Storm并发机制详解
2016-07-02 15:45
357 查看
本文可作为 <<Storm-分布式实时计算模式>>一书1.4节的读书笔记
在Storm中,一个task就可以理解为在集群中某个节点上运行的一个spout或者bolt实例。
记住一个task是一个实例。 实例明白吧
Class Person 是一个类, persona,personb都是Person的一个实例。
在集群运行运行中,topology主要有四个组成部分。
他们从低到高分别是task(bolt/spout实例),Executor(线程),Workers(JVM虚拟机),Nodes(服务器)
task上面已经说过,task的nextTuple和execute方法会被executor线程调用
Executor是jvm进程中运行的一个java线程,多个task可以分配给同一个executor来执行。也就是说executor与task是一对多的关系。不过,除非明确指定,Storm会默认给每个executor分配一个task。默认是一对一。
Workers,指的是node上独立的jvm进程。每个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
Nodes,指配置在一个 Storm 集群中的服务器,会执行 topology 的一部分运算。一个 Storm 集群可以包括一个或者多个工作 node。
我们看下面的例子
程序执行完毕后,在控制台可以看到类似以下的输出:

很简单,就是就经典的数单词数量的topology,大家根据各个类的名字,应该也能猜出来内部的逻辑。
里面的代码,我就不贴出来了,大家自己都能找到很多。
我们知道在设置spout/bolt的时候如果不设置parallelism_hint,就默认为1
它的整体的并行图,如下:
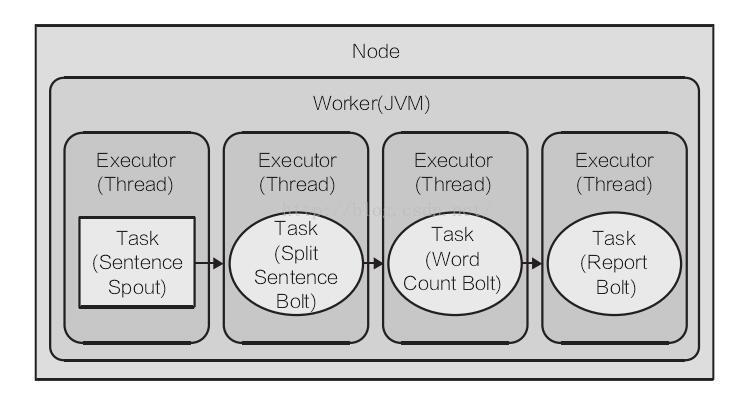
正如在图中看到的,唯一的并发机制出现在线程级。每个任务在同一个 JVM 的不同线程中执行。如何增加并发度以充分利用硬件能力?让我们来增加分配给topology 的
worker 和 executer 的数量。
配置executor和task
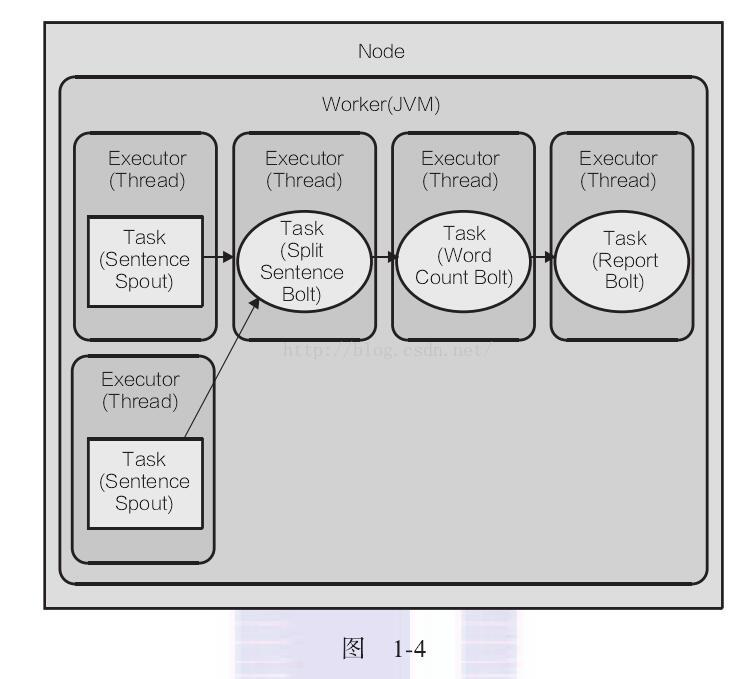
我们把 sentencespout的并发度调成2,并且worker不变。代码如下:
//这个2 指的是有两个executor 和task的数量无关 不过在这行代码里,我们没有指定task的数量,因为executor为2 那么task也就是2
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
那么它的并行图如下:
配置worker数量
这个很简单,我们在config里设置一下就OK
Config config = new Config();
config.setNumWorkers(2);
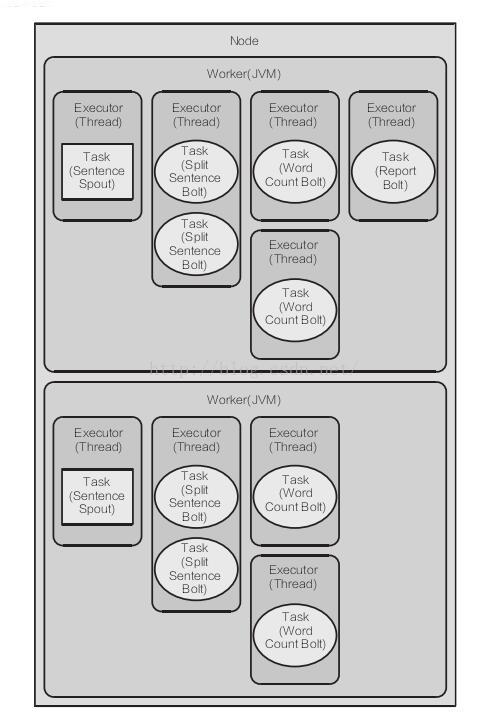
下一步,我们给语句分割 bolt SplitSentenceBolt 设置 4 个 task 和 2 个 executor。每个executor 线程指派 2 个 task 来执行(4/2=2)。还将配置单词计数 bolt 运行四个 task,每个task 由一个 executor 线程执行:
此时,运行代码,每个单词的计数比原topology 要多:
结果如下:

书中的代码
http://download.csdn.net/detail/zhuzhiyunzzy/8336583
本文所引用的例子在Chapter01中
在Storm中,一个task就可以理解为在集群中某个节点上运行的一个spout或者bolt实例。
记住一个task是一个实例。 实例明白吧
Class Person 是一个类, persona,personb都是Person的一个实例。
在集群运行运行中,topology主要有四个组成部分。
他们从低到高分别是task(bolt/spout实例),Executor(线程),Workers(JVM虚拟机),Nodes(服务器)
task上面已经说过,task的nextTuple和execute方法会被executor线程调用
Executor是jvm进程中运行的一个java线程,多个task可以分配给同一个executor来执行。也就是说executor与task是一对多的关系。不过,除非明确指定,Storm会默认给每个executor分配一个task。默认是一对一。
Workers,指的是node上独立的jvm进程。每个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
Nodes,指配置在一个 Storm 集群中的服务器,会执行 topology 的一部分运算。一个 Storm 集群可以包括一个或者多个工作 node。
我们看下面的例子
package Storm.blueprints.chapter1.v1;
import backtype.Storm.Config;
import backtype.Storm.LocalCluster;
import backtype.Storm.topology.TopologyBuilder;
import backtype.Storm.tuple.Fields;
import static Storm.blueprints.utils.Utils.*;
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt)
.globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
waitForSeconds(10);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}程序执行完毕后,在控制台可以看到类似以下的输出:
很简单,就是就经典的数单词数量的topology,大家根据各个类的名字,应该也能猜出来内部的逻辑。
里面的代码,我就不贴出来了,大家自己都能找到很多。
我们知道在设置spout/bolt的时候如果不设置parallelism_hint,就默认为1
它的整体的并行图,如下:
正如在图中看到的,唯一的并发机制出现在线程级。每个任务在同一个 JVM 的不同线程中执行。如何增加并发度以充分利用硬件能力?让我们来增加分配给topology 的
worker 和 executer 的数量。
配置executor和task
我们把 sentencespout的并发度调成2,并且worker不变。代码如下:
//这个2 指的是有两个executor 和task的数量无关 不过在这行代码里,我们没有指定task的数量,因为executor为2 那么task也就是2
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
那么它的并行图如下:
配置worker数量
这个很简单,我们在config里设置一下就OK
Config config = new Config();
config.setNumWorkers(2);
下一步,我们给语句分割 bolt SplitSentenceBolt 设置 4 个 task 和 2 个 executor。每个executor 线程指派 2 个 task 来执行(4/2=2)。还将配置单词计数 bolt 运行四个 task,每个task 由一个 executor 线程执行:
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 4)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt这么一来,整体的运行图就是下面的样子了此时,运行代码,每个单词的计数比原topology 要多:
结果如下:
书中的代码
http://download.csdn.net/detail/zhuzhiyunzzy/8336583
本文所引用的例子在Chapter01中

相关文章推荐
- 前端基础三
- Storm并发机制详解
- Java安全管理器(Security Manager)
- JDK中的动态代理
- Java中static的用法详解
- 深入理解C语言中两级指针(char **pptr)的参数的用法
- leetcode: Word Ladder
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法
- JavaScript slice() 方法