文本相似度计算
2016-07-04 10:18
288 查看
一、简介
文本相似度是进行文本聚类的基础,和传统的结构化数值数据的聚类方法相似,文本聚类是通过计算文本之间的“距离”来表示文本之间的相似度,并产生聚类。文本相似度的常用计算反法有余弦定理。但是文本数据和普通的数据不同,它是一种半结构化的数据,在进行聚类之前必须要对文本数据源进行处理,如分词、向量化表示等,其目的就是使用向量化的数值来表达这些半结构化的文本数据。使其适用于文本分析。
二、TF-IDF算法
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文本中出现的次数(该次数一般会归一化处理,以防止它偏向长文本)。
在给定的文件里,词频

其中,
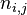
表示该词在文件
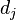
中出现的次数,分母是文件
中出现所有字词的总次数之和(即归一化处理)。
逆向文件频数(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再对商求对数。

其中:
D文件的总数
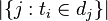
:包含词语
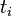
的文件数目,如果该词语不存在语料库中,就会导致除数为0,所以可以加一个扰动
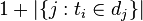
然后:
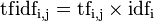
二、余弦定理
文本1中出现的字:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn
它们在文本1中出现的个数:Z1n1,Z1n2,Z1n3……Z1nm;
文本2中出现的字:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn
它们在文本2中出现的个数:Z1n1,Z1n2,Z1n3……Z1nm;
那么相似度为:
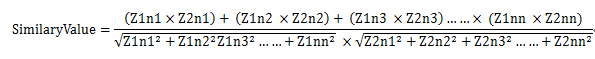
三、Jaccard Similarity
该方法简单,易实现,实际上就是两个集合的交集除以两个集合的并集,所得的就是两个集合的相似度,直观看就是下面的这个图

例如,有world和could两个文本,设k为2通过k-shingle拆分以后,分别变成了[wo,or,rl,ld]和[co,ou,ul,ld]那么他们的特征矩阵就是

通过特征矩阵,很容易看出来,两个文本的相似度是他们公共元素除以所有元素,也就是1/7
,也可以把特征矩阵修改一下,列上面存储的是该集合中词语出现的个数,这样可靠性更高一些
文本相似度是进行文本聚类的基础,和传统的结构化数值数据的聚类方法相似,文本聚类是通过计算文本之间的“距离”来表示文本之间的相似度,并产生聚类。文本相似度的常用计算反法有余弦定理。但是文本数据和普通的数据不同,它是一种半结构化的数据,在进行聚类之前必须要对文本数据源进行处理,如分词、向量化表示等,其目的就是使用向量化的数值来表达这些半结构化的文本数据。使其适用于文本分析。
二、TF-IDF算法
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文本中出现的次数(该次数一般会归一化处理,以防止它偏向长文本)。
在给定的文件里,词频
其中,
表示该词在文件
中出现的次数,分母是文件
中出现所有字词的总次数之和(即归一化处理)。
逆向文件频数(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再对商求对数。
其中:
D文件的总数
:包含词语
的文件数目,如果该词语不存在语料库中,就会导致除数为0,所以可以加一个扰动
然后:
二、余弦定理
文本1中出现的字:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn
它们在文本1中出现的个数:Z1n1,Z1n2,Z1n3……Z1nm;
文本2中出现的字:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn
它们在文本2中出现的个数:Z1n1,Z1n2,Z1n3……Z1nm;
那么相似度为:
三、Jaccard Similarity
该方法简单,易实现,实际上就是两个集合的交集除以两个集合的并集,所得的就是两个集合的相似度,直观看就是下面的这个图
例如,有world和could两个文本,设k为2通过k-shingle拆分以后,分别变成了[wo,or,rl,ld]和[co,ou,ul,ld]那么他们的特征矩阵就是
通过特征矩阵,很容易看出来,两个文本的相似度是他们公共元素除以所有元素,也就是1/7
,也可以把特征矩阵修改一下,列上面存储的是该集合中词语出现的个数,这样可靠性更高一些

相关文章推荐
- 有容云:DevOps 的起点-入手微型数据中心(上)
- SEO
- Android序列化:Serializable和Parcelable
- build\tools\buildinfo.sh
- 图片上传预览功能
- SpringMVC 拦截器
- Android View系统源码分析(七)—— View.refreshDrawableState()
- 计算机原理(四)
- MYSQL日期增减 2016.07.01回顾
- 图像的泊松(Poisson)编辑、泊松融合完全详解
- 讨论“get”和“post”安全性
- IP地址分类及ISO-OSI、三次握手
- (swift)UICollectionView方法/属性详解
- 创业1
- 从数据库导出数据
- PHP读书笔记(6)- 数组
- React-Native学习指南
- dba基础课程-linux操作系统:系统信息命令
- MQTT协议
- 计算机原理(三)