空间,
3 GBytes 以上的地址空间为内核部分(参考第一张图)
二,以 0x08048000 开头的内存地址,为
.text 节,用于存储从磁盘加载进来的相应二进制机器代码程序,
这个结果意味着,从 0x08048000 开始,向内存高址方向偏移229字节,就是进程虚拟地址空间中,用来存储未初始化变量的地方,即
.bss 节
在第一张图中,每个进程都有一个叫 .text 节的地址空间“段”
在用类似 gcc 等编译器编译程序时,在链接阶段,不论是调用库函数中的机器代码,还是从自行编写源程序生成的机器代码,都会被链接器链接在一起,最终,由链接器
ld 生成的二进制可执行机器代码存储在磁盘上,并且在程序运行时将磁盘上的相应文件加载到内存中的 .text 节
关于 .text 节 的更多内容,请考虑如下源码:
my_LS_command_implement.c
上面这个例子来自于《UNIX 环境高级编程(第三版)》
一书中第4页的内容,这是作者自己实现的一个 ls 命令的源码,
这个简单的 ls 命令,虽然不能像系统的 ls 命令那样通过解析用户输入的参数选项,显示文件的大小,类型,权限,I节点,而且也不能对列出的条目进行从 a~z 的名称排序,但它所涉及的 UNIX 相关知识和编程技巧,已经足够我们临摹的了
apue.h 头文件是作者自定义的一个头文件,其中引入了许多系统编程必备的 UNIX 和 C 标准头文件,这样做的目的在于缩小源码的体积,如果你想测试这里给出的源码,apue.h 是必不可少的,否则 gcc 编译器无法找到结构体 DIR 的定义,找不到 err 前缀的错误处理函数定义,
下面给出该头文件的内容,因为作者在该书附录中没有将他自行编写的错误处理函数(标准出错例程)和 apue.h 整合在同一个头文件中,因此我提供一个稍加整理后的 apue.h 版本,其中带有标准出错例程的定义,
简单的讲,引入下面这个文件就能解决大多数的系统头文件重复包含,递归包含等问题,并且能正常运行本博文后续给出的其它源码(当然,对于本例而言,还需要引入
dirent.h 头文件,它的位置在
/usr/include/dirent.h 与
/usr/include/bits/dirent.h )
apue.h 头文件源码(整理版)
必须指出,apue.h 中包含的出错例程(函数)仅用于将信息输出到标准错误;
当程序作为守护进程运行时,需要有另外的出错例程(函数)来处理守护进程可能输出的信息,例如与 syslog 进程通信并记录到日志等,
限于篇幅,这里没有整合相应的源码,有兴趣的童鞋,请参考
《UNIX 环境高级编程(第三版)》一书中,第727页开始的内容
my_LS_command_implement.c 程序的功能很简单,它通过用户在 shell 命令行中指定的绝对路径,来列出该目录下的内容
该程序第7,8行分别定义了 DIR 结构型指针与 dirent 结构型指针,用于指向后面
opendir() 与 readdir() 函数返回的内容;
第10~11行首先判断,用户输入的 shell 命令行参数个数(命令行参数个数通过 main 函数的第一个参数 argc 传递;命令行参数内容通过 main 函数的第二个参数 argv[] 传递)是否有2个,如果没有2个,则调用作者编写的标准出错例程提醒用户:必须指定要打开的目录;
第13~14行调用库函数 opendir 打开用户指定的目录,该目录通过 argv[1] 传递给 opendir(),通过将后者返回的值(DIR结构型变量)赋给 dp 并判断:如果 dp 为空指针则说明打开目录失败,此时调用作者编写的标准出错例程提醒用户:无法打开指定的目录;
第15~16行将指向 opendir() 成功打开的目录( DIR 结构型变量)的指针 dp 作为参数传递并在一个 while 循环中反复调用库函数 readdir ,将后者返回的值(dirent
结构型变量)赋给 dirp 指针并判断:如果 readdir() 读取完目录中的所有文件和子目录,此时 dirp 为空指针,退出循环;反之,每当 readdir() 成功读取目录中的一个文件或子目录,就打印该文件或目录的名称(通过访问 dirp 指向的 dirent
结构型的 d_name 成员,该成员存储名称)
第18行将 dp 指针作为参数传递并调用库函数 closedir,用来关闭 opendir()打开的目录
第19行使用标准的退出程序方式:以参数0调用 exit 函数,表示没有错误,正常退出
分析完源码后,我们继续回到对 .text 节 的讨论
假设,我们在编程时特意将上面的一个库函数 closedir() 的名称拼写错误来调用,那么在链接阶段,ld 会提示出错如下:
在上面的例子中,错误名称(colsedir)的库函数导致 ld 链接器报错,大意是说,无法在 .text 节起始地址偏移 292 字节处,对未定义的库函数进行引用,ld 将无法链接这个不存在的函数而返回错误(1)
*****补充资料,关于 Linux 进程管理的基础知识:
进程是正在运行的程序,进程可以申请并占用系统的运行资源,是 Linux 系统的“基本调度单位”。
程序是静态的保存在磁盘上的可执行代码和数据的集合,不会占用系统的运行资源(CPU与内存)
内核使用 exec 函数,将程序读入内存并且执行
理论上讲,单个物理CPU在同一时间内只能运行一个进程(准确的说是执行该进程内的机器指令)
Linux 操作系统通过将CPU的资源(占用CPU)划分成很小的时间块,根据不同进程的“优先级”,为每个进程分配不同的时间片(即占用CPU资源的时间)。
每个时间片(即进程占用CPU的时间)约仅有0.x 秒,但是因为现代高性能微处理器的每秒可执行机器指令数在百万条(MIPS)以上,
因此足以让单个进程运行几十万条机器指令,
然后操作系统充分利用了高速处理器的MIPS特性,通过短时间在多个进程间快速切换来分配CPU时间(即任务调度,执行不同进程的机器指令),
实现了在极短时间内,多数进程的大部分机器指令都得以被CPU执行,这就给最终用户造成一种好像同时执行许多任务的假象。
每个进程运行一段时间后,系统根据该进程的运行(处理)进度将其“挂起”,系统转而处理其它进程,再经过一段时间再回来处理该进程,如此反复直到该进程处理完。
分别以进程的视角,内核的视角来观察计算机系统
(摘录自《Linux/UNIX 系统编程手册上册》,ISBN 978-7-115-32867-0)
一个运行系统通常会有多个进程并行其中。对进程来说,许多事件的发生都无法预期。执行中的程序不清楚自己对 CPU 的占用何时“到期”,系统随之又会调度哪个进程来使用 CPU ,以及以何种顺序来调度;进程也不知道自己何时会再次获得对
CPU 的使用。
信号的传递和进程间通信(IPC)事件的触发由内核统一协调,对进程而言,随时可能发生。
诸如此类,进程都一无所知。进程不清楚自己在物理内存地址空间(RAM)中的位置,它仅仅能看到由内核虚拟的地址空间。换言之,进程看到的虚拟地址空间的“某块”特定部分当前究竟是驻留在 RAM 中,还是被保存在交换空间(用磁盘上的特定存储区域作为对 RAM 的补充)里,进程本身并不知道;
与此类似,进程也搞不清,自己通过抽象的树形文件目录引用的文件,究竟位于磁盘驱动器上的哪个盘片,哪个磁道,哪个扇区;
进程的运作方式堪称“与世隔绝”——进程间彼此不能直接通信。进程本身无法创建出新进程,哪怕“自行了断”都不行;另外,进程也不能与计算机外接的输入输出设备直接通信。
相较之下,内核则是运行系统的中枢所在,对于系统的一切无所不知,无所不能,为系统上所有进程提供便利,提供服务。
在内核看来,进程是一个个的实体,内核必须在它们之间共享各种计算机资源;
对于像内存这样的“受限资源”,内核一开始会为进程分配一定数量的资源,并在进程的生命周期内,统筹该进程和整个系统对内存资源的需求,对这一分配进行调整,程序终止时,内核会释放其占用的内存资源,供其它进程重新使用。
其它资源(如 CPU ,网络带宽等)属于“可再生资源”,但必须在所有进程间平等共享;
由哪个进程来接掌对 CPU 的使用,何时“接任”;“任期”多久,都由内核说了算。
在内核维护的数据结构中,包含了与所有正在运行的程序有关的信息;
(就在 /proc/ 目录下,以各自进程 ID 命名的子目录中)
随着进程的创建,状态发生变化或者终结,内核会及时更新这些数据结构。
内核所维护的底层数据结构可以将进程使用的文件名(通过抽象的树形文件路径引用)转换为磁盘的物理位置(找出所在柱面,磁道,扇区)
此外,每个进程的虚拟地址空间到物理内存地址之间的映射,以及与磁盘上用于交换空间的映射,也在内核维护的数据结构之列。
进程间的所有通信,都要通过内核提供的通信机制来完成(以 Linux 内核为例,IPC 机制包含:信号;管道;套接字;消息队列,信号量,共享内存,文件锁。。。等等)
为了响应进程发出的请求,内核可以创建新的进程,终结现有进程。
最后,由内核(特别是其设备驱动程序模块)来执行与输入输出设备之间的所有直接通信,按需与用户进程交互信息。
下面用一个实例源码来展示前面提到的,与内核提供的进程控关制机制相的知识,其在编程中的实际应用;
这个实例是最简单的命令行解释器(shell)的实现:它解释用户输入的命令,并向内核申请创建一个子进程,由后者执行系统调用,从而请求内核加载并运行用户输入命令的对应可执行文件:
process_control.c
关于第1行引入的 apue.h 头文件信息,请参考前文,它汇总了 C 系统编程所需的头文件,并且加入自定义的错误处理函数;
第2行引入的 wait.h 头文件,位于 sys 目录下,这是一个相对路径,对于大多数的 Linux 发行版而言, sys/wait.h 等同于 /usr/include/sys/wait.h;该头文件中,将
waitpid() 声明为外部函数(extern),在第27行调用该函数;
这个程序在单个 main() 中实现了简易的命令行解释器功能;
第6行声明一个长度为4096字节的字符数组 buffer,用来保存用户输入的命令字符串,关于MAXLINE 的宏定义在 apue.h 中,其值正好为 4096;
第7行的 pid_t 类型,在 apue.h 引入的 /usr/include/sys/types.h 中,涉及
pid_t 在多个系统头文件之间的递归宏定义,最终这个类型就是 int;
第10行首先打印1个 % 符号的用意在于区别真正的命令行解释器,如 bash;
(实际打印的是第二个 % ,第一个 % 用于指定其后要打印的字符串格式)
第12到31行正是实现简易命令行解释器的关键代码,其在一个 while 循环中,
反复调用 fgets() 这个 C 库函数(在 apue.h 引入的 stdio.h 中声明),从 stdin(标准输入,这里指虚拟终端)一次读取用户键入的一行字符串(即命令),将其存储在数组 buffer 中,如果用户按下 ctri + d 组合键,那么 fgets() 读取到的第一个字符将是 NULL ,此刻符合 while 循环的退出条件,于是 process_control 进程终止;
因为用户输入完命令的最后会按下回车键,因此 fgets() 返回的每一行(即字符串)的倒数第二个字符都是换行符('\n'),并以 NULL 字符('\0')结束;
所以此刻 buffer 数组中的倒数第二个字符为换行符;最后一个字符为 NULL 字符;
由于第20行的 execlp() 参数仅接受以 NULL 字符结束的变量(buffer 数组中的倒数第二个字符被视为结束符,但它当前为换行符),因此第13到14行检查,并将换行符替换为 NULL 字符,即 0;
从第16行~20行的代码可以看出,该程序(父进程)在最终向内核申请加载并执行与用户输入命令对应的二进制文件前,以系统调用 fork() 创建一个子进程,然后由子进程通过调用 execpl() 向内核申请该操作;注意,fork() 向父进程返回子进程的 pid;向子进程返回 0,这就是第18行的 if 判断的用意所在:指定通过子进程调用 execpl();
而父进程在执行系统调用 fork()创建子进程后,希望等待子进程终止(无论子进程作了什么事),这就是第27行调用 waitpid() 的目的,并且判断其返回的值(代表子进程的终止状态),如果返回值小于 0 ,表示子进程没有正常退出,因此调用自定义的错误处理函数,打印出错提示;
注意,第30行的 printf() 是在 while 循环体中调用的,这意味着,子进程如果正常退出,表示其成功解释执行了用户输入的命令(真正执行的是内核),然后父进程继续调用 fgets(),等待并读取用户下一次的命令输入,如果用户按下 ctrl + d
组合键,此时满足循环结束条件,程序执行流程来到第33行的 exit(0),即退出程序。
下面的内容可以帮助理解上面这个类似shell的程序的工作原理:
1.当用户在外壳 (shell) 运行一个程序时,父外壳进程通过 fork() 系统调用转入内核空间,后者创建一个子进程,它是父进程的一个复制品,有着和父进程完全相同的虚拟地址空间映射,这样就可以将父shell进程的环境变量传递给子进程。fork() 对父进程返回新的子进程的进程 ID(一个非负整数),对子进程则返回0,因为
fork() 创建一个新进程,所以说它被调用一次(由父进程),但返回2次(分别在父进程和在子进程中)
fork() 在子进程中返回0后,子进程通过类似 execve()/execpl() 的exec家族系统调用再次转入内核空间,内核首先识别通过exec族函数参数传入的欲执行的二进制文件(即用户在shell中输入的命令名)是否为它支持的格式,识别任务一般由search_binary_handler函数进行,当识别出 ELF 文件格式后,内核将子进程虚拟地址空间中,除环境变量外的所有段内容用0擦除(不会擦除该进程内核空间的内容)。
另一方面,父shell进程希望等待这个“变身”成其它程序进程的子shell进程执行后终止,因此在上面源码中过调用 waitpid() 实现检查子进程是否正常退出。其参数指定要等待的进程(即 pid 参数为子进程 PID)。waitpid() 返回子进程的终止状态(status)变量。
注意,某些程序在shell中执行时,会“阻塞”父shell进程,也就是shell无法继续处理用户后续的命令输入,可以通过在执行这种会阻塞shell的程序名后面加上符号 & ,该程序就会转入后台运行,这样当前shell可以继续监视用户的命令输入。
另外,实际的 shell 实现,例如 bash ,还会检查用户输入的命令是否为一个内置的 shell 命令,如果不是,则该命令被看成一个可执行目标文件,并且bsah会尝试在环境变量 PATH 指定的磁盘路径中搜索该文件是否存在,如果找到了,才会进行第2步
2.加载。内核执行加载器模块如load_elf_binary(),后者首先读取 ELF 文件中“段头部表”(section header table)的内容,根据其内容,加载器将磁盘上的可执行 ELF 文件中的 .text 节, .data 节,拷贝到被擦除的子进程内存映像中对应的代码(.text)与数据(.data, .bss)段内。
也就是说,在执行静态链接的程序时,加载器的作用就是将链接器创建的各种文件节从磁盘复制到虚拟内存映射中的相应段内。
3.执行。加载器跳转到子进程虚拟地址空间中,程序的入口地址(也就是从调用exec时进入的内核空间再次返回到用户空间),通常是 .text 段的地址,其中包含了 _start 符号标识的地址,在 _start 地址处的启动代码 (startup code): __libc_init_first 是第一个被调用的函数(机器代码的形式),它是在“共享”目标文件 ctrl.o 中定义的,__libc_init_first 调用 .init 段中的 _init 例程(函数),后者执行一些初始化工作,当 _init 退出后,__libc_init_first
调用 atexit 例程,后者加入一些在应用程序(main函数)正常终止的时候,额外调用的程序,atexit 例程退出后,启动代码调用 main 函数(实际运行应用程序),main 函数退出后,启动代码调用 _exit 例程,后者将“对 CPU的控制权”返回操作系统
******在Windows和Linux等现代操作系统中 ,有时候第2步还不会复制可执行文件的代码和数据到shell子进程的地址空间中,而是等到第三步跳转到程序入口点执行时,CPU通过EIP寄存器取出某条指令的虚拟地址,然后将虚拟地址交给芯片内的MMU(地址翻译单元),MMU利用存储在PTBR(页表基址寄存器)中的,由操作系统维护的页表物理起始地址,来查询该指令的虚拟地址位于哪个物理内存页中,然后,在CPU向这个物理内存页的起始地址取出指令或数据之前,加载器赶紧把当前还位于磁盘上ELF文件中对应的代码或数据节,复制拷贝到该物理内存页。
为了验证 fork() 创建一个新的子进程,我们先将上面的源文件用 gcc 将其编译成名为 process_control 的可执行目标文件,然后在真实的 shell 中执行该程序;
此时,process_control 程序的执行流程对应于源码第10行,也就是打印一个 % 字符,等待用户输入命令,此时只有一个进程,即父进程,它并不会调用 fork() 请求内核创建子进程;
打开另一个 shell 终端,在其中执行命令 ps fwwaux | grep 'process_control'
可以看到,该程序运行时的进程树中,仅有一个进程;
有的童鞋可能认为:只要在 process_control 运行时,输入命令,让它创建一个子进程来执行命令,再以 ps fwwaux | grep 'process_control' 查看进程树,应该就能找到子进程的信息;
理论上是如此,但是要记得,当子进程执行 execve() 系统调用时,它的虚拟地址空间会被内核“重构”,用来加载并执行命令,当命令执行完毕,子进程退出,父进程继续“监听”用户的输入;
上述过程,即从 fork() 到 execve() ,再到子进程退出,虽然涉及从用户模式代码到内核模式代码,再到用户模式代码的转换与执行,其经历时间却非常短暂,以当代高性能处理器的 MIPS (每秒可以执行的机器指令数量,以百万条为单位)而言,你无法通过 ps fwwaux 查看到子进程在其“生存时间”内的信息。
这就是我们在源码第19行添加注释语句 sleep(10000); 的原因,它的作用在于,创建子进程后,让其“睡眠”一万毫秒(10秒),在此期间,子进程不会调用 execpl()(execve()),导致用户输入的命令成功执行后,子进程退出;
限于篇幅,关于 sleep() 的内幕,有兴趣的童鞋请自行搜索文献信息,这里不作介绍;
取消注释第19行的代码(保留后面文字说明的注释状态),重新编译process_control.c 源文件,生成
process_control 程序,在一个 shell 终端执行该程序,然后在带有 % 字符的仿真 shell 中,输入任意命令,如 ls ,并按下回车键,你可以发现,必须等待10秒,才会输出 ls 的执行结果;
(限于具体的 Linux 实现,这里 ls 命令可能不会输出结果,子进程“永久”进入睡眠状态)
但是,只要你动作够快,在这10秒内打开另一个真实 shell 或切换到另一个虚拟终端,执行命令
ps fwwaux | grep 'process_control' ,你就能看到有2个
process_control 进程,它们在进程树中为父子关系存在;这表明第19行的代码确实起到了作用,同时也验证了 fork() 系统调用创建新的进程这一事实:
(unix_process_control_use_fork()_and_exec() 程序就是
process_control 程序的重命名版本)
可以看到,
PID 为 6362 的进程是 PID 为 6361 的进程的子进程,生成这两个进程的命令均为
在当前路径下执行 unix_process_control_use_fork()_and_exec() 程序。
一个典型的类 UNIX 系统体系结构如下图:
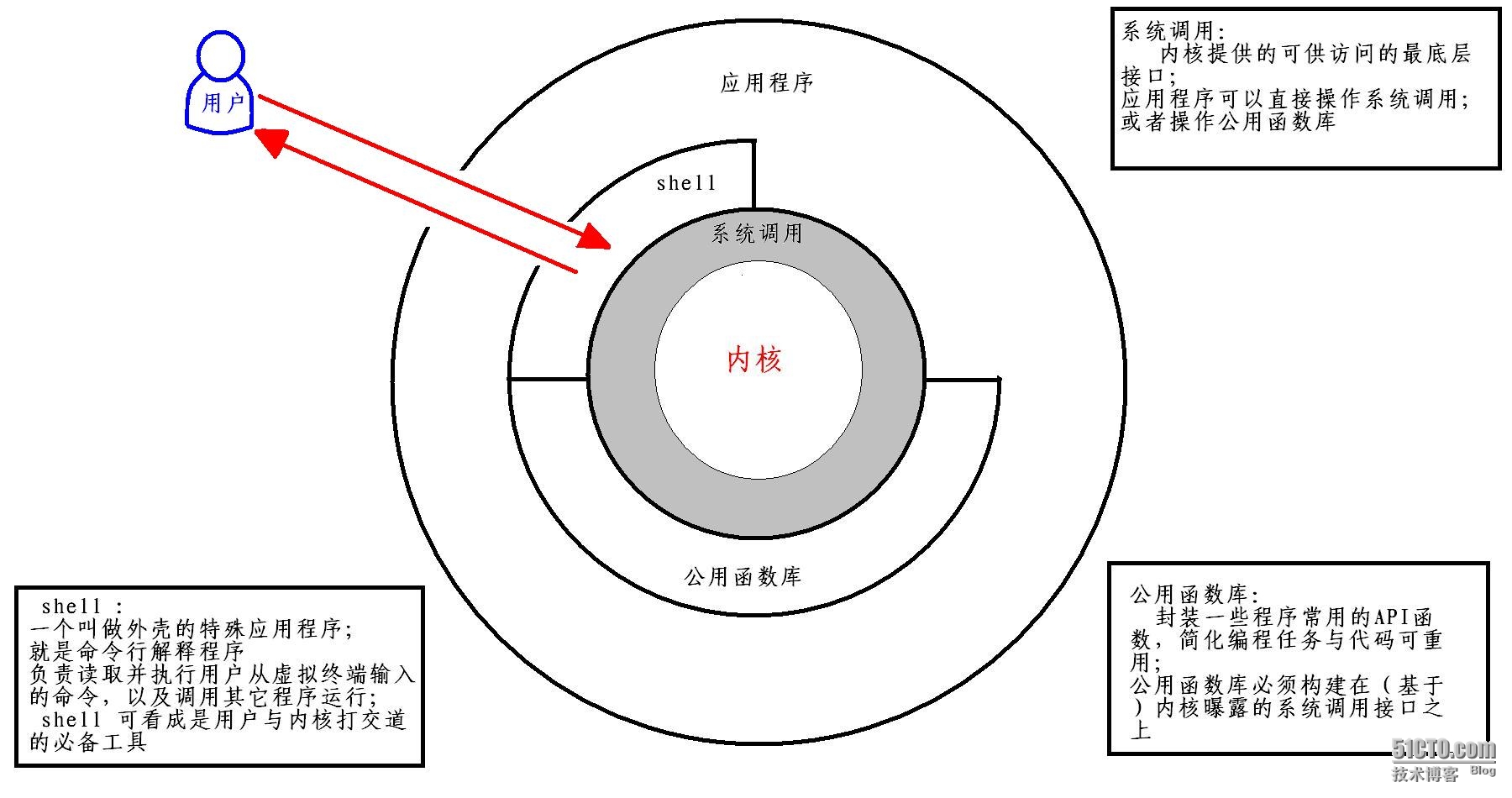
在第二张图中,我们看到“公用函数库”的概念,在 Linux 系统上,这是指包括 Glibc 在内的 C 语言函数库,
有些 glibc 中的库函数使用系统调用来编写,例如,
库函数 fopen() ,使用系统调用 open() 来执行打开文件的实际操作;
但是,有些库函数不使用任何系统调用(字符串操作函数),完全自己实现相应功能;
如图所述,设计与实现库函数的目的,在于提供比底层系统调用更方便的 API,将复杂编程任务化繁为简;
例如, printf() 库函数支持格式化输出与数据缓冲,而
write() 系统调用仅能输出字节块;
同理,与底层系统调用 brk() 相比,库函数
malloc() 与 free() 还执行各种登记管理动作,内存的分配与释放因而容易许多
(以上内容取自《 Linux/UNIX 系统编程手册(上册) 》)
在 C 语言函数库中,有一组专用于 I/O 操作的函数,也称为 stdio 函数库,
包括如下一些常见的函数:
fopen(),fclose(),scanf(),printf(),fgets(),fputs()
以上这些 stdio 函数都构建于内核提供的接口函数(即系统调用):open(),close(),read(),write()之上
当前的新版 gcc 编译器(4.9.1)支持在 2011 年 ISO 发布的 C 语言标准最新版:ISO C11
在编译程序时,可以通过传递给 gcc -std=c11 参数,来指定它按照 C11 的标准编译程序,其余可用的参数值有:
-std=c99 对应 ISO 在1999年公布的 C 语言的 ISO C99 标准
下面这两个参数实际上是同一个C语言标准,效果相同,称为 ISO C89 或者 ANSI C 标准
-std=c89
-ansi
-std=gnu99 由 GNU 项目制定的,涵盖 C99 和其它一些特性的 C语言标准
例如,要以 ISO C99 语法标准来编译前面自己实现的 ls 命令源码:
gcc 也支持一个称为 -Wall 的选项,向用户输出编译过程中的错误(error)和警告(warning)信息,便于调试程序和修正源代码,结合前面的命令一起使用:
在 FreeBSD 10.0 上面,默认安装的 C 编译器是
CLANG,我们可以在 FreeBSD 的
Bourne shell(位于 /bin/sh 路径,由贝尔实验室的 Steve Bourne 开发,所有类 UNIX 的默认 shell)提示符下,输入
来查看 CLANG C 编译器的 man 手册部分
注意,在所有的 Linux 发布版中,默认安装的 C 编译器是 GCC:
一,对于 Ubuntu 12.04 ,可以在 BASH(Bourne-again shell,GNU 项目开发出来的 shell,也是所有 Linux 发布版的默认 shell 之一)的提示符下,输入
来查看 GCC C 编译器的 man 手册部分
二,对于 RedHat6.5 / CentOS6.5 ,必须在 BASH 的提示符下,输入
才能查看 GCC C 编译器的 man 手册部分
*****拓展知识:Glibc 与库函数
Glibc( GNU C 语言函数库 )是 Linux 平台上最常见的标准 C 语言函数库实现
各种类 UNIX 平台,有各自不同的标准 C 语言函数库实现
Linux 平台上其它 C 语言函数库实现,包括用于嵌入式移动设备,受限制存储空间条件下的
uClibc 和 dietlibc C 语言函数库等:
uClibc: http://www.uclibc.org/
dietlibc: http://www.fefe.de/dietlibc/
当我们需要确定 Linux 系统上安装的 glibc 版本时,在 shell 中执行如下命令,直接运行
glibc 共享库文件,来获取其版本:
从上面输出得知,系统当前的 glibc 是 2.12 的稳定版;
该版是在一个基于 Linux 内核 2.6.32 的计算机上,通过 GNU 的 CC (C编译器)版本 4.4.7 进行编译的;
包括一些可用的扩展,如加密插件,原生的 POSIX 标准线程库等等
在某些 Linux 发行版中,glibc 共享库文件并非存放在上述路径,此时可以用
rpm 命令来查询:
同样可以得到以 rpm 包形式安装的 glibc 详细版本;
或者,我们通过查询某个可执行文件在运行时,都链接到哪些共享库的方式,来找出 glibc 共享库文件的存储路径:
在上面的输出中,可以看出,版本 4.9.1 的 gcc ,在运行时链接到的 glibc 共享库文件,位于
/lib/libc.so.6
我们顺藤摸瓜:
可以看到,libc.so.6 仅仅是一个符号链接,
它指向同目录下的 libc-2.12.so,后者才是真实的 glibc 共享库,可以采用如下办法验证:
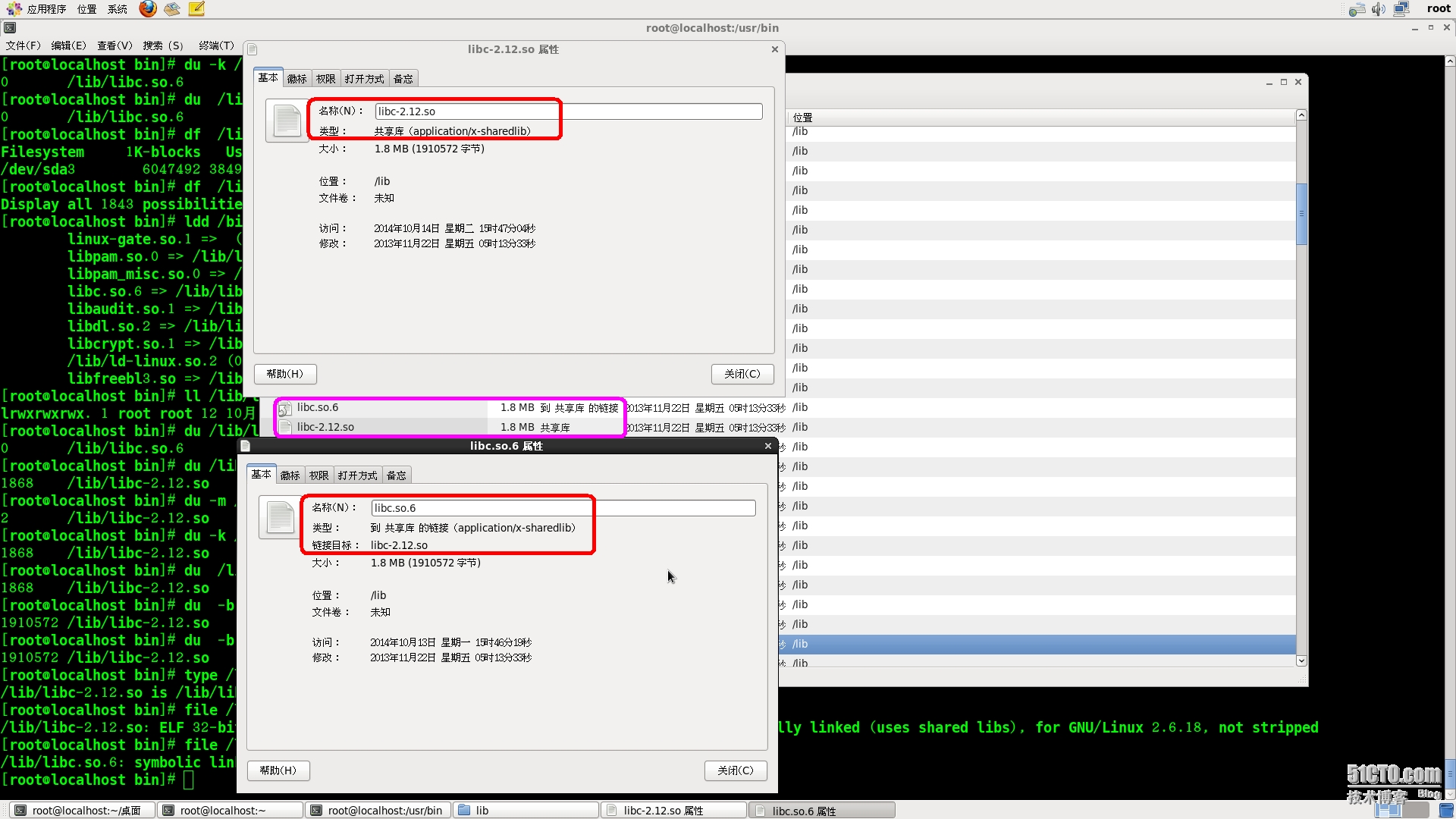
另外,以 du 命令计算文件大小信息时,不接任何参数,默认以 KBytes 为单位显示; -b 参数指定以 Bytes 显示; -m 参数指定以 MBytes 显示
理解上面知识点非常重要
*****用于阻止缓冲区溢出攻击的 Linux 内核参数与 gcc 编译选项
先来看看基于 Red Hat 与 Fedora 衍生版(例如 CentOS)系统用于阻止栈溢出攻击的内核参数,主要包含两项:
kernel.exec-shield
可执行栈保护,字面含义比较“绕”,
实际上就是用来控制能否执行存储在栈
中的代码,其值为1时表示禁止;为0时表示允许;默认为1,表示禁止执行栈
中的代码,如此一来,即便覆盖了函数的返回地址导致栈溢出,也无法执行
shellcode
查看与修改系统当前的可执行栈保护参数:
注意:
一,只有在学习和测试栈溢出攻击的原理时,才建议关闭可执行栈保护机制
二,在基于 Debian 与 Ubuntu 衍生版
(例如 BackTrack 5 Release 3)的系统上,不支持可执行栈保护机制:
或许是社区的开发人员认为,有下面另一种叫做堆栈地址随机化的机制,就足够应对缓冲区溢出攻击了,也可能是由于 Debian / Ubuntu 面向运行桌面应用居多的用户群体,它并不像销售给企业公司用户的 Red Hat 类发行版那样,对安全性的要求更为严格,才能保护用户的服务器,资产安全
kernel.randomize_va_space
堆栈地址随机初始化,很好理解,就是在每次将程序加载到内存时,进程地
址空间的堆栈起始地址都不一样,动态变化,导致猜测或找出地址来执行
shellcode 变得非常困难,它和可执行栈保护的区别在于,后者即便是找到了
地址也是无法执行的;所有的 2.6 以上版本的 Linux 内核都支持并启用了
这一项特性;
查看与修改系统当前的堆栈地址随机初始化参数:
参数值为2时,表示启用随机地址功能;0表示关闭;
基于 Debian 与 Ubuntu 衍生版默认支持并且启用了随机地址功能:
下面,我们在一个启用了随机地址功能的机器上,查看执行同一个程序4次加载的动态链接共享库的入口地址(linux-gate.so.1),发现每次的入口地址都不同,验证了随机地址的效果:
同理,关闭随机地址功能,连续5次查看执行程序时加载的 linux-gate.so.1
入口地址:
再来看看 GCC 4.1 版本以后引入的两个编译参数:
(默认情况下,编译时不会指定这两个参数,用于阻止缺乏安全编码意识的程序员写出存在缓冲区溢出漏洞的程序,
但是站在逆向工程的角度来看,指定这两个参数,特意构造有漏洞的程序,对于学习和理解栈溢出的原理还是有帮助的;
再次提醒,这里介绍的两个编译参数必须同时打开,而且还要同时禁用前面讲的可执行栈保护与栈地址随机初始化,满足这4个条件后,一般而言,就可以测试 shellcode 的效果了
)
GCC 编译选项 -fno-stack-protector
禁用栈保护功能,默认是启用的;
gcc 的栈保护机制是指,在栈的缓冲区(大小通常由程序员给定)写入内容前
,在结束地址之后与返回地址之前,放入随机的验证码,由于栈帧是从内存高
址段向内存低址段增长的(回顾第一张图),结束地址在高址段;返回地
址在低址段,栈溢出时,会从高址段向低址段覆盖数据,因此如果想要覆盖返
回地址的内容,必定先覆盖结束地址,验证码,才能覆盖返回地址,
因此可以通过比较写入缓冲区前后的验证码是否发生改变,来检测并阻止溢出
攻击
GCC 编译选项 -z execstack
启用可执行栈,默认是禁用的;
该选项与
ld 链接器有关:ld 链接器在链接程序的时候,如果所有的 .o 文
件的堆栈段都标记为不可执行,那么整个库的堆栈段才会被标记为不可执行;
相反,即使只有一个 .o 文件的堆栈段被标记为可执行,那么整个库的堆栈段
将被标记为可执行,
换言之,默认是所有的 .o
文件的堆栈段都标记为不可执行
检查堆栈段可执行性的方法是:
找出在输出中有无 E 标记;有 E 标记就说明堆栈段是可执行的,其中,
stack-overflow1-test 为我们编写的简单栈溢出测试程序,源码如下:
这是一个典型的存在缓冲区溢出漏洞的程序,greeting 函数定义了一个只有20字节大小的字符数组(缓冲区),strcpy 函数不检查用户输入的第二个参数(由 main 函数的第二个参数传递)是否超过20字节,就写入这个缓冲区中
我们用 gcc 默认参数配置来编译这个源文件,然后检查堆栈段的可执行性:
可以看到, -Wall 选项(参考前文解释)显示所有的警告和错误信息,对于增加程序的可移植性非常有帮助,例如它指出在源码的二行,greeting 自定义函数没有定义返回类型,将采用默认返回类型:int
另外,在 greeting 函数中,调用 strcpy 函数前未声明和定义(在程序中调用 strcpy 函数需要包含系统头文件 string.h)
同样,我们没有为 main 函数指定返回类型
在上面的例子中,虽然每个警告都非致命的语法或词法错误,但是 -Wall 选项确实可以“强制”培养程序员的良好编程习惯
言归正传,检查生成的二进制可执行文件:
其中没有 E 标记,这说明该程序即便存在溢出漏洞,但是由于 GCC 的堆栈段不可执行保护机制,该漏洞也没有太大被利用的可能性
我们“故意”关掉 GCC 的堆栈段不可执行保护机制:指定 -z execstack
选项,再次编译源文件:
这次的输出中,带有 E 标记,说明堆栈段是可执行的,
再次强调,在 CentOS6.5 中,要真正能利用这个程序测试你编写的 shellcode ,需要执行下面操作:
本博文包括对下面书籍的学习笔记,以及实际上机编程练习,程序运行分析等的总结,作为日后工作的参考:
《UNIX 环境高级编程(第三版)》
《深度探索 Linux 操作系统:系统构建和原理解析》
《深入理解计算机系统(原书第二版)》
一个典型的 Linux 进程“能看到”的虚拟地址空间如下图:
从第一张图可以看出:
每个 Linux 程序都有一个“运行时存储器映像”(即进程的虚拟地址空间),在 32位 Linux 系统中,代码段(上图中的 .text 节,准确的名称应为 .text 段,“节”是磁盘上程序代码的叫法;“段”是程序代码载入内存后的叫法,因此上图有些不准确)总是从地址 0x08048000
处开始;
数据段(上图中的 .data 节,准确的名称应为 .data 段)是在接下来的下一个 4KB 对齐的地址处;
(4096 dec = 1000 hex,0x08048000 + 0x00001000 = 0x08049000 )
运行时“堆”在数据段之后的第一个 4KB 对齐的地址处,并在调用 malloc() 库函数时,往内存高址段增长;
还有一个“段”,是为共享库保留的(静态库与共享库的区别将在后面解释);
用户栈总是从最大(高)的合法内存地址开始,向内存低址(下)增长的;
用户栈上方的“段”是为操作系统驻留存储器的部分(内核)的代码和数据保留的;
从第一张图可以看出,指针是特殊的内存块,其中存放着其它内存块的地址,叫做指针的值;
指针自身也有地址,因为32位处理器用于寻址的地址总线为32位宽,所以内存地址的长度为32位(4字节),这意味着,指针自身必须占用连续的4字节内存地址,然后每个1字节的内存地址存放目标内存块的1字节内存地址;
换言之,指针自身占用4字节的内存地址;这4个1字节的存储区域用于存放其它内存地址,即指针值
以第一张图为例,假设将
0xbfe2c6e8 ~ 0xbfe2c6e5 这连续4字节的内存单元定义为指针,那么当指针指向另一个内存块的地址时,假设指针指向
0xbfe2c6e0 这个内存地址,那么存储规则如下:
(假设计算机为运行 32 位 Linux 的 Intel IA32 架构 CPU,小端法机器)
地址 0xbfe2c6e8 存储字节 e0
地址 0xbfe2c6e7 存储字节 c6
地址 0xbfe2c6e6 存储字节 e2
地址 0xbfe2c6e5 存储字节 bf
注意,在基于 64 位 Linux / Intel x86-64 CPU 这种操作系统/处理器架构的计算机上,指针的长度为8字节
*****如果声明一个指针却没有初始化,那么,这个指针自身可能位于声明它的函数所在的栈帧中的某个4字节连续地址,但是,这4字节连续地址存储的内容,即指针值,或者叫指针指向的内存地址,却是在进程虚拟地址空间的 .bss 节,
也就是说,在离栈区很远(往内存低址方向)的 .bss 节中,分配存储空间,其中没有内容(未初始化,或者保留了之前未清除的不明数据)
为了能透彻理解这一点,考虑如下 C 源码:
0xbf9e6054 开始的4字节地址
(参考第一张图,以 0xbf 开头的内存地址,就是函数调用时展开栈帧使用的地址段)
但是这里我们没有对 pointer_to_hoge 进行初始化,所以它指向一个离自己“家里”(声明它的 main 函数的栈帧)很远的地方——地址
0x08048229 处,
通过 * 符号对 pointer_to_hoge 进行解引用操作后,我们发现
这个地址存储的数据(0x696c5f5f)是未知的,可能是前面程序留下的垃圾数据;
从第一张图可以看出:
一,这2个地址至少相距 3 GBytes 以上,验证计算:
[b]0xbf9e6054 - 0x08048229 = b799de2b ,
[/b]
0x[b]b799de2b(hex) = 3080314411(dec),[/b]
3080314411 Bytes = 3.08 GBytes
这似乎说明了 Linux 操作系统为每个进程维护“虚拟的” 4 GBytes 地址空间,
3 GBytes 以上的地址空间为内核部分(参考第一张图)
二,以 0x08048000 开头的内存地址,为
.text 节,用于存储从磁盘加载进来的相应二进制机器代码程序,
这个结果意味着,从 0x08048000 开始,向内存高址方向偏移229字节,就是进程虚拟地址空间中,用来存储未初始化变量的地方,即
.bss 节
在第一张图中,每个进程都有一个叫 .text 节的地址空间“段”
在用类似 gcc 等编译器编译程序时,在链接阶段,不论是调用库函数中的机器代码,还是从自行编写源程序生成的机器代码,都会被链接器链接在一起,最终,由链接器
ld 生成的二进制可执行机器代码存储在磁盘上,并且在程序运行时将磁盘上的相应文件加载到内存中的 .text 节
关于 .text 节 的更多内容,请考虑如下源码:
my_LS_command_implement.c
一书中第4页的内容,这是作者自己实现的一个 ls 命令的源码,
这个简单的 ls 命令,虽然不能像系统的 ls 命令那样通过解析用户输入的参数选项,显示文件的大小,类型,权限,I节点,而且也不能对列出的条目进行从 a~z 的名称排序,但它所涉及的 UNIX 相关知识和编程技巧,已经足够我们临摹的了
apue.h 头文件是作者自定义的一个头文件,其中引入了许多系统编程必备的 UNIX 和 C 标准头文件,这样做的目的在于缩小源码的体积,如果你想测试这里给出的源码,apue.h 是必不可少的,否则 gcc 编译器无法找到结构体 DIR 的定义,找不到 err 前缀的错误处理函数定义,
下面给出该头文件的内容,因为作者在该书附录中没有将他自行编写的错误处理函数(标准出错例程)和 apue.h 整合在同一个头文件中,因此我提供一个稍加整理后的 apue.h 版本,其中带有标准出错例程的定义,
简单的讲,引入下面这个文件就能解决大多数的系统头文件重复包含,递归包含等问题,并且能正常运行本博文后续给出的其它源码(当然,对于本例而言,还需要引入
dirent.h 头文件,它的位置在
/usr/include/dirent.h 与
/usr/include/bits/dirent.h )
apue.h 头文件源码(整理版)
当程序作为守护进程运行时,需要有另外的出错例程(函数)来处理守护进程可能输出的信息,例如与 syslog 进程通信并记录到日志等,
限于篇幅,这里没有整合相应的源码,有兴趣的童鞋,请参考
《UNIX 环境高级编程(第三版)》一书中,第727页开始的内容
my_LS_command_implement.c 程序的功能很简单,它通过用户在 shell 命令行中指定的绝对路径,来列出该目录下的内容
该程序第7,8行分别定义了 DIR 结构型指针与 dirent 结构型指针,用于指向后面
opendir() 与 readdir() 函数返回的内容;
结构型变量)赋给 dirp 指针并判断:如果 readdir() 读取完目录中的所有文件和子目录,此时 dirp 为空指针,退出循环;反之,每当 readdir() 成功读取目录中的一个文件或子目录,就打印该文件或目录的名称(通过访问 dirp 指向的 dirent
结构型的 d_name 成员,该成员存储名称)
假设,我们在编程时特意将上面的一个库函数 closedir() 的名称拼写错误来调用,那么在链接阶段,ld 会提示出错如下:
*****补充资料,关于 Linux 进程管理的基础知识:
进程是正在运行的程序,进程可以申请并占用系统的运行资源,是 Linux 系统的“基本调度单位”。
程序是静态的保存在磁盘上的可执行代码和数据的集合,不会占用系统的运行资源(CPU与内存)
内核使用 exec 函数,将程序读入内存并且执行
理论上讲,单个物理CPU在同一时间内只能运行一个进程(准确的说是执行该进程内的机器指令)
Linux 操作系统通过将CPU的资源(占用CPU)划分成很小的时间块,根据不同进程的“优先级”,为每个进程分配不同的时间片(即占用CPU资源的时间)。
每个时间片(即进程占用CPU的时间)约仅有0.x 秒,但是因为现代高性能微处理器的每秒可执行机器指令数在百万条(MIPS)以上,
因此足以让单个进程运行几十万条机器指令,
然后操作系统充分利用了高速处理器的MIPS特性,通过短时间在多个进程间快速切换来分配CPU时间(即任务调度,执行不同进程的机器指令),
实现了在极短时间内,多数进程的大部分机器指令都得以被CPU执行,这就给最终用户造成一种好像同时执行许多任务的假象。
每个进程运行一段时间后,系统根据该进程的运行(处理)进度将其“挂起”,系统转而处理其它进程,再经过一段时间再回来处理该进程,如此反复直到该进程处理完。
分别以进程的视角,内核的视角来观察计算机系统
(摘录自《Linux/UNIX 系统编程手册上册》,ISBN 978-7-115-32867-0)
一个运行系统通常会有多个进程并行其中。对进程来说,许多事件的发生都无法预期。执行中的程序不清楚自己对 CPU 的占用何时“到期”,系统随之又会调度哪个进程来使用 CPU ,以及以何种顺序来调度;进程也不知道自己何时会再次获得对
CPU 的使用。
信号的传递和进程间通信(IPC)事件的触发由内核统一协调,对进程而言,随时可能发生。
诸如此类,进程都一无所知。进程不清楚自己在物理内存地址空间(RAM)中的位置,它仅仅能看到由内核虚拟的地址空间。换言之,进程看到的虚拟地址空间的“某块”特定部分当前究竟是驻留在 RAM 中,还是被保存在交换空间(用磁盘上的特定存储区域作为对 RAM 的补充)里,进程本身并不知道;
与此类似,进程也搞不清,自己通过抽象的树形文件目录引用的文件,究竟位于磁盘驱动器上的哪个盘片,哪个磁道,哪个扇区;
进程的运作方式堪称“与世隔绝”——进程间彼此不能直接通信。进程本身无法创建出新进程,哪怕“自行了断”都不行;另外,进程也不能与计算机外接的输入输出设备直接通信。
相较之下,内核则是运行系统的中枢所在,对于系统的一切无所不知,无所不能,为系统上所有进程提供便利,提供服务。
在内核看来,进程是一个个的实体,内核必须在它们之间共享各种计算机资源;
对于像内存这样的“受限资源”,内核一开始会为进程分配一定数量的资源,并在进程的生命周期内,统筹该进程和整个系统对内存资源的需求,对这一分配进行调整,程序终止时,内核会释放其占用的内存资源,供其它进程重新使用。
其它资源(如 CPU ,网络带宽等)属于“可再生资源”,但必须在所有进程间平等共享;
由哪个进程来接掌对 CPU 的使用,何时“接任”;“任期”多久,都由内核说了算。
在内核维护的数据结构中,包含了与所有正在运行的程序有关的信息;
(就在 /proc/ 目录下,以各自进程 ID 命名的子目录中)
随着进程的创建,状态发生变化或者终结,内核会及时更新这些数据结构。
内核所维护的底层数据结构可以将进程使用的文件名(通过抽象的树形文件路径引用)转换为磁盘的物理位置(找出所在柱面,磁道,扇区)
此外,每个进程的虚拟地址空间到物理内存地址之间的映射,以及与磁盘上用于交换空间的映射,也在内核维护的数据结构之列。
进程间的所有通信,都要通过内核提供的通信机制来完成(以 Linux 内核为例,IPC 机制包含:信号;管道;套接字;消息队列,信号量,共享内存,文件锁。。。等等)
为了响应进程发出的请求,内核可以创建新的进程,终结现有进程。
最后,由内核(特别是其设备驱动程序模块)来执行与输入输出设备之间的所有直接通信,按需与用户进程交互信息。
下面用一个实例源码来展示前面提到的,与内核提供的进程控关制机制相的知识,其在编程中的实际应用;
这个实例是最简单的命令行解释器(shell)的实现:它解释用户输入的命令,并向内核申请创建一个子进程,由后者执行系统调用,从而请求内核加载并运行用户输入命令的对应可执行文件:
process_control.c
第2行引入的 wait.h 头文件,位于 sys 目录下,这是一个相对路径,对于大多数的 Linux 发行版而言, sys/wait.h 等同于 /usr/include/sys/wait.h;该头文件中,将
waitpid() 声明为外部函数(extern),在第27行调用该函数;
这个程序在单个 main() 中实现了简易的命令行解释器功能;
第6行声明一个长度为4096字节的字符数组 buffer,用来保存用户输入的命令字符串,关于MAXLINE 的宏定义在 apue.h 中,其值正好为 4096;
第7行的 pid_t 类型,在 apue.h 引入的 /usr/include/sys/types.h 中,涉及
pid_t 在多个系统头文件之间的递归宏定义,最终这个类型就是 int;
第10行首先打印1个 % 符号的用意在于区别真正的命令行解释器,如 bash;
(实际打印的是第二个 % ,第一个 % 用于指定其后要打印的字符串格式)
第12到31行正是实现简易命令行解释器的关键代码,其在一个 while 循环中,
反复调用 fgets() 这个 C 库函数(在 apue.h 引入的 stdio.h 中声明),从 stdin(标准输入,这里指虚拟终端)一次读取用户键入的一行字符串(即命令),将其存储在数组 buffer 中,如果用户按下 ctri + d 组合键,那么 fgets() 读取到的第一个字符将是 NULL ,此刻符合 while 循环的退出条件,于是 process_control 进程终止;
因为用户输入完命令的最后会按下回车键,因此 fgets() 返回的每一行(即字符串)的倒数第二个字符都是换行符('\n'),并以 NULL 字符('\0')结束;
所以此刻 buffer 数组中的倒数第二个字符为换行符;最后一个字符为 NULL 字符;
由于第20行的 execlp() 参数仅接受以 NULL 字符结束的变量(buffer 数组中的倒数第二个字符被视为结束符,但它当前为换行符),因此第13到14行检查,并将换行符替换为 NULL 字符,即 0;
从第16行~20行的代码可以看出,该程序(父进程)在最终向内核申请加载并执行与用户输入命令对应的二进制文件前,以系统调用 fork() 创建一个子进程,然后由子进程通过调用 execpl() 向内核申请该操作;注意,fork() 向父进程返回子进程的 pid;向子进程返回 0,这就是第18行的 if 判断的用意所在:指定通过子进程调用 execpl();
而父进程在执行系统调用 fork()创建子进程后,希望等待子进程终止(无论子进程作了什么事),这就是第27行调用 waitpid() 的目的,并且判断其返回的值(代表子进程的终止状态),如果返回值小于 0 ,表示子进程没有正常退出,因此调用自定义的错误处理函数,打印出错提示;
注意,第30行的 printf() 是在 while 循环体中调用的,这意味着,子进程如果正常退出,表示其成功解释执行了用户输入的命令(真正执行的是内核),然后父进程继续调用 fgets(),等待并读取用户下一次的命令输入,如果用户按下 ctrl + d
组合键,此时满足循环结束条件,程序执行流程来到第33行的 exit(0),即退出程序。
下面的内容可以帮助理解上面这个类似shell的程序的工作原理:
1.当用户在外壳 (shell) 运行一个程序时,父外壳进程通过 fork() 系统调用转入内核空间,后者创建一个子进程,它是父进程的一个复制品,有着和父进程完全相同的虚拟地址空间映射,这样就可以将父shell进程的环境变量传递给子进程。fork() 对父进程返回新的子进程的进程 ID(一个非负整数),对子进程则返回0,因为
fork() 创建一个新进程,所以说它被调用一次(由父进程),但返回2次(分别在父进程和在子进程中)
fork() 在子进程中返回0后,子进程通过类似 execve()/execpl() 的exec家族系统调用再次转入内核空间,内核首先识别通过exec族函数参数传入的欲执行的二进制文件(即用户在shell中输入的命令名)是否为它支持的格式,识别任务一般由search_binary_handler函数进行,当识别出 ELF 文件格式后,内核将子进程虚拟地址空间中,除环境变量外的所有段内容用0擦除(不会擦除该进程内核空间的内容)。
另一方面,父shell进程希望等待这个“变身”成其它程序进程的子shell进程执行后终止,因此在上面源码中过调用 waitpid() 实现检查子进程是否正常退出。其参数指定要等待的进程(即 pid 参数为子进程 PID)。waitpid() 返回子进程的终止状态(status)变量。
注意,某些程序在shell中执行时,会“阻塞”父shell进程,也就是shell无法继续处理用户后续的命令输入,可以通过在执行这种会阻塞shell的程序名后面加上符号 & ,该程序就会转入后台运行,这样当前shell可以继续监视用户的命令输入。
另外,实际的 shell 实现,例如 bash ,还会检查用户输入的命令是否为一个内置的 shell 命令,如果不是,则该命令被看成一个可执行目标文件,并且bsah会尝试在环境变量 PATH 指定的磁盘路径中搜索该文件是否存在,如果找到了,才会进行第2步
2.加载。内核执行加载器模块如load_elf_binary(),后者首先读取 ELF 文件中“段头部表”(section header table)的内容,根据其内容,加载器将磁盘上的可执行 ELF 文件中的 .text 节, .data 节,拷贝到被擦除的子进程内存映像中对应的代码(.text)与数据(.data, .bss)段内。
也就是说,在执行静态链接的程序时,加载器的作用就是将链接器创建的各种文件节从磁盘复制到虚拟内存映射中的相应段内。
3.执行。加载器跳转到子进程虚拟地址空间中,程序的入口地址(也就是从调用exec时进入的内核空间再次返回到用户空间),通常是 .text 段的地址,其中包含了 _start 符号标识的地址,在 _start 地址处的启动代码 (startup code): __libc_init_first 是第一个被调用的函数(机器代码的形式),它是在“共享”目标文件 ctrl.o 中定义的,__libc_init_first 调用 .init 段中的 _init 例程(函数),后者执行一些初始化工作,当 _init 退出后,__libc_init_first
调用 atexit 例程,后者加入一些在应用程序(main函数)正常终止的时候,额外调用的程序,atexit 例程退出后,启动代码调用 main 函数(实际运行应用程序),main 函数退出后,启动代码调用 _exit 例程,后者将“对 CPU的控制权”返回操作系统
******在Windows和Linux等现代操作系统中 ,有时候第2步还不会复制可执行文件的代码和数据到shell子进程的地址空间中,而是等到第三步跳转到程序入口点执行时,CPU通过EIP寄存器取出某条指令的虚拟地址,然后将虚拟地址交给芯片内的MMU(地址翻译单元),MMU利用存储在PTBR(页表基址寄存器)中的,由操作系统维护的页表物理起始地址,来查询该指令的虚拟地址位于哪个物理内存页中,然后,在CPU向这个物理内存页的起始地址取出指令或数据之前,加载器赶紧把当前还位于磁盘上ELF文件中对应的代码或数据节,复制拷贝到该物理内存页。
为了验证 fork() 创建一个新的子进程,我们先将上面的源文件用 gcc 将其编译成名为 process_control 的可执行目标文件,然后在真实的 shell 中执行该程序;
此时,process_control 程序的执行流程对应于源码第10行,也就是打印一个 % 字符,等待用户输入命令,此时只有一个进程,即父进程,它并不会调用 fork() 请求内核创建子进程;
打开另一个 shell 终端,在其中执行命令 ps fwwaux | grep 'process_control'
可以看到,该程序运行时的进程树中,仅有一个进程;
有的童鞋可能认为:只要在 process_control 运行时,输入命令,让它创建一个子进程来执行命令,再以 ps fwwaux | grep 'process_control' 查看进程树,应该就能找到子进程的信息;
理论上是如此,但是要记得,当子进程执行 execve() 系统调用时,它的虚拟地址空间会被内核“重构”,用来加载并执行命令,当命令执行完毕,子进程退出,父进程继续“监听”用户的输入;
上述过程,即从 fork() 到 execve() ,再到子进程退出,虽然涉及从用户模式代码到内核模式代码,再到用户模式代码的转换与执行,其经历时间却非常短暂,以当代高性能处理器的 MIPS (每秒可以执行的机器指令数量,以百万条为单位)而言,你无法通过 ps fwwaux 查看到子进程在其“生存时间”内的信息。
这就是我们在源码第19行添加注释语句 sleep(10000); 的原因,它的作用在于,创建子进程后,让其“睡眠”一万毫秒(10秒),在此期间,子进程不会调用 execpl()(execve()),导致用户输入的命令成功执行后,子进程退出;
限于篇幅,关于 sleep() 的内幕,有兴趣的童鞋请自行搜索文献信息,这里不作介绍;
取消注释第19行的代码(保留后面文字说明的注释状态),重新编译process_control.c 源文件,生成
process_control 程序,在一个 shell 终端执行该程序,然后在带有 % 字符的仿真 shell 中,输入任意命令,如 ls ,并按下回车键,你可以发现,必须等待10秒,才会输出 ls 的执行结果;
(限于具体的 Linux 实现,这里 ls 命令可能不会输出结果,子进程“永久”进入睡眠状态)
但是,只要你动作够快,在这10秒内打开另一个真实 shell 或切换到另一个虚拟终端,执行命令
ps fwwaux | grep 'process_control' ,你就能看到有2个
process_control 进程,它们在进程树中为父子关系存在;这表明第19行的代码确实起到了作用,同时也验证了 fork() 系统调用创建新的进程这一事实:
process_control 程序的重命名版本)
可以看到,
PID 为 6362 的进程是 PID 为 6361 的进程的子进程,生成这两个进程的命令均为
在当前路径下执行 unix_process_control_use_fork()_and_exec() 程序。
一个典型的类 UNIX 系统体系结构如下图:
在第二张图中,我们看到“公用函数库”的概念,在 Linux 系统上,这是指包括 Glibc 在内的 C 语言函数库,
有些 glibc 中的库函数使用系统调用来编写,例如,
库函数 fopen() ,使用系统调用 open() 来执行打开文件的实际操作;
但是,有些库函数不使用任何系统调用(字符串操作函数),完全自己实现相应功能;
如图所述,设计与实现库函数的目的,在于提供比底层系统调用更方便的 API,将复杂编程任务化繁为简;
例如, printf() 库函数支持格式化输出与数据缓冲,而
write() 系统调用仅能输出字节块;
同理,与底层系统调用 brk() 相比,库函数
malloc() 与 free() 还执行各种登记管理动作,内存的分配与释放因而容易许多
(以上内容取自《 Linux/UNIX 系统编程手册(上册) 》)
在 C 语言函数库中,有一组专用于 I/O 操作的函数,也称为 stdio 函数库,
包括如下一些常见的函数:
fopen(),fclose(),scanf(),printf(),fgets(),fputs()
以上这些 stdio 函数都构建于内核提供的接口函数(即系统调用):open(),close(),read(),write()之上
当前的新版 gcc 编译器(4.9.1)支持在 2011 年 ISO 发布的 C 语言标准最新版:ISO C11
在编译程序时,可以通过传递给 gcc -std=c11 参数,来指定它按照 C11 的标准编译程序,其余可用的参数值有:
-std=c99 对应 ISO 在1999年公布的 C 语言的 ISO C99 标准
下面这两个参数实际上是同一个C语言标准,效果相同,称为 ISO C89 或者 ANSI C 标准
-std=c89
-ansi
-std=gnu99 由 GNU 项目制定的,涵盖 C99 和其它一些特性的 C语言标准
例如,要以 ISO C99 语法标准来编译前面自己实现的 ls 命令源码:
gcc 也支持一个称为 -Wall 的选项,向用户输出编译过程中的错误(error)和警告(warning)信息,便于调试程序和修正源代码,结合前面的命令一起使用:
CLANG,我们可以在 FreeBSD 的
Bourne shell(位于 /bin/sh 路径,由贝尔实验室的 Steve Bourne 开发,所有类 UNIX 的默认 shell)提示符下,输入
注意,在所有的 Linux 发布版中,默认安装的 C 编译器是 GCC:
一,对于 Ubuntu 12.04 ,可以在 BASH(Bourne-again shell,GNU 项目开发出来的 shell,也是所有 Linux 发布版的默认 shell 之一)的提示符下,输入
二,对于 RedHat6.5 / CentOS6.5 ,必须在 BASH 的提示符下,输入
*****拓展知识:Glibc 与库函数
Glibc( GNU C 语言函数库 )是 Linux 平台上最常见的标准 C 语言函数库实现
各种类 UNIX 平台,有各自不同的标准 C 语言函数库实现
Linux 平台上其它 C 语言函数库实现,包括用于嵌入式移动设备,受限制存储空间条件下的
uClibc 和 dietlibc C 语言函数库等:
uClibc: http://www.uclibc.org/
dietlibc: http://www.fefe.de/dietlibc/
当我们需要确定 Linux 系统上安装的 glibc 版本时,在 shell 中执行如下命令,直接运行
glibc 共享库文件,来获取其版本:
该版是在一个基于 Linux 内核 2.6.32 的计算机上,通过 GNU 的 CC (C编译器)版本 4.4.7 进行编译的;
包括一些可用的扩展,如加密插件,原生的 POSIX 标准线程库等等
在某些 Linux 发行版中,glibc 共享库文件并非存放在上述路径,此时可以用
rpm 命令来查询:
或者,我们通过查询某个可执行文件在运行时,都链接到哪些共享库的方式,来找出 glibc 共享库文件的存储路径:
/lib/libc.so.6
我们顺藤摸瓜:
可以看到,libc.so.6 仅仅是一个符号链接,
它指向同目录下的 libc-2.12.so,后者才是真实的 glibc 共享库,可以采用如下办法验证:
另外,以 du 命令计算文件大小信息时,不接任何参数,默认以 KBytes 为单位显示; -b 参数指定以 Bytes 显示; -m 参数指定以 MBytes 显示
理解上面知识点非常重要
*****用于阻止缓冲区溢出攻击的 Linux 内核参数与 gcc 编译选项
先来看看基于 Red Hat 与 Fedora 衍生版(例如 CentOS)系统用于阻止栈溢出攻击的内核参数,主要包含两项:
kernel.exec-shield
可执行栈保护,字面含义比较“绕”,
实际上就是用来控制能否执行存储在栈
中的代码,其值为1时表示禁止;为0时表示允许;默认为1,表示禁止执行栈
中的代码,如此一来,即便覆盖了函数的返回地址导致栈溢出,也无法执行
shellcode
查看与修改系统当前的可执行栈保护参数:
一,只有在学习和测试栈溢出攻击的原理时,才建议关闭可执行栈保护机制
二,在基于 Debian 与 Ubuntu 衍生版
(例如 BackTrack 5 Release 3)的系统上,不支持可执行栈保护机制:
kernel.randomize_va_space
堆栈地址随机初始化,很好理解,就是在每次将程序加载到内存时,进程地
址空间的堆栈起始地址都不一样,动态变化,导致猜测或找出地址来执行
shellcode 变得非常困难,它和可执行栈保护的区别在于,后者即便是找到了
地址也是无法执行的;所有的 2.6 以上版本的 Linux 内核都支持并启用了
这一项特性;
查看与修改系统当前的堆栈地址随机初始化参数:
基于 Debian 与 Ubuntu 衍生版默认支持并且启用了随机地址功能:
入口地址:
(默认情况下,编译时不会指定这两个参数,用于阻止缺乏安全编码意识的程序员写出存在缓冲区溢出漏洞的程序,
但是站在逆向工程的角度来看,指定这两个参数,特意构造有漏洞的程序,对于学习和理解栈溢出的原理还是有帮助的;
再次提醒,这里介绍的两个编译参数必须同时打开,而且还要同时禁用前面讲的可执行栈保护与栈地址随机初始化,满足这4个条件后,一般而言,就可以测试 shellcode 的效果了
)
GCC 编译选项 -fno-stack-protector
禁用栈保护功能,默认是启用的;
gcc 的栈保护机制是指,在栈的缓冲区(大小通常由程序员给定)写入内容前
,在结束地址之后与返回地址之前,放入随机的验证码,由于栈帧是从内存高
址段向内存低址段增长的(回顾第一张图),结束地址在高址段;返回地
址在低址段,栈溢出时,会从高址段向低址段覆盖数据,因此如果想要覆盖返
回地址的内容,必定先覆盖结束地址,验证码,才能覆盖返回地址,
因此可以通过比较写入缓冲区前后的验证码是否发生改变,来检测并阻止溢出
攻击
GCC 编译选项 -z execstack
启用可执行栈,默认是禁用的;
该选项与
ld 链接器有关:ld 链接器在链接程序的时候,如果所有的 .o 文
件的堆栈段都标记为不可执行,那么整个库的堆栈段才会被标记为不可执行;
相反,即使只有一个 .o 文件的堆栈段被标记为可执行,那么整个库的堆栈段
将被标记为可执行,
换言之,默认是所有的 .o
文件的堆栈段都标记为不可执行
检查堆栈段可执行性的方法是:
stack-overflow1-test 为我们编写的简单栈溢出测试程序,源码如下:
我们用 gcc 默认参数配置来编译这个源文件,然后检查堆栈段的可执行性:
另外,在 greeting 函数中,调用 strcpy 函数前未声明和定义(在程序中调用 strcpy 函数需要包含系统头文件 string.h)
同样,我们没有为 main 函数指定返回类型
在上面的例子中,虽然每个警告都非致命的语法或词法错误,但是 -Wall 选项确实可以“强制”培养程序员的良好编程习惯
言归正传,检查生成的二进制可执行文件:
我们“故意”关掉 GCC 的堆栈段不可执行保护机制:指定 -z execstack
选项,再次编译源文件:
再次强调,在 CentOS6.5 中,要真正能利用这个程序测试你编写的 shellcode ,需要执行下面操作:

相关文章推荐
- CentOS7.1 下RPMBUILD环境配置及内核rpm包作成
- Centos 7下一键安装ffmpeg 的经验
- Linux 命令之last命令详解
- linux下重命名文件或移动文件夹
- Linux内核源码分析--内核启动
- Linux 下 strace 命令用法总结
- centos安装jdk1.7
- CentOS 6.5 实现挂载 ntfs格式的硬盘
- linux 目录大小
- Centos6.5 iptables配置详解
- selinux m4语言语法
- snapd 进入Arch Linux社区软件库(community Repo)
- linux命令 cat
- linux 内核与用户空间通信之netlink使用方法
- arm-linux-3.4.2移植for2440
- VM虚拟机中CentOS6.4操作系统安装一
- CentOS7.1下targetcli的使用
- 运维老鸟教你安装centos6.5如何选择安装包
- Linux strace命令
- linux 路由表功能解析