linux内核栈与用户栈及调用栈观察方法
2016-06-29 20:56
555 查看
最近linux内核的中断部分,总是被书里的栈弄晕,一会儿内核栈,一会儿用户栈的……很是崩溃,在网上google了一下 找了一篇不错的文章拿来分享。
本节内容概要描述了Linux内核从开机引导到系统正常运行过程中对堆栈的使用方式。这部分内容的说明与内核代码关系比较密切,可以先跳过。在开始阅读相应代码时再回来仔细研究。
Linux 0.12系统中共使用了4种堆栈。第1种是系统引导初始化时临时使用的堆栈;第2种是进入保护模式之后提供内核程序初始化使用的堆栈,位于内核代码地址空间固定位置处。该堆栈也是后来任务0使用的用户态堆栈;第3种是每个任务通过系统调用,执行内核程序时使用的堆栈,我们称之为任务的内核态堆栈。每个任务都有自己独立的内核态堆栈;第4种是任务在用户态执行的堆栈,位于任务(进程)逻辑地址空间近末端处。
使用多个栈或在不同情况下使用不同栈的主要原因有两个。首先是由于从实模式进入保护模式,使得CPU对内存寻址访问方式发生了变化,因此需要重新调整设置栈区域。另外,为了解决不同CPU特权级共享使用堆栈带来的保护问题,执行0级的内核代码和执行3级的用户代码需要使用不同的栈。当一个任务进入内核态运行时,就会使用其TSS段中给出的特权级0的堆栈指针tss.ss0、tss.esp0,即内核栈。原用户栈指针会被保存在内核栈中。而当从内核态返回用户态时,就会恢复使用用户态的堆栈。下面分别对它们进行说明。
(1)开机初始化时(bootsect.S,setup.s)
当bootsect代码被ROM BIOS引导加载到物理内存0x7c00处时,并没有设置堆栈段,当然程序也没有使用堆栈。直到bootsect被移动到0x9000:0处时,才把堆栈段寄存器SS设置为0x9000,堆栈指针esp寄存器设置为0xff00,即堆栈顶端在0x9000:0xff00处,参见boot/bootsect.s第61、62行。setup.s程序中也沿用了bootsect中设置的堆栈段。这就是系统初始化时临时使用的堆栈。
(2)进入保护模式时(head.s)
从esp设置成指向user_stack数组的顶端(参见user_stack数组定义在sched.c的67~23。此时该堆栈是内核程序自己使用的堆栈。其中给出的地址是大约值,它们与编译时的实际设置参数有关。这些地址位置是从编译内核时生成的system.map文件中查到的。

图5-23 刚进入保护模式时内核使用的堆栈示意图
(3)初始化时(main.c)
在init/main.c程序中,在执行move_to_user_mode()代码把控制权移交给任务0之前,系统一直使用上述堆栈。而在执行过move_to_user_mode()之后,main.c的代码被“切换”成任务0中执行。通过执行fork()系统调用,main.c中的init()将在任务1中执行,并使用任务1的堆栈。而main()本身则在被“切换”成为任务0后,仍然继续使用上述内核程序自己的堆栈作为任务0的用户态堆栈。关于任务0所使用堆栈的详细描述见后面说明。
每个任务都有两个堆栈,分别用于用户态和内核态程序的执行,并且分别称为用户态堆栈和内核态堆栈。除了处于不同CPU特权级中,这两个堆栈之间的主要区别在于任务的内核态堆栈很小,所保存的数据量最多不能超过4096 – 任务数据结构块个字节,大约为3KB。而任务的用户态堆栈却可以在用户的64MB空间内延伸。
(1)在用户态运行时
每个任务(除了任务0和任务1)有自己的64MB地址空间。当一个任务(进程)刚被创建时,它的用户态堆栈指针被设置在其地址空间的靠近末端(64MB顶端)部分。实际上末端部分还要包括执行程序的参数和环境变量,然后才是用户堆栈空间,如图5-24所示。应用程序在用户态下运行时就一直使用这个堆栈。堆栈实际使用的物理内存则由CPU分页机制确定。由于Linux实现了写时复制功能(Copy on Write),因此在进程被创建后,若该进程及其父进程都没有使用堆栈,则两者共享同一堆栈对应的物理内存页面。只有当其中一个进程执行堆栈写操作(如push操作)时内核内存管理程序才会为写操作进程分配新的内存页面。而进程0和进程1的用户堆栈比较特殊,见后面说明。

图5-24 逻辑空间中的用户态堆栈
(2)在内核态运行时
每个任务都有自己的内核态堆栈,用于任务在内核代码中执行期间。其所在线性地址中的位置由该任务TSS段中ss0和esp0两个字段指定。ss0是任务内核态堆栈的段选择符,esp0是堆栈栈底指针。因此每当任务从用户代码转移进入内核代码中执行时,任务的内核态栈总是空的。任务内核态堆栈被设置在位于其任务数据结构所在页面的末端,即与任务
4000
的任务数据结构(task_struct)放在同一页面内。这是在建立新任务时,fork()程序在任务tss段的内核级堆栈字段(tss.esp0和tss.ss0)中设置的,参见kernel/fork.c,92行:
p->tss.esp0 = PAGE_SIZE + (long)p;
p->tss.ss0 = 0x10;
其中,p是新任务的任务数据结构指针,tss是任务状态段结构。内核为新任务申请内存用作保存其task_struct结构数据,而tss结构(段)是task_struct中的一个字段。该任务的内核堆栈段值tss.ss0也被设置成为0x10(即内核数据段选择符),而tss.esp0则指向保存task_struct结构页面的末端。如图5-25所示。实际上tss.esp0被设置成指向该页面(外)上一字节处(图中堆栈底处)。这是因为Intel CPU执行堆栈操作时是先递减堆栈指针esp值,然后在esp指针处保存入栈内容。
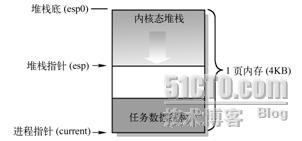
图5-25 进程的内核态堆栈示意图
为什么从主内存区申请得来的用于保存任务数据结构的一页内存也能被设置成内核数据段中的数据呢,即tss.ss0为什么能被设置成0x10呢?这是因为用户内核态栈仍然属于内核数据空间。我们可以从内核代码段的长度范围来说明。在head.s程序的末端,分别设置了内核代码段和数据段的描述符,段长度都被设置成了16MB。这个长度值是Linux 0.12内核所能支持的最大物理内存长度(参见head.s,110行开始的注释)。因此,内核代码可以寻址到整个物理内存范围中的任何位置,当然也包括主内存区。每当任务执行内核程序而需要使用其内核栈时,CPU就会利用TSS结构把它的内核态堆栈设置成由tss.ss0和tss.esp0这两个值构成。在任务切换时,老任务的内核栈指针esp0不会被保存。对CPU来讲,这两个值是只读的。因此每当一个任务进入内核态执行时,其内核态堆栈总是空的。
(3)任务0和任务1的堆栈
任务0(空闲进程idle)和任务1(初始化进程init)的堆栈比较特殊,需要特别予以说明。任务0和任务1的代码段和数据段相同,限长也都是640KB,但它们被映射到不同的线性地址范围中。任务0的段基地址从线性地址0开始,而任务1的段基地址从64MB开始。但是它们全都映射到物理地址0~640KB范围中。这个地址范围也就是内核代码和基本数据所存放的地方。在执行了move_to_user_mode()之后,任务0和任务1的内核态堆栈分别位于各自任务数据结构所在页面的末端,而任务0的用户态堆栈就是前面进入保护模式后所使用的堆栈,即sched.c的user_stack[]数组的位置。由于任务1在创建时复制了任务0的用户堆栈,因此刚开始时任务0和任务1共享使用同一个用户堆栈空间。但是当任务1开始运行时,由于任务1映射到user_stack[]处的页表项被设置成只读,使得任务1在执行堆栈操作时将会引起写页面异常,从而内核会使用写时复制机制(关于写时复制技术的说明请参见第13章)为任务1另行分配主内存区页面作为堆栈空间使用。只有到此时,任务1才开始使用自己独立的用户堆栈内存页面。因此任务0的堆栈需要在任务1实际开始使用之前保持“干净”,即任务0此时不能使用堆栈,以确保复制的堆栈页面中不含有任务0的数据。
任务0的内核态堆栈是在其人工设置的初始化任务数据结构中指定的,而它的用户态堆栈是在执行move_to_user_mode()时,在模拟iret返回之前的堆栈中设置的,参见图5-22所示。我们知道,当进行特权级会发生变化的控制权转移时,目的代码会使用新特权级的堆栈,而原特权级代码堆栈指针将保留在新堆栈中。因此这里先把任务0用户堆栈指针压入当前处于特权级0的堆栈中,同时把代码指针也压入堆栈,然后执行IRET指令即可实现把控制权从特权级0的代码转移到特权级3的任务0代码中。在这个人工设置内容的堆栈中,原esp值被设置成仍然是user_stack中原来的位置值,而原ss段选择符被设置成0x17,即设置成用户态局部表LDT中的数据段选择符。然后把任务0代码段选择符0x0f压入堆栈作为栈中原CS段的选择符,把下一条指令的指针作为原EIP压入堆栈。这样,通过执行IRET指令即可“返回”到任务0的代码中继续执行了。
在<span times="" new="" roman',="" 'serif'"="" lang="EN-US" style="padding: 0px; margin: 0px;">Linux 0.12系统中,所有中断服务程序都属于内核代码。如果一个中断产生时任务正在用户代码中执行,那么该中断就会引起CPU特权级从3级到0级的变化,此时CPU就会进行用户态堆栈到内核态堆栈的切换操作。CPU会从当前任务的任务状态段TSS中取得新堆栈的段选择符和偏移值。因为中断服务程序在内核中,属于0级特权级代码,所以48位的内核态堆栈指针会从TSS的ss0和esp0字段中获得。在定位了新堆栈(内核态堆栈)之后,CPU就会首先把原用户态堆栈指针ss和esp压入内核态堆栈,随后把标志寄存器eflags的内容和返回位置cs、eip压入内核态堆栈。
内核的系统调用是一个软件中断,因此任务调用系统调用时就会进入内核并执行内核中的中断服务代码。此时内核代码就会使用该任务的内核态堆栈进行操作。同样,当进入内核程序时,由于特权级别发生了改变(从用户态转到内核态),用户态堆栈的堆栈段和堆栈指针以及eflags会被保存在任务的内核态堆栈中。而在执行iret退出内核程序返回到用户程序时,将恢复用户态的堆栈和eflags。这个过程如图5-26所示。
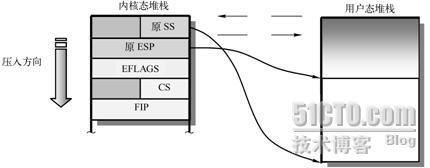
图5-26 内核态和用户态堆栈的切换
如果一个任务正在内核态中运行,那么若CPU响应中断就不再需要进行堆栈切换操作,因为此时该任务运行的内核代码已经在使用内核态堆栈,并且不涉及优先级别的变化,所以CPU仅把eflags和中断返回指针cs、eip压入当前内核态堆栈,然后执行中断服务过程。
查看进程在内核中的调用栈小工具
编译内核时打开调试选项:
General setup--------->Configure standard kernel features
-------->
Load all symbols for debugging/kksymbols
Include all symbols in kallsyms
工具的使用很简单:
#echo pid > /proc/show_stack
#cat /proc/show_stack
调用栈的显示代码是从内核函数show_stack改写得来
#include <linux/init.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/sched.h>
#include <asm/uaccess.h>
#include <linux/fs.h>
#include <linux/stat.h>
#include <linux/proc_fs.h>
#include <linux/kallsyms.h>
MODULE_LICENSE("BSD/GPL");
MODULE_AUTHOR("SanLongCai");
static int show_pid = 1;
module_param(show_pid, int, 0);
static int sstack_read_proc(char *page, char **start, off_t offset, int count, int
*eof, void *data);
static int myatoi(const char *buf, unsigned int count)
{
int i;
int res;
if(! buf || count == 0)
return 0;
res = 0;
i = 0;
while(i < count && buf[i]) {
if(buf[i] < '0' || buf[i] > '9') {
printk(KERN_INFO "the buf:%s conn't convert to int
", buf);
return 0;
}
res = res * 10 + buf[i] - '0';
i++;
}
return res;
}
static int sstack_show(void)
{
char *page;
if(!(page = (char *)__get_free_page(GFP_KERNEL)))
return -ENOMEM;
sstack_read_proc(page, NULL, 0, 0, NULL, NULL);
printk(KERN_INFO "%s
", page);
free_page((unsigned long)page);
//show_stack(task, NULL); //show_stack must be export by kernel
return 0;
}
static inline int valid_stack_ptr(struct thread_info *tinfo, void *p, unsigned size)
{
return p > (void *)tinfo &&
p <= (void *)tinfo + THREAD_SIZE - size;
}
struct stack_frame {
struct stack_frame *next_frame;
unsigned long return_address;
};
static void show_address_symbol(unsigned long address, char *page, int *len)
{
char buffer[KSYM_SYMBOL_LEN];
*len += sprintf(page + (*len), " [<%08lx>]", address);
sprint_symbol(buffer, (unsigned long)__builtin_extract_return_addr((void
*)address));
*len += sprintf(page + (*len), " %s
", buffer);
}
static unsigned long show_context_stack(struct thread_info *tinfo, unsigned long
*stack, unsigned long bp,
char *page, int *len)
{
struct stack_frame *frame = (struct stack_frame *)bp;
while (valid_stack_ptr(tinfo, stack, sizeof(*stack))) {
unsigned long addr;
addr = *stack;
if (kernel_text_address(addr)) {
if ((unsigned long) stack == bp + 4) {
frame = frame->next_frame;
bp = (unsigned long) frame;
show_address_symbol(addr, page, len);
} else {
if(bp == 0)
show_address_symbol(addr, page, len);
}
}
stack++;
}
return bp;
}
static int sstack_read_proc(char *page, char **start, off_t offset, int count, int
*eof, void *data)
{
int len = 0;
unsigned long bp;
unsigned long *stack;
struct task_struct *task;
len += sprintf(page, "Call Trace:
");
if((task = find_task_by_pid(show_pid)) == NULL)
{
len += sprintf(page + len, "Process %d not found!!
", show_pid);
return len;
}
stack = (unsigned long *)task->thread.sp;
bp = *stack;
while(1) {
struct thread_info *context;
context = (struct thread_info *) ((unsigned long)stack & (~(THREAD_SIZE -
1)));
bp = show_context_stack(context, stack, bp, page, &len);
stack = (unsigned long *)context->previous_esp;
if(! stack)
break;
}
len += sprintf(page + len, "Call Trace End.
");
len += sprintf(page + len, "==================================
");
return len;
}
static int sstack_write_proc(struct file *file, const char *buffer, unsigned long
count, void *data)<
f2ad
br />
{
char buf[16];
int new_pid;
if(count > 16) {
printk(KERN_INFO "the count is too large");
return -EINVAL;
}
if(copy_from_user(buf, buffer, count)) {
return -EFAULT;
}
if(buf[count - 1] < '0' || buf[count - 1] > '9')
buf[count -1] = '';
if(new_pid = myatoi(buf, 16))
{
int ret;
show_pid = new_pid;
if(ret = sstack_show())
return ret;
return count;
}
else
return -EINVAL;
}
static void sstack_create_proc(void)
{
struct proc_dir_entry *res = create_proc_entry("show_stack", S_IRUGO | S_IWUGO,
NULL);
if(res) {
res->read_proc = sstack_read_proc;
res->write_proc = sstack_write_proc;
}
else
printk(KERN_INFO "create the proc failure
");
}
static int __init sstack_init(void)
{
printk(KERN_INFO "sstack_init
");
sstack_create_proc();
return 0;
}
static void sstack_exit(void)
{
printk(KERN_INFO "sstack_exit
");
remove_proc_entry("show_stack", NULL);
}
module_init(sstack_init);
module_exit(sstack_exit);
[b]死锁后,导出线程函数调用栈[/b]
很多时候,内核oops还是很好处理的,因为可以看到当时的函数调用栈。objdump -DS vmlinux,配合epc(程序指针)可以定位情况发生时的代码位置。有些调试器,支持断点地址设置,可以直接显示问题发生时的代码位置。
然而,当系统陷入某种死锁状态。又比如应用程序进行的系统调用不能退出等等。这种情况下,显示当前所有线程的当前函数调用栈就有很大的帮助作用了。
我们可以通过外部触发事件,比如按键,终端输入。或者在程序代码中设定定时器。在事件处理程序中,显示当前所有线程或者关心的线程的函数调用栈。
if(task == current)
{
dump_stack();
}else
{
regs.regs[29] = task->thread.reg29;
regs.regs[31] = task->thread.reg31;
regs.cp0_epc = 0;
show_backtrace(task, ®s);
}
写个dump_stack
简单实现dump_stack
0.首先确保你能写个内核模块:打印"hello kernel"
如果熟悉dump_stack的话,完全可以绕开此文,或者自己去看dump_stack代码实现之。
1.dump_stack是什么
经常调试内核一定对这个函数不陌生,因为我们大多数人调试内核的时候都受这个函数的
折磨,不信,那么我们调用下这个函数看看(随意写个内核模块调用dump_stack(),插入内核),
我们来看看输出:
Pid: 9982, comm: insmod Not tainted 2.6.31.5-127.fc12.i686.PAE #1
Call Trace:
[<f7e98008>] init+0x8/0xc [hello]
[<c040305b>] do_one_initcall+0x51/0x13f
[<c0462e2f>] sys_init_module+0xac/0x1bd
[<c0408f7b>] sysenter_do_call+0x12/0x28
看到输出,大家一定很熟悉, 没见过类似输出的,一定没把kernel搞崩过.
(来我教你:*(int *)NULL = 0xdead;)
其实不见得每次内核崩溃都会调用dump_stack,但是看到dump_stack的我们不应该被吓到,
反而应该高兴:内核在临挂前还喘口气给我们提示了宝贵的调试信息
2.构造dump_stack第一句
有的人已经不耐烦我这唠叨,自己开始查看代码了,但是为了满足我们小小的虚荣,看懂还不行,
自己也要来写个玩玩,不能老被dump_stack欺负阿。
我们看看dump_stack里面第一句代码:
printk("Pid: %d, comm: %.20s %s %s %.*s/n",
current->pid, current->comm, print_tainted(),
init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
这里就不解释printk每个参数了,代码本身就自解释了,剩下的请google,
对于不太理解print_tainted,请看下此函数实现的源码上方的注释:)
3.构造dump_stack的call trace
1)先来句printk("Call Trace:/n"),
2)接下来就神奇了,当初我就觉得能将函数执行流打印出来实在是很神奇,内核到底用了什么方法呢?
先不说,我们来看一句简单的代码:
printk("[<%p>] %pS/n", &printk, &printk);
观察输出:
[<c0776cf4>] printk+0x0/0x1c
你发现,这个输出结果和dump_stack输出的部分惊人的相似,但是我们传给printk的参数是确确实实的
地址值,原来prink自己能转换地址到相应的函数名,只要用参数"%pS"就可以了。
我相信看到这里的人,估计已经走开自己去实现dump_stack玩了。
但是输出也可能是:
[<c0776cf4>] c0776cf4S
如果你不幸看到这个,那么你还是升级下内核吧,或者仔细阅读下dump_stack代码,完全靠自己去实现
下,那么你收获一定会远超出这篇文章。
printk之所以能够识别函数地址,靠的是kallsyms子系统的帮助,
用过类似grep -w "printk" /proc/kallsyms命令的人,一定要好好谢谢这个子系统,
多亏它我们才能从内核导出symbol
深入研究kallsyms就靠大家了。
3)在刚刚的惊喜后,我们回到正题,怎么用printk把当前的执行流打印出来?
这里用到x86中堆栈对函数调用的帮助,详细信息请google,我们要知道一点:每次函数调用时候,
都会将函数的返回地址(调用函数指令的下一句指令的地址)压入堆栈,已备函数返回时。
我们就可以靠这个返回地址来帮助打印函数执行流。
但是这个地址并不是一个函数的准确地址呀?
%pS需要的参数不一定是准确的函数地址,在函数内部任意指令地址都可以,这就解释了输出形式是
"printk+0x0/0x1c",0x0表示参数地址相对于printk地址的偏移,0x1c表示printk函数大小。
你可以尝试下:printk("%pS/n", &printk + 1);
并且如果函数属于某个模块,还会在输出后面加上模块名称,类似:" [<f8cd40a5>] exit+0xd/0xf [hello]"
这里知道地址在堆栈里,那么怎么取堆栈呢?
其实很简单:
int stack_pointer;
我们只要取临时变量地址值 &stack_pointer 就可以了(也可以用内联汇编取esp值),然后只要循环遍历堆栈上所有值,然后判断该值是否在
内核代码段空间内,如果是那么就用%pS输出。
那么堆栈的结束地址是什么呢?
就是当前进程的内核态堆栈段,不懂的话请google,一定要搞清除这个。
这里我们记堆栈底为:
bottom = (unsigned int)current_thread_info() + THREAD_SIZE;
但是怎么判断地址值是否在内核代码段呢?
我们可以用kernel_text_address这个函数就可以了,但是很不幸的是此函数内核没有导出,我们不能使用,
那么我们就自己实现个kernel_text_address吧,但是更不幸的是此函数内部实现所依赖的变量_etext等也没有
被内核导出,其实我也没想到很好的方法,索性就用个笨办法:
手动找出此函数内核中的地址,
# grep kernel_text_address /proc/kallsyms
c044f107 T kernel_text_address
在代码中通过地址值调用kernel_text_address
int (*kernel_text_addressp)(unsigned int) = (int (*)(unsigned int))0xc044f107;
4)给出个较为完整的代码(在本机上写的:2.6.31.5-127.fc12.i686.PAE, 虚拟机上文档写的麻烦)
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/utsname.h>
/*
* change the value to real addr of kernel_text_address :
* grep -w kernel_text_address /proc/kallsyms
*/
static int (*kernel_text_addressp)(unsigned int) = (int (*)(unsigned int))0xc044f107;
void my_dump_stack(void)
{
unsigned int stack;
unsigned int bottom;
unsigned int addr;
printk("Pid: %d, comm: %.20s %s %s %.*s/n",
current->pid, current->comm, print_tainted(),
init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
printk("Call Trace:/n");
/* get stack point */
stack = (unsigned int)&stack;
/* get stack bottom point */
bottom = (unsigned int)current_thread_info() + THREAD_SIZE;
for (; stack < bottom; stack += 4) {
addr = *(unsigned int *)stack;
if (kernel_text_addressp(addr))
printk(" [<%p>] %pS/n", (void *)addr, (void *)addr);
}
}
static int __init init(void)
{
/* test */
my_dump_stack();
return 0;
}
static void __exit exit(void)
{
/* test */
my_dump_stack();
}
MODULE_LICENSE("GPL");
module_init(init);
module_exit(exit);
3.改进
1)
如果你还没厌烦的话,这里有个改进的地方。
你会发现内核中的dump_stack会又类似如下输出:
[<c04cf4e6>] ? path_put+0x1a/0x1d
这里有个问号:这个表示堆栈中有确有此值(某个函数内部地址),但是并不代表此函数被
执行,也许这个值是个临时变量寄存在堆栈中。
要区分这个很容易,只要比较地址值所在堆栈的位置是否紧贴当前函数栈空间底的上方,
可以利用ebp(记录当前堆栈底)指针值来作比较,代码就留给大家写了。
2)
x86 64 实现要比x86 32复杂(见内核注释):
/*
* x86-64 can have up to three kernel stacks:
* process stack
* interrupt stack
* severe exception (double fault, nmi, stack fault, debug, mce) hardware stack
*/
4.后记
你可能认为作者在忽悠你,这就整一个dump_stack注释的文章呀,贯上了写dump_stack的头衔!
我只有一句话:
Just for fun!
5.8 Linux 系统中堆栈的使用方法
本节内容概要描述了Linux内核从开机引导到系统正常运行过程中对堆栈的使用方式。这部分内容的说明与内核代码关系比较密切,可以先跳过。在开始阅读相应代码时再回来仔细研究。Linux 0.12系统中共使用了4种堆栈。第1种是系统引导初始化时临时使用的堆栈;第2种是进入保护模式之后提供内核程序初始化使用的堆栈,位于内核代码地址空间固定位置处。该堆栈也是后来任务0使用的用户态堆栈;第3种是每个任务通过系统调用,执行内核程序时使用的堆栈,我们称之为任务的内核态堆栈。每个任务都有自己独立的内核态堆栈;第4种是任务在用户态执行的堆栈,位于任务(进程)逻辑地址空间近末端处。
使用多个栈或在不同情况下使用不同栈的主要原因有两个。首先是由于从实模式进入保护模式,使得CPU对内存寻址访问方式发生了变化,因此需要重新调整设置栈区域。另外,为了解决不同CPU特权级共享使用堆栈带来的保护问题,执行0级的内核代码和执行3级的用户代码需要使用不同的栈。当一个任务进入内核态运行时,就会使用其TSS段中给出的特权级0的堆栈指针tss.ss0、tss.esp0,即内核栈。原用户栈指针会被保存在内核栈中。而当从内核态返回用户态时,就会恢复使用用户态的堆栈。下面分别对它们进行说明。
5.8.1 初始化阶段
(1)开机初始化时(bootsect.S,setup.s)当bootsect代码被ROM BIOS引导加载到物理内存0x7c00处时,并没有设置堆栈段,当然程序也没有使用堆栈。直到bootsect被移动到0x9000:0处时,才把堆栈段寄存器SS设置为0x9000,堆栈指针esp寄存器设置为0xff00,即堆栈顶端在0x9000:0xff00处,参见boot/bootsect.s第61、62行。setup.s程序中也沿用了bootsect中设置的堆栈段。这就是系统初始化时临时使用的堆栈。
(2)进入保护模式时(head.s)
从esp设置成指向user_stack数组的顶端(参见user_stack数组定义在sched.c的67~23。此时该堆栈是内核程序自己使用的堆栈。其中给出的地址是大约值,它们与编译时的实际设置参数有关。这些地址位置是从编译内核时生成的system.map文件中查到的。
图5-23 刚进入保护模式时内核使用的堆栈示意图
(3)初始化时(main.c)
在init/main.c程序中,在执行move_to_user_mode()代码把控制权移交给任务0之前,系统一直使用上述堆栈。而在执行过move_to_user_mode()之后,main.c的代码被“切换”成任务0中执行。通过执行fork()系统调用,main.c中的init()将在任务1中执行,并使用任务1的堆栈。而main()本身则在被“切换”成为任务0后,仍然继续使用上述内核程序自己的堆栈作为任务0的用户态堆栈。关于任务0所使用堆栈的详细描述见后面说明。
5.8.2 任务的堆栈
每个任务都有两个堆栈,分别用于用户态和内核态程序的执行,并且分别称为用户态堆栈和内核态堆栈。除了处于不同CPU特权级中,这两个堆栈之间的主要区别在于任务的内核态堆栈很小,所保存的数据量最多不能超过4096 – 任务数据结构块个字节,大约为3KB。而任务的用户态堆栈却可以在用户的64MB空间内延伸。(1)在用户态运行时
每个任务(除了任务0和任务1)有自己的64MB地址空间。当一个任务(进程)刚被创建时,它的用户态堆栈指针被设置在其地址空间的靠近末端(64MB顶端)部分。实际上末端部分还要包括执行程序的参数和环境变量,然后才是用户堆栈空间,如图5-24所示。应用程序在用户态下运行时就一直使用这个堆栈。堆栈实际使用的物理内存则由CPU分页机制确定。由于Linux实现了写时复制功能(Copy on Write),因此在进程被创建后,若该进程及其父进程都没有使用堆栈,则两者共享同一堆栈对应的物理内存页面。只有当其中一个进程执行堆栈写操作(如push操作)时内核内存管理程序才会为写操作进程分配新的内存页面。而进程0和进程1的用户堆栈比较特殊,见后面说明。
图5-24 逻辑空间中的用户态堆栈
(2)在内核态运行时
每个任务都有自己的内核态堆栈,用于任务在内核代码中执行期间。其所在线性地址中的位置由该任务TSS段中ss0和esp0两个字段指定。ss0是任务内核态堆栈的段选择符,esp0是堆栈栈底指针。因此每当任务从用户代码转移进入内核代码中执行时,任务的内核态栈总是空的。任务内核态堆栈被设置在位于其任务数据结构所在页面的末端,即与任务
4000
的任务数据结构(task_struct)放在同一页面内。这是在建立新任务时,fork()程序在任务tss段的内核级堆栈字段(tss.esp0和tss.ss0)中设置的,参见kernel/fork.c,92行:
p->tss.esp0 = PAGE_SIZE + (long)p;
p->tss.ss0 = 0x10;
其中,p是新任务的任务数据结构指针,tss是任务状态段结构。内核为新任务申请内存用作保存其task_struct结构数据,而tss结构(段)是task_struct中的一个字段。该任务的内核堆栈段值tss.ss0也被设置成为0x10(即内核数据段选择符),而tss.esp0则指向保存task_struct结构页面的末端。如图5-25所示。实际上tss.esp0被设置成指向该页面(外)上一字节处(图中堆栈底处)。这是因为Intel CPU执行堆栈操作时是先递减堆栈指针esp值,然后在esp指针处保存入栈内容。
图5-25 进程的内核态堆栈示意图
为什么从主内存区申请得来的用于保存任务数据结构的一页内存也能被设置成内核数据段中的数据呢,即tss.ss0为什么能被设置成0x10呢?这是因为用户内核态栈仍然属于内核数据空间。我们可以从内核代码段的长度范围来说明。在head.s程序的末端,分别设置了内核代码段和数据段的描述符,段长度都被设置成了16MB。这个长度值是Linux 0.12内核所能支持的最大物理内存长度(参见head.s,110行开始的注释)。因此,内核代码可以寻址到整个物理内存范围中的任何位置,当然也包括主内存区。每当任务执行内核程序而需要使用其内核栈时,CPU就会利用TSS结构把它的内核态堆栈设置成由tss.ss0和tss.esp0这两个值构成。在任务切换时,老任务的内核栈指针esp0不会被保存。对CPU来讲,这两个值是只读的。因此每当一个任务进入内核态执行时,其内核态堆栈总是空的。
(3)任务0和任务1的堆栈
任务0(空闲进程idle)和任务1(初始化进程init)的堆栈比较特殊,需要特别予以说明。任务0和任务1的代码段和数据段相同,限长也都是640KB,但它们被映射到不同的线性地址范围中。任务0的段基地址从线性地址0开始,而任务1的段基地址从64MB开始。但是它们全都映射到物理地址0~640KB范围中。这个地址范围也就是内核代码和基本数据所存放的地方。在执行了move_to_user_mode()之后,任务0和任务1的内核态堆栈分别位于各自任务数据结构所在页面的末端,而任务0的用户态堆栈就是前面进入保护模式后所使用的堆栈,即sched.c的user_stack[]数组的位置。由于任务1在创建时复制了任务0的用户堆栈,因此刚开始时任务0和任务1共享使用同一个用户堆栈空间。但是当任务1开始运行时,由于任务1映射到user_stack[]处的页表项被设置成只读,使得任务1在执行堆栈操作时将会引起写页面异常,从而内核会使用写时复制机制(关于写时复制技术的说明请参见第13章)为任务1另行分配主内存区页面作为堆栈空间使用。只有到此时,任务1才开始使用自己独立的用户堆栈内存页面。因此任务0的堆栈需要在任务1实际开始使用之前保持“干净”,即任务0此时不能使用堆栈,以确保复制的堆栈页面中不含有任务0的数据。
任务0的内核态堆栈是在其人工设置的初始化任务数据结构中指定的,而它的用户态堆栈是在执行move_to_user_mode()时,在模拟iret返回之前的堆栈中设置的,参见图5-22所示。我们知道,当进行特权级会发生变化的控制权转移时,目的代码会使用新特权级的堆栈,而原特权级代码堆栈指针将保留在新堆栈中。因此这里先把任务0用户堆栈指针压入当前处于特权级0的堆栈中,同时把代码指针也压入堆栈,然后执行IRET指令即可实现把控制权从特权级0的代码转移到特权级3的任务0代码中。在这个人工设置内容的堆栈中,原esp值被设置成仍然是user_stack中原来的位置值,而原ss段选择符被设置成0x17,即设置成用户态局部表LDT中的数据段选择符。然后把任务0代码段选择符0x0f压入堆栈作为栈中原CS段的选择符,把下一条指令的指针作为原EIP压入堆栈。这样,通过执行IRET指令即可“返回”到任务0的代码中继续执行了。
5.8.3 任务内核态堆栈与用户态堆栈之间的切换
在<span times="" new="" roman',="" 'serif'"="" lang="EN-US" style="padding: 0px; margin: 0px;">Linux 0.12系统中,所有中断服务程序都属于内核代码。如果一个中断产生时任务正在用户代码中执行,那么该中断就会引起CPU特权级从3级到0级的变化,此时CPU就会进行用户态堆栈到内核态堆栈的切换操作。CPU会从当前任务的任务状态段TSS中取得新堆栈的段选择符和偏移值。因为中断服务程序在内核中,属于0级特权级代码,所以48位的内核态堆栈指针会从TSS的ss0和esp0字段中获得。在定位了新堆栈(内核态堆栈)之后,CPU就会首先把原用户态堆栈指针ss和esp压入内核态堆栈,随后把标志寄存器eflags的内容和返回位置cs、eip压入内核态堆栈。内核的系统调用是一个软件中断,因此任务调用系统调用时就会进入内核并执行内核中的中断服务代码。此时内核代码就会使用该任务的内核态堆栈进行操作。同样,当进入内核程序时,由于特权级别发生了改变(从用户态转到内核态),用户态堆栈的堆栈段和堆栈指针以及eflags会被保存在任务的内核态堆栈中。而在执行iret退出内核程序返回到用户程序时,将恢复用户态的堆栈和eflags。这个过程如图5-26所示。
图5-26 内核态和用户态堆栈的切换
如果一个任务正在内核态中运行,那么若CPU响应中断就不再需要进行堆栈切换操作,因为此时该任务运行的内核代码已经在使用内核态堆栈,并且不涉及优先级别的变化,所以CPU仅把eflags和中断返回指针cs、eip压入当前内核态堆栈,然后执行中断服务过程。
查看进程在内核中的调用栈小工具
编译内核时打开调试选项:
General setup--------->Configure standard kernel features
-------->
Load all symbols for debugging/kksymbols
Include all symbols in kallsyms
工具的使用很简单:
#echo pid > /proc/show_stack
#cat /proc/show_stack
调用栈的显示代码是从内核函数show_stack改写得来
#include <linux/init.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/sched.h>
#include <asm/uaccess.h>
#include <linux/fs.h>
#include <linux/stat.h>
#include <linux/proc_fs.h>
#include <linux/kallsyms.h>
MODULE_LICENSE("BSD/GPL");
MODULE_AUTHOR("SanLongCai");
static int show_pid = 1;
module_param(show_pid, int, 0);
static int sstack_read_proc(char *page, char **start, off_t offset, int count, int
*eof, void *data);
static int myatoi(const char *buf, unsigned int count)
{
int i;
int res;
if(! buf || count == 0)
return 0;
res = 0;
i = 0;
while(i < count && buf[i]) {
if(buf[i] < '0' || buf[i] > '9') {
printk(KERN_INFO "the buf:%s conn't convert to int
", buf);
return 0;
}
res = res * 10 + buf[i] - '0';
i++;
}
return res;
}
static int sstack_show(void)
{
char *page;
if(!(page = (char *)__get_free_page(GFP_KERNEL)))
return -ENOMEM;
sstack_read_proc(page, NULL, 0, 0, NULL, NULL);
printk(KERN_INFO "%s
", page);
free_page((unsigned long)page);
//show_stack(task, NULL); //show_stack must be export by kernel
return 0;
}
static inline int valid_stack_ptr(struct thread_info *tinfo, void *p, unsigned size)
{
return p > (void *)tinfo &&
p <= (void *)tinfo + THREAD_SIZE - size;
}
struct stack_frame {
struct stack_frame *next_frame;
unsigned long return_address;
};
static void show_address_symbol(unsigned long address, char *page, int *len)
{
char buffer[KSYM_SYMBOL_LEN];
*len += sprintf(page + (*len), " [<%08lx>]", address);
sprint_symbol(buffer, (unsigned long)__builtin_extract_return_addr((void
*)address));
*len += sprintf(page + (*len), " %s
", buffer);
}
static unsigned long show_context_stack(struct thread_info *tinfo, unsigned long
*stack, unsigned long bp,
char *page, int *len)
{
struct stack_frame *frame = (struct stack_frame *)bp;
while (valid_stack_ptr(tinfo, stack, sizeof(*stack))) {
unsigned long addr;
addr = *stack;
if (kernel_text_address(addr)) {
if ((unsigned long) stack == bp + 4) {
frame = frame->next_frame;
bp = (unsigned long) frame;
show_address_symbol(addr, page, len);
} else {
if(bp == 0)
show_address_symbol(addr, page, len);
}
}
stack++;
}
return bp;
}
static int sstack_read_proc(char *page, char **start, off_t offset, int count, int
*eof, void *data)
{
int len = 0;
unsigned long bp;
unsigned long *stack;
struct task_struct *task;
len += sprintf(page, "Call Trace:
");
if((task = find_task_by_pid(show_pid)) == NULL)
{
len += sprintf(page + len, "Process %d not found!!
", show_pid);
return len;
}
stack = (unsigned long *)task->thread.sp;
bp = *stack;
while(1) {
struct thread_info *context;
context = (struct thread_info *) ((unsigned long)stack & (~(THREAD_SIZE -
1)));
bp = show_context_stack(context, stack, bp, page, &len);
stack = (unsigned long *)context->previous_esp;
if(! stack)
break;
}
len += sprintf(page + len, "Call Trace End.
");
len += sprintf(page + len, "==================================
");
return len;
}
static int sstack_write_proc(struct file *file, const char *buffer, unsigned long
count, void *data)<
f2ad
br />
{
char buf[16];
int new_pid;
if(count > 16) {
printk(KERN_INFO "the count is too large");
return -EINVAL;
}
if(copy_from_user(buf, buffer, count)) {
return -EFAULT;
}
if(buf[count - 1] < '0' || buf[count - 1] > '9')
buf[count -1] = '';
if(new_pid = myatoi(buf, 16))
{
int ret;
show_pid = new_pid;
if(ret = sstack_show())
return ret;
return count;
}
else
return -EINVAL;
}
static void sstack_create_proc(void)
{
struct proc_dir_entry *res = create_proc_entry("show_stack", S_IRUGO | S_IWUGO,
NULL);
if(res) {
res->read_proc = sstack_read_proc;
res->write_proc = sstack_write_proc;
}
else
printk(KERN_INFO "create the proc failure
");
}
static int __init sstack_init(void)
{
printk(KERN_INFO "sstack_init
");
sstack_create_proc();
return 0;
}
static void sstack_exit(void)
{
printk(KERN_INFO "sstack_exit
");
remove_proc_entry("show_stack", NULL);
}
module_init(sstack_init);
module_exit(sstack_exit);
[b]死锁后,导出线程函数调用栈[/b]
很多时候,内核oops还是很好处理的,因为可以看到当时的函数调用栈。objdump -DS vmlinux,配合epc(程序指针)可以定位情况发生时的代码位置。有些调试器,支持断点地址设置,可以直接显示问题发生时的代码位置。
然而,当系统陷入某种死锁状态。又比如应用程序进行的系统调用不能退出等等。这种情况下,显示当前所有线程的当前函数调用栈就有很大的帮助作用了。
我们可以通过外部触发事件,比如按键,终端输入。或者在程序代码中设定定时器。在事件处理程序中,显示当前所有线程或者关心的线程的函数调用栈。
if(task == current)
{
dump_stack();
}else
{
regs.regs[29] = task->thread.reg29;
regs.regs[31] = task->thread.reg31;
regs.cp0_epc = 0;
show_backtrace(task, ®s);
}
写个dump_stack
简单实现dump_stack
0.首先确保你能写个内核模块:打印"hello kernel"
如果熟悉dump_stack的话,完全可以绕开此文,或者自己去看dump_stack代码实现之。
1.dump_stack是什么
经常调试内核一定对这个函数不陌生,因为我们大多数人调试内核的时候都受这个函数的
折磨,不信,那么我们调用下这个函数看看(随意写个内核模块调用dump_stack(),插入内核),
我们来看看输出:
Pid: 9982, comm: insmod Not tainted 2.6.31.5-127.fc12.i686.PAE #1
Call Trace:
[<f7e98008>] init+0x8/0xc [hello]
[<c040305b>] do_one_initcall+0x51/0x13f
[<c0462e2f>] sys_init_module+0xac/0x1bd
[<c0408f7b>] sysenter_do_call+0x12/0x28
看到输出,大家一定很熟悉, 没见过类似输出的,一定没把kernel搞崩过.
(来我教你:*(int *)NULL = 0xdead;)
其实不见得每次内核崩溃都会调用dump_stack,但是看到dump_stack的我们不应该被吓到,
反而应该高兴:内核在临挂前还喘口气给我们提示了宝贵的调试信息
2.构造dump_stack第一句
有的人已经不耐烦我这唠叨,自己开始查看代码了,但是为了满足我们小小的虚荣,看懂还不行,
自己也要来写个玩玩,不能老被dump_stack欺负阿。
我们看看dump_stack里面第一句代码:
printk("Pid: %d, comm: %.20s %s %s %.*s/n",
current->pid, current->comm, print_tainted(),
init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
这里就不解释printk每个参数了,代码本身就自解释了,剩下的请google,
对于不太理解print_tainted,请看下此函数实现的源码上方的注释:)
3.构造dump_stack的call trace
1)先来句printk("Call Trace:/n"),
2)接下来就神奇了,当初我就觉得能将函数执行流打印出来实在是很神奇,内核到底用了什么方法呢?
先不说,我们来看一句简单的代码:
printk("[<%p>] %pS/n", &printk, &printk);
观察输出:
[<c0776cf4>] printk+0x0/0x1c
你发现,这个输出结果和dump_stack输出的部分惊人的相似,但是我们传给printk的参数是确确实实的
地址值,原来prink自己能转换地址到相应的函数名,只要用参数"%pS"就可以了。
我相信看到这里的人,估计已经走开自己去实现dump_stack玩了。
但是输出也可能是:
[<c0776cf4>] c0776cf4S
如果你不幸看到这个,那么你还是升级下内核吧,或者仔细阅读下dump_stack代码,完全靠自己去实现
下,那么你收获一定会远超出这篇文章。
printk之所以能够识别函数地址,靠的是kallsyms子系统的帮助,
用过类似grep -w "printk" /proc/kallsyms命令的人,一定要好好谢谢这个子系统,
多亏它我们才能从内核导出symbol
深入研究kallsyms就靠大家了。
3)在刚刚的惊喜后,我们回到正题,怎么用printk把当前的执行流打印出来?
这里用到x86中堆栈对函数调用的帮助,详细信息请google,我们要知道一点:每次函数调用时候,
都会将函数的返回地址(调用函数指令的下一句指令的地址)压入堆栈,已备函数返回时。
我们就可以靠这个返回地址来帮助打印函数执行流。
但是这个地址并不是一个函数的准确地址呀?
%pS需要的参数不一定是准确的函数地址,在函数内部任意指令地址都可以,这就解释了输出形式是
"printk+0x0/0x1c",0x0表示参数地址相对于printk地址的偏移,0x1c表示printk函数大小。
你可以尝试下:printk("%pS/n", &printk + 1);
并且如果函数属于某个模块,还会在输出后面加上模块名称,类似:" [<f8cd40a5>] exit+0xd/0xf [hello]"
这里知道地址在堆栈里,那么怎么取堆栈呢?
其实很简单:
int stack_pointer;
我们只要取临时变量地址值 &stack_pointer 就可以了(也可以用内联汇编取esp值),然后只要循环遍历堆栈上所有值,然后判断该值是否在
内核代码段空间内,如果是那么就用%pS输出。
那么堆栈的结束地址是什么呢?
就是当前进程的内核态堆栈段,不懂的话请google,一定要搞清除这个。
这里我们记堆栈底为:
bottom = (unsigned int)current_thread_info() + THREAD_SIZE;
但是怎么判断地址值是否在内核代码段呢?
我们可以用kernel_text_address这个函数就可以了,但是很不幸的是此函数内核没有导出,我们不能使用,
那么我们就自己实现个kernel_text_address吧,但是更不幸的是此函数内部实现所依赖的变量_etext等也没有
被内核导出,其实我也没想到很好的方法,索性就用个笨办法:
手动找出此函数内核中的地址,
# grep kernel_text_address /proc/kallsyms
c044f107 T kernel_text_address
在代码中通过地址值调用kernel_text_address
int (*kernel_text_addressp)(unsigned int) = (int (*)(unsigned int))0xc044f107;
4)给出个较为完整的代码(在本机上写的:2.6.31.5-127.fc12.i686.PAE, 虚拟机上文档写的麻烦)
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/utsname.h>
/*
* change the value to real addr of kernel_text_address :
* grep -w kernel_text_address /proc/kallsyms
*/
static int (*kernel_text_addressp)(unsigned int) = (int (*)(unsigned int))0xc044f107;
void my_dump_stack(void)
{
unsigned int stack;
unsigned int bottom;
unsigned int addr;
printk("Pid: %d, comm: %.20s %s %s %.*s/n",
current->pid, current->comm, print_tainted(),
init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
printk("Call Trace:/n");
/* get stack point */
stack = (unsigned int)&stack;
/* get stack bottom point */
bottom = (unsigned int)current_thread_info() + THREAD_SIZE;
for (; stack < bottom; stack += 4) {
addr = *(unsigned int *)stack;
if (kernel_text_addressp(addr))
printk(" [<%p>] %pS/n", (void *)addr, (void *)addr);
}
}
static int __init init(void)
{
/* test */
my_dump_stack();
return 0;
}
static void __exit exit(void)
{
/* test */
my_dump_stack();
}
MODULE_LICENSE("GPL");
module_init(init);
module_exit(exit);
3.改进
1)
如果你还没厌烦的话,这里有个改进的地方。
你会发现内核中的dump_stack会又类似如下输出:
[<c04cf4e6>] ? path_put+0x1a/0x1d
这里有个问号:这个表示堆栈中有确有此值(某个函数内部地址),但是并不代表此函数被
执行,也许这个值是个临时变量寄存在堆栈中。
要区分这个很容易,只要比较地址值所在堆栈的位置是否紧贴当前函数栈空间底的上方,
可以利用ebp(记录当前堆栈底)指针值来作比较,代码就留给大家写了。
2)
x86 64 实现要比x86 32复杂(见内核注释):
/*
* x86-64 can have up to three kernel stacks:
* process stack
* interrupt stack
* severe exception (double fault, nmi, stack fault, debug, mce) hardware stack
*/
4.后记
你可能认为作者在忽悠你,这就整一个dump_stack注释的文章呀,贯上了写dump_stack的头衔!
我只有一句话:
Just for fun!

相关文章推荐
- Linux Kernel 4.0 RC5 发布!
- Linux 自检和 SystemTap
- LKRG:用于运行时完整性检查的可加载内核模块
- 一张图看尽 Linux 内核运行原理
- Greg Kroah-Hartman 解释内核社区是如何使 Linux 安全的
- Linux内核链表实现过程
- PHP内核探索之解释器的执行过程
- 深入理解PHP内核(二)之SAPI探究
- C++中Semaphore内核对象用法实例
- 一张图看尽Linux内核运行原理
- 深入理解PHP内核(一)
- PHP内核探索之变量
- 深入php内核之php in array
- 浅谈Linux内核创建新进程的全过程
- 戴文的Linux内核专题:01 介绍
- 戴文的Linux内核专题:09 配置内核(5)
- 戴文的Linux内核专题:10 配置内核(6)
- 戴文的Linux内核专题:02 源代码
- 戴文的Linux内核专题:03 驱动程序