基于Scrapy对更新后的Dmoz进行抓取(网上旧版本不靠谱)
2016-06-28 19:28
555 查看
Python 2.7
IDE Pycharm 5.0.3
Scrapy 1.0.3

请务必先看这个,不然看以下会云里雾里哒

1.IndentationError: unindent does not match any outer indentation level
问题原因:请不要使用Notepad++进行编辑,不是说不好,但是纠错能力显然没有Pycharm来得好,编辑过程中如果有拷贝代码的现象,请注意缩进!!!Python的灵魂在于缩进!
解决方案:使用Pycharm进行编辑,拷贝时候注意缩进!
2.ImportError: No module named tutorial.items
问题原因:执行路径中没有tutorial目录,所以找不到模块和包
解决方案:在dmoz_spider.py中开头加上路径的导入
然后在此之后再尝试
3.scrapy [boto] ERROR: Caught exception reading instance data
具体表现:
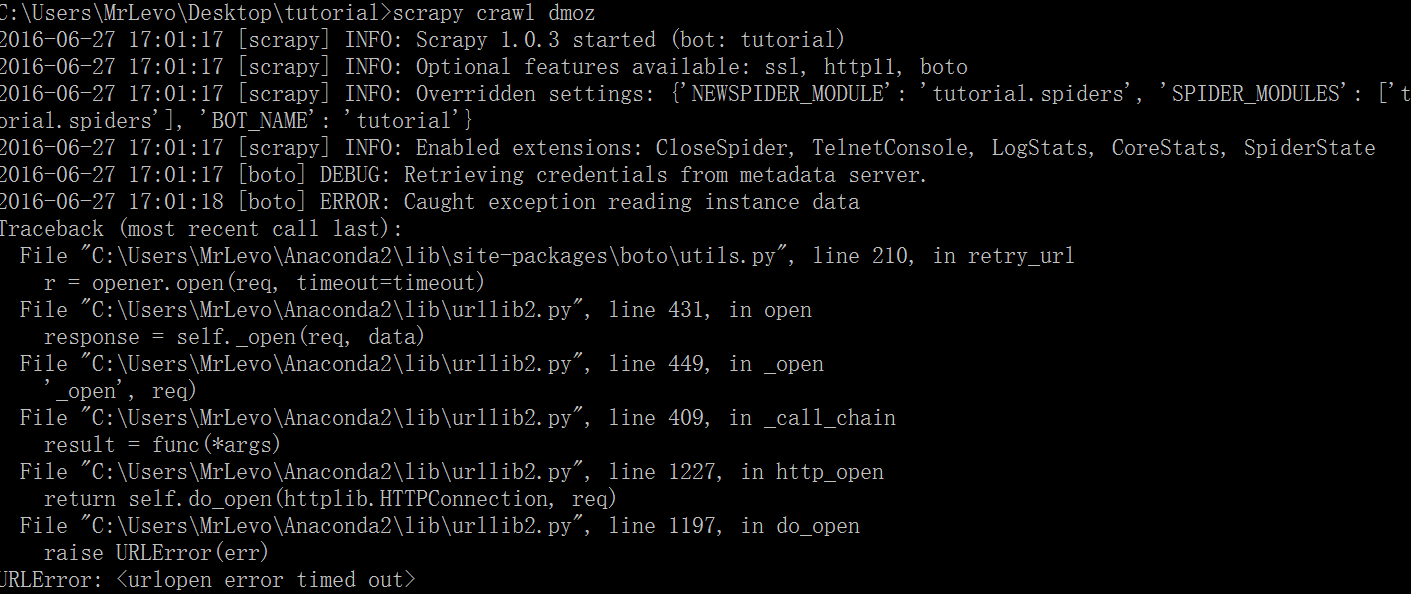
问题原因:未知(以后补充)
解决方案:
1.在setting.py中加入
2如果问题还没解决:
尝试在dmoz_spider中加入:
这只是不抛出错误而已,对后续爬内容没有影响,暂且只能这么解决,dmoz还是没有出现。如果有谁知道,麻烦留言告知,先谢过。

目的:初结识,测试shell,response
以下是dmoz_spider.py代码,放在spiders文件夹下,和 init.py同一级目录。

以下是items.py代码:
还是不清楚的话,应该是这样的:
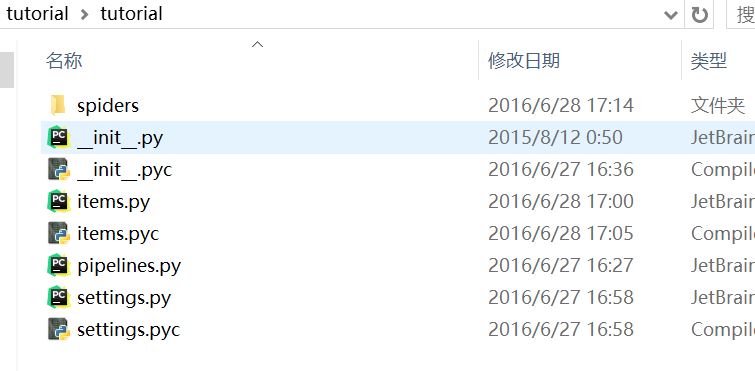
最初一级目录是这样的:
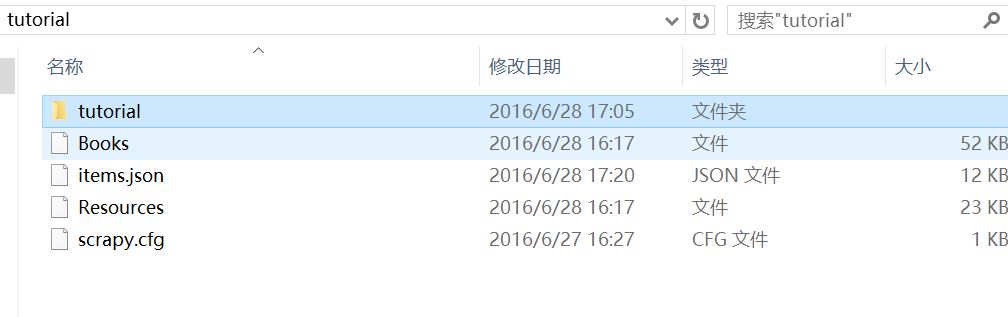
这都是我跑完几次之后的,上面那张图刚开始之后cfg文件和tutorial文件夹而已!这个之后说
接下来是在cmd窗口开始爬:
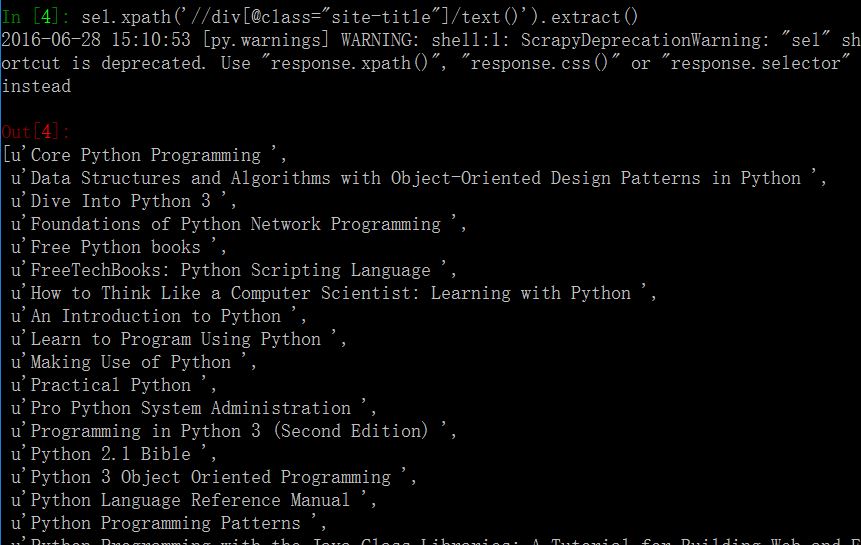
这是title的目录结构
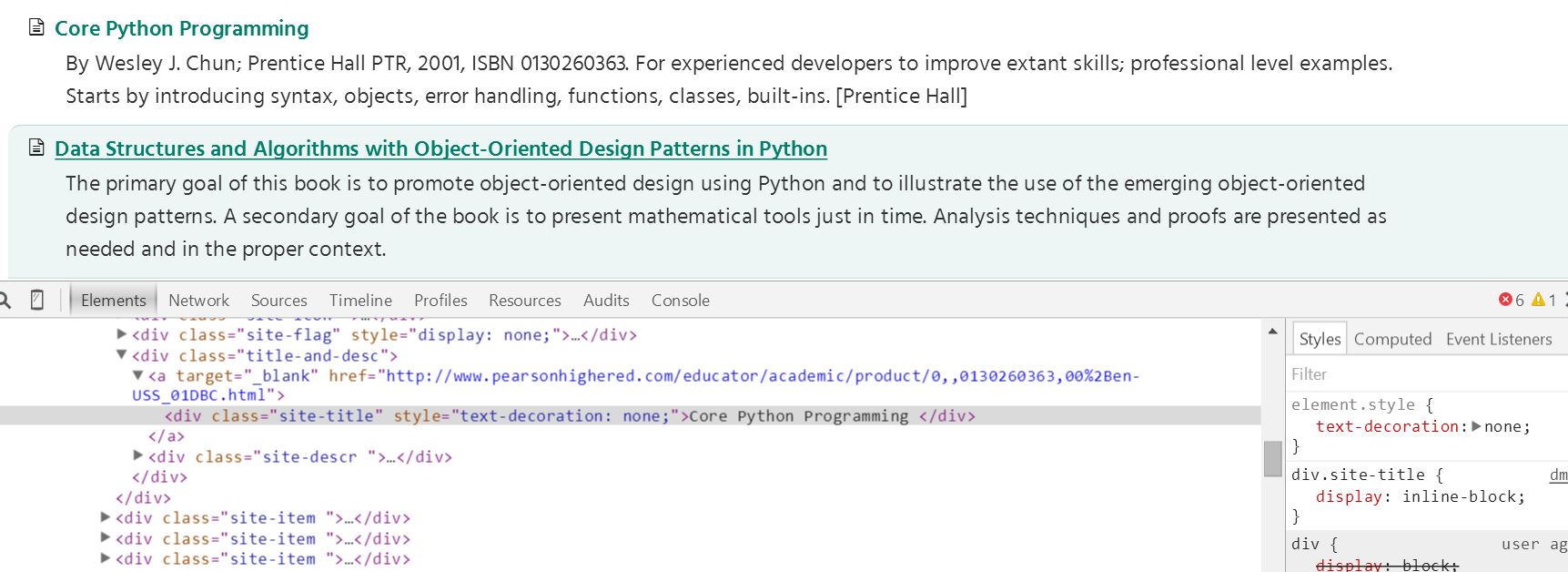
在cmd窗应该这样:
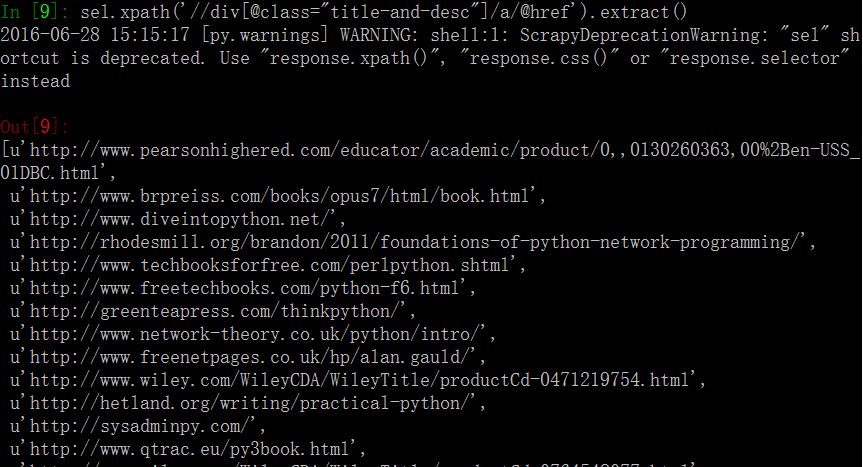
这是link超链接目录结构:

取出超链接应该这样操作:
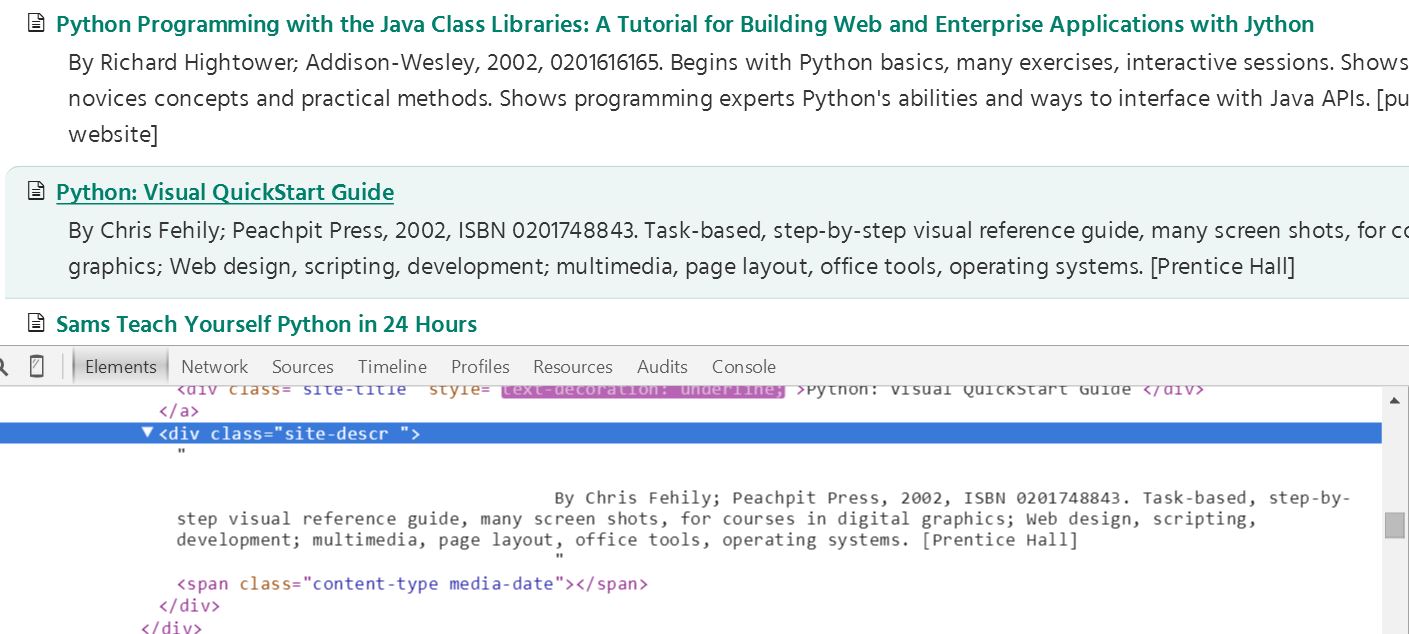
这是desc的目录结构:
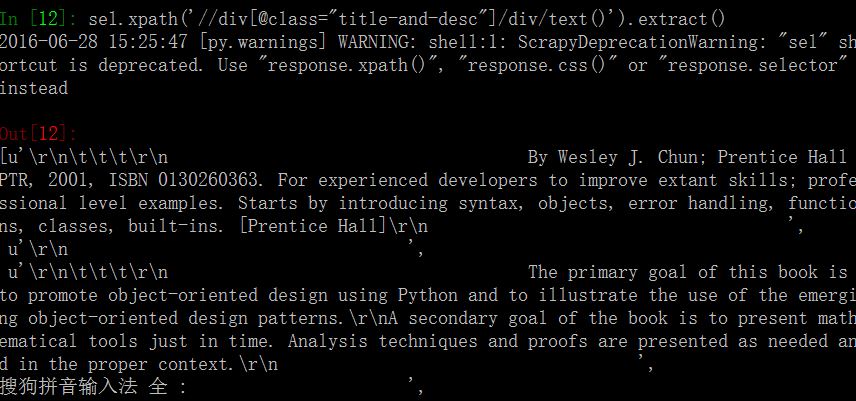
需要这样操作:
至于怎么操作,为什么是sel,//,@什么的,具体看开头给的超链接,那里很详细写,我这里只放更新后的实现代码!!!
目的:将title,link,desc存储在dict中,对应起来。
还有items代码
items.py没怎么修改,就改规范了点。
正常爬应该是这样的;
很多,没截完,可以看出,对应存储在dict中了
之后就把它导出成json文件:
然后项目文件夹中会出现一个items.json文件,可以用编辑器打开,是这逼样的;
全部抓起来了,但是空格还没去,还有一些乱七八糟的/t/n什么的,我想用正则抓一下或者split试一下应该可以,主要是Scrapy的使用,累死宝宝了,再此更新下Dmoz的抓取代码。虽然很基础很基础,但是初学者需要瓢啊!!!给我们瓢啊!!不然怎么画葫芦!!!!(委屈脸)

IDE Pycharm 5.0.3
Scrapy 1.0.3
什么是Scrapy?
Scrapy框架不多解释,这篇很详细,但是代码部分不适用于现在的Dmoz网站,什么是Scrapy框架,第一个小程序请务必先看这个,不然看以下会云里雾里哒
起因
昨天开始接触Scrapy框架,感觉还是挺新奇的,但是跟着例子做,基本上网上的教程,几乎完全一致的对Dmoz网站进行目录抓取,测试对其title对应的link,description进行抓取,而且!代码都特么是一样的,时间久远,Dmoz网站的编码和他们出教程的时候已经不一样了,虽然,现在看来只不过是对参数进行替换而已,但对于我们这种刚接触Scrapy的小白来说,首先得依瓢画葫芦,但是这个瓢,都特么是坏的!!遇到问题和解决方案
折腾了我差不多三个小时(见笑了),收获在于解决了:1.IndentationError: unindent does not match any outer indentation level
问题原因:请不要使用Notepad++进行编辑,不是说不好,但是纠错能力显然没有Pycharm来得好,编辑过程中如果有拷贝代码的现象,请注意缩进!!!Python的灵魂在于缩进!
解决方案:使用Pycharm进行编辑,拷贝时候注意缩进!
2.ImportError: No module named tutorial.items
问题原因:执行路径中没有tutorial目录,所以找不到模块和包
解决方案:在dmoz_spider.py中开头加上路径的导入
import sys
try:
sys.path.append("C:\\Users\\MrLevo\\Desktop\\tutorial")
#每台电脑路径不一样,自己看tutorial项目在哪
except:
pass
#print sys.path然后在此之后再尝试
from tutorial.items import DmozItem
3.scrapy [boto] ERROR: Caught exception reading instance data
具体表现:
问题原因:未知(以后补充)
解决方案:
1.在setting.py中加入
DOWNLOAD_HANDLERS = {'s3': None,}2如果问题还没解决:
尝试在dmoz_spider中加入:
from scrapy import optional_features
optional_features.remove('boto')这只是不抛出错误而已,对后续爬内容没有影响,暂且只能这么解决,dmoz还是没有出现。如果有谁知道,麻烦留言告知,先谢过。
改后的代码–第一阶段
第一阶段代码目的:初结识,测试shell,response
以下是dmoz_spider.py代码,放在spiders文件夹下,和 init.py同一级目录。
from scrapy.spiders import Spider
from scrapy.selector import Selector
import scrapy
from scrapy import optional_features optional_features.remove('boto')
#为了解决scrapy [boto] ERROR: Caught exception reading instance data问题
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmoz.org']
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename,'wb') as f:
f.write(response.body)
以下是items.py代码:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class DmozlItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() link = scrapy.Field() desc = scrapy.Field()
还是不清楚的话,应该是这样的:
最初一级目录是这样的:
这都是我跑完几次之后的,上面那张图刚开始之后cfg文件和tutorial文件夹而已!这个之后说
接下来是在cmd窗口开始爬:
这是title的目录结构
在cmd窗应该这样:
这是link超链接目录结构:
取出超链接应该这样操作:
这是desc的目录结构:
需要这样操作:
至于怎么操作,为什么是sel,//,@什么的,具体看开头给的超链接,那里很详细写,我这里只放更新后的实现代码!!!
改后的代码–第二阶段
dmoz_spider.py代码目的:将title,link,desc存储在dict中,对应起来。
import sys
try:
sys.path.append("C:\\Users\\MrLevo\\Desktop\\tutorial")
except:
pass
#print sys.path
from tutorial.items import DmozItem
from scrapy.spiders import Spider
from scrapy.selector import Selector
import scrapy
from scrapy import optional_features
optional_features.remove('boto')
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmoz.org']
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//div[@class="title-and-desc"]')
items = []
for site in sites:
item=DmozItem()
item['title'] = site.xpath('a/div/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('div/text()').extract()
items.append(item)
return items还有items代码
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.item import Item,Field class DmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() link = Field() desc = Field()
items.py没怎么修改,就改规范了点。
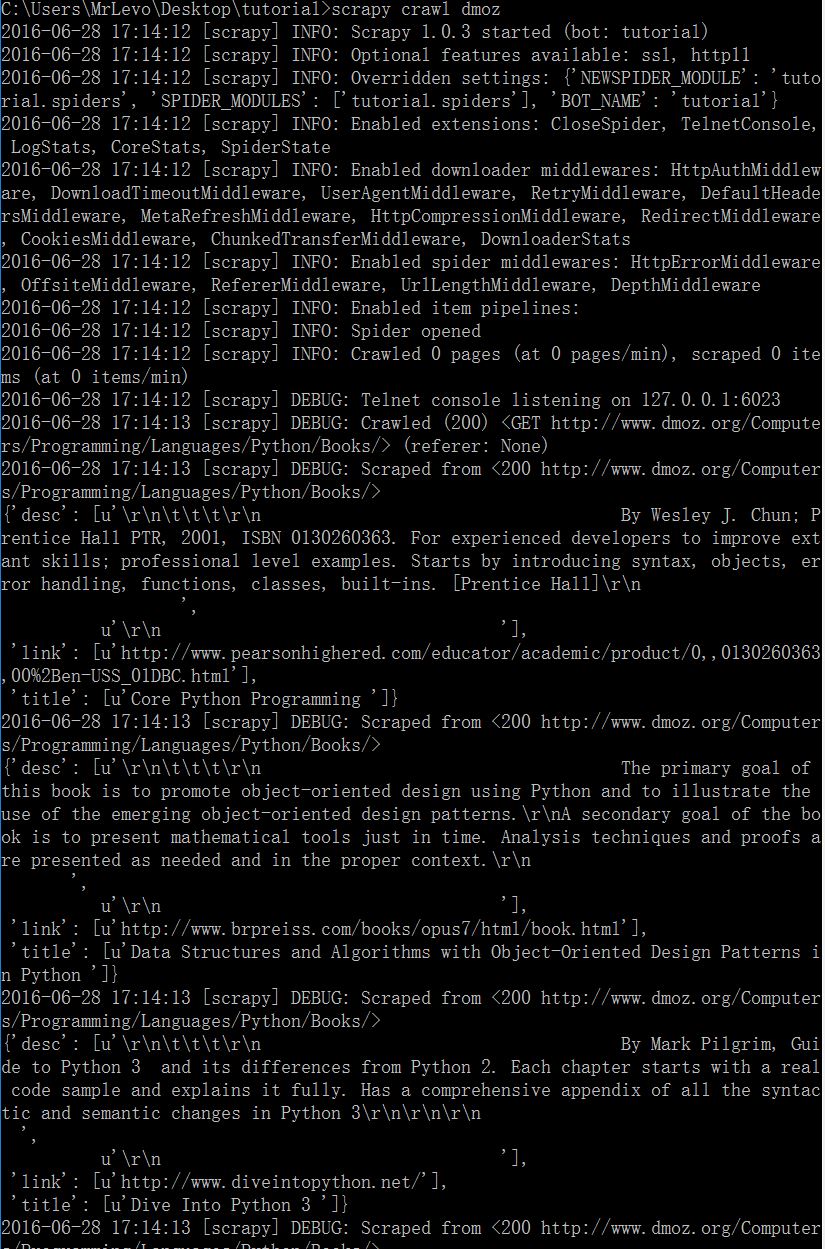
正常爬应该是这样的;
很多,没截完,可以看出,对应存储在dict中了
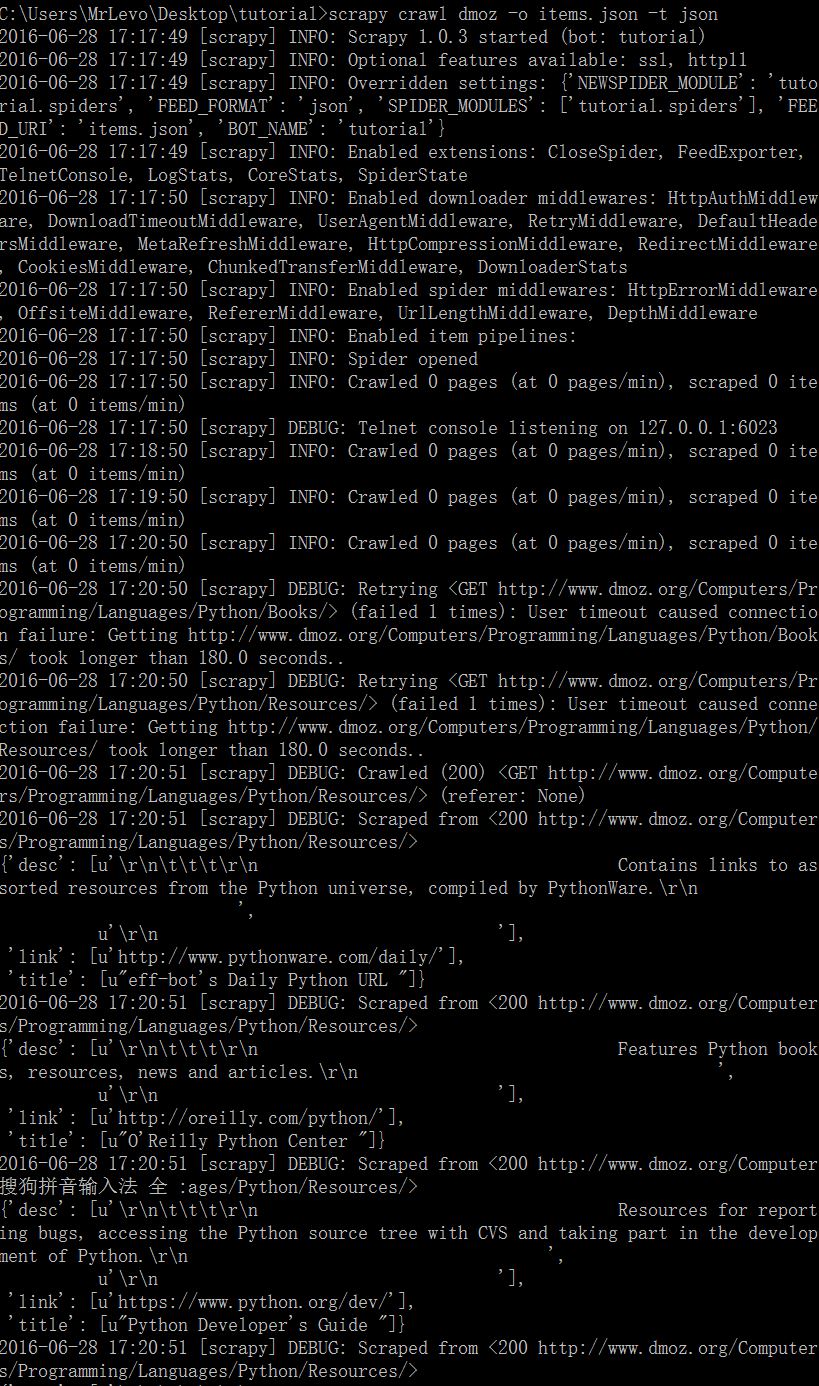
之后就把它导出成json文件:
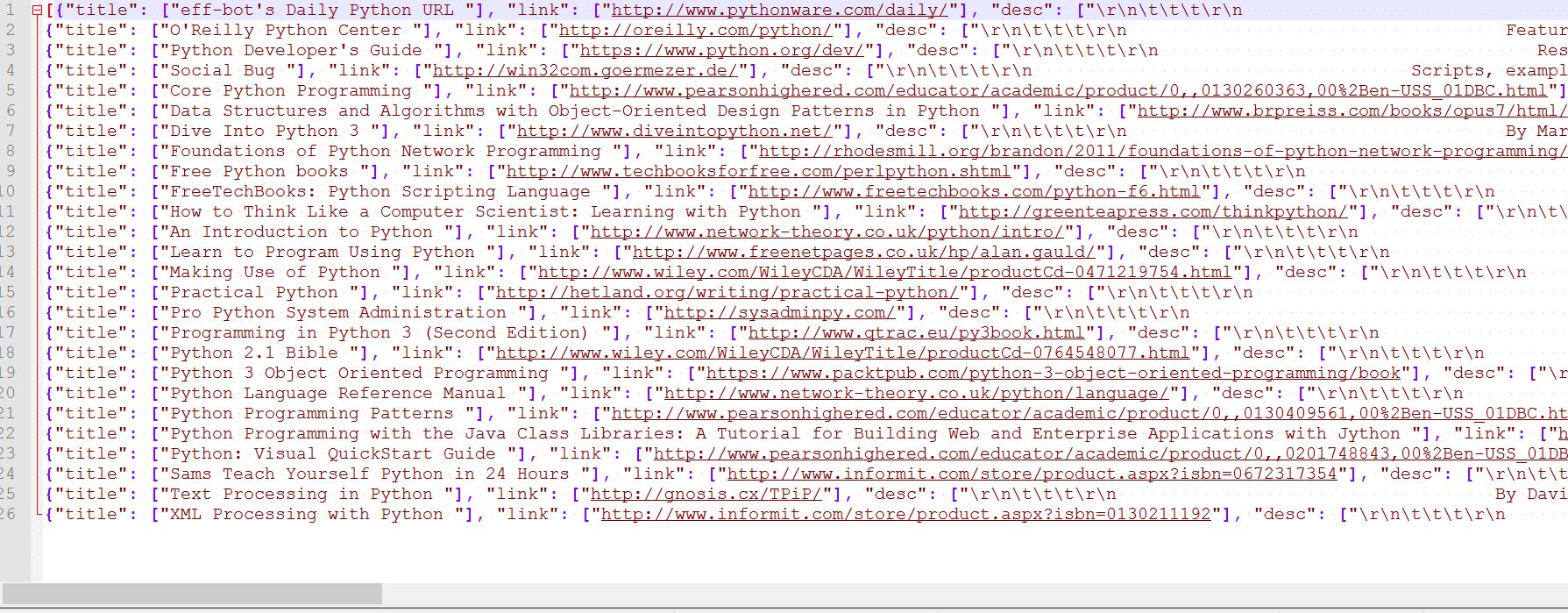
然后项目文件夹中会出现一个items.json文件,可以用编辑器打开,是这逼样的;
全部抓起来了,但是空格还没去,还有一些乱七八糟的/t/n什么的,我想用正则抓一下或者split试一下应该可以,主要是Scrapy的使用,累死宝宝了,再此更新下Dmoz的抓取代码。虽然很基础很基础,但是初学者需要瓢啊!!!给我们瓢啊!!不然怎么画葫芦!!!!(委屈脸)

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定