基于历史数据查询的爬虫操作
2016-07-03 13:26
387 查看
网站:http://www.szmb.gov.cn/article/QiXiangJianCe/目的:抓取过去一年内深圳各个区的逐小时降雨数据历史查询需要通过网页中的日历控件选择,而且日历控件只有在点击日期之后才会生效,也就是说,要查询2016年7月3日12:00的数据,需要先点击日历,然后通过小时和分钟的加减获得12:00,再选择年、月和日。这样的操作能通过selenium实现,困难在于,该网站设置该日历控件的输入值type=“hidden”,且设置日期的属性unselectable=“on”,display=“none”。也就是说,无法通过selenium实现模拟人的点击操作。因此尝试以下方法:1.设置该input的type为text型,而不是hidden类型。再通过selenium的send_keys方法输入新的日期值,并submit。结果:失败。原因:设置input的value并没有用,因为input的value值是通过其他方式赋值的,不会对查询操作有任何影响。2.模拟点击操作。如上所述,失败。以上两种方法折磨了我一晚上+一上午。3.人工点击,并监听浏览器的get和post行为。果然,发现在控制台出现如下操作: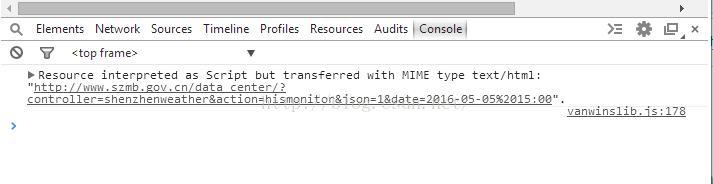 数据通过text/html传送,果不其然,js代码对数据的操作必须要有某种数据流实现与服务器之间的数据传递。点击日历的2016年5月5日15:00时,则试图返回的网页为:
数据通过text/html传送,果不其然,js代码对数据的操作必须要有某种数据流实现与服务器之间的数据传递。点击日历的2016年5月5日15:00时,则试图返回的网页为:
数据通过text/html传送,果不其然,js代码对数据的操作必须要有某种数据流实现与服务器之间的数据传递。点击日历的2016年5月5日15:00时,则试图返回的网页为:http://www.szmb.gov.cn/data_center/?controller=shenzhenweather&action=hismonitor&json=1&date=2016-05-05%2015:00
分析其结构组成发现其功能为查询深圳的监测站历史天气数据,返回格式为json,日期为2016-05-05%2015:00,%20显然代表空格。通过修改json=?后的值发现,当其为1时,返回的为json格式,当json=0时,返回的为标准的xml格式,这富裕数据查询十分方便。发现新大陆!
# coding=utf-8
# Created on 3 Jul, 2016
# Author: Liuph
# Version:1.0
import urllib
import urllib2
import re
import time
import os
import string
#下载html
def getHtml(url):
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
req = urllib2.Request(url, headers=headers)
html = urllib2.urlopen(req).read()
return html
#解析html
def getElement(html):
#日期时间
reg_date= r'(?<=\<date\>)(.+?)(?=\</date\>)'
#行政区
reg_area = r'area="(.+?)"'
#站点名称
reg_obt = r'obt="(.+?)"'
#小时降雨
reg_rain = r'(?<=\<rh\>)(.+?)(?=\</rh\>)'
#24小时降雨
reg_rain24 = r'(?<=\<r24h\>)(.+?)(?=\</r24h\>)'
re_date = re.compile(reg_date)
re_area = re.compile(reg_area)
re_obt = re.compile(reg_obt)
re_rain = re.compile(reg_rain)
re_rain24 = re.compile(reg_rain24)
elems_date = re.findall(re_date, html)
elems_area = re.findall(re_area, html)
elems_obt = re.findall(re_obt, html)
elems_rain = re.findall(re_rain, html)
elems_rain24 = re.findall(re_rain24, html)
if (len(elems_date) > 0):
output_file = open("his/" + str(elems_date[0])[0:13] + ".txt", 'w')
output_file.write(elems_date[0] + "\n")
for i in range(len(elems_obt)):
output_file.write(elems_area[i] + "," + elems_obt[i] + "," + elems_rain[i] + "," + elems_rain24[i] + "\n")
output_file.close()
Months = ['2015-07','2015-08','2015-09','2015-10','2015-11','2015-12','2016-01','2016-02','2016-03','2016-04','2016-05','2016-06','2016-07']
MaxDays = [31,31,30,31,30,31,31,28,31,30,31,30,3]
Hours = ['00','01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
for i in range(0,13):
_month = Months[i]
for _day in range(1,32):
if _day > MaxDays[i]:
continue
if _day < 10:
_day = '0'+str(_day)
else:
_day = str(_day)
for _hour in Hours:
DDateTime = _month + "-" + _day + '%20' + _hour +':00'
#时间:从2015年7月1日至2016年7月3日
url = 'http://www.szmb.gov.cn/data_center/?controller=shenzhenweather&action=hismonitor&json=0&date='+DDateTime
print url
html = getHtml(url)
getElement(html)
#exit()于是启动全程连接,开始开心地抓数据了!附上对实时抓取代码的更新(因为实时数据的一小时数据为当前小时的累积数据,所以设置每个小时的58~59分钟抓取最能满足1小时条件)
# coding=utf-8from testString import *from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport stringimport osimport timedistrict_navs = ['nav2','nav1','nav3','nav4','nav5','nav6','nav7','nav8','nav9','nav10']district_names = ['福田区','罗湖区','南山区','盐田区','宝安区','龙岗区','光明新区','坪山新区','龙华新区','大鹏新区']strTime = str(time.strftime("%Y%m%d%H%M", time.localtime(time.time())))flag = 1while (flag == 1):if (strTime[-2:] == '58'):driver = webdriver.Chrome()driver.get("http://www.szmb.gov.cn/article/QiXiangJianCe/")# 选择降雨量driver.find_element_by_xpath("//span[@id='fenqu_H24R']").click()filename = "data/"+strTime + '.txt'#创建文件output_file = open(filename, 'w')# 选择行政区for i in range(len(district_navs)):driver.find_element_by_xpath("//div[@id='" + district_navs[i] + "']").click()# print driver.page_sourcetimeElem = driver.find_element_by_id("time_shikuang")#输出时间和站点名output_file.write(timeElem.text + ',')output_file.write(district_names[i] + ',')elems = driver.find_elements_by_xpath("//span[@onmouseover='javscript:changeTextOver(this)']")#输出每个站点的数据,格式为:站点名,一小时降雨量,当日累积降雨量for elem in elems:output_file.write(AMonitorRecord(elem.get_attribute("title")) + ',')output_file.write('\n')output_file.close()driver.close()time.sleep(60)strTime = str(time.strftime("%Y%m%d%H%M", time.localtime(time.time())))

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- 爬虫笔记
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- Python 语言及其应用 Chapter_4_Note_4 装饰器