关于分布式系统的数据一致性问题(一)
2016-06-28 18:01
225 查看
现在先抛出问题,假设有一个主数据中心在北京M,然后有成都A,上海B两个地方数据中心,现在的问题是,假设成都上海各自的数据中心有记录变更,需要先同步到主数据中心,主数据中心更新完成之后,在把最新的数据分发到上海,成都的地方数据中心A,地方数据中心更新数据,保持和主数据中心一致性(数据库结构完全一致)。数据更新的消息是通过一台中心的MQ进行转发。
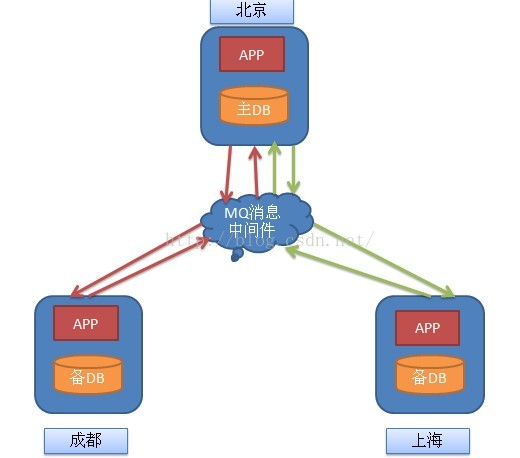
先把问题简单化处理,假设A增加一条记录Message_A,发送到M,B增加一条记录MESSAGE_B发送到M,都是通过MQ服务器进行转发,那么M系统接收到条消息,增加两条数据,那么M在把增加的消息群发给A,B,A和B找到自己缺失的数据,更新数据库。这样就完成了一个数据的同步。
从正常情况下来看,都没有问题,逻辑完全合理,但是请考虑以下三个问题
1如何保证A->M的消息,M一定接收到了,同样,如何保证M->A的消息,M一定接收到了
2如果数据需要一致性更新,比如A发送了三条消息给M,M要么全部保存,要么全部不保存,不能够只保存其中的几条记录。我们假设更新的数据是一条条发送的。
3假设同时A发送了多条更新请求,如何保证顺序性要求?
这两个问题就是分布式环境下数据一致性的问题
对于第一个问题,比较好解决,我们先看看一个tcp/ip协议链接建立的过程
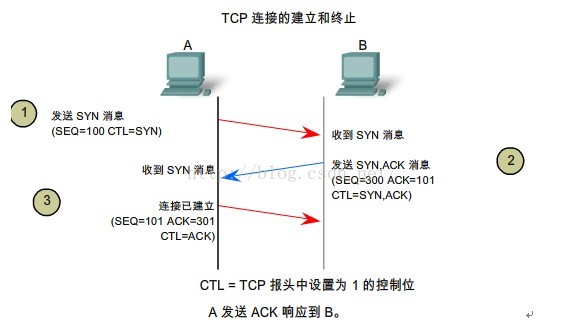
我们的思路可以从这个上面出发,在简化一下,就一个请求,一个应答。
简单的通信模型是这样的
A->M :你收到我的一条消息没有,消息的ID是12345
M->A: 我收到了你的一条消息数据,消息数据是ID;12345
这样就一个请求,一个应答,就完成了一次可靠性的传输。如果A一致没有收到M的应答,就不断的重试。这个时候M就必须保证幂等性。不能重复的处理消息。那么最极端的情况是,怎么也收不到M的应答,这个时候是系统故障。自己检查一下吧。
这么设计就要求,A在发送消息的时候持久化这个消息的数据内容,然后不断的重试,一旦接收到M的应答,就删除这条消息。同样,M端也是一样的。不要相信MQ的持久化机制,不是很靠谱的。
那么M给A发送消息也采取类似的原理就可以了。
下面在看看第二个问题,如何保持数据的一致性更新,这个还是可以参考TCP/IP的协议。
首先A发送一条消息给M:我要发送一批消息数据给你,批次号是10000,数据是5条。
M发送一条消息给A:ok,我准备好了,批次号是10000,发送方你A
接着A发送5条消息给M,消息ID分别为1,2,3,4,5,批次号是10000,
紧接着,A发送一个信息给M:我已经完成5小消息的发送,你要提交数据更新了
接下来可能发送两种情况
1那么M发送消息给A:ok,我收到了5条消息,开始提交数据
2那么M也可以发送给A:我收到了5条消息,但是还缺少,请你重新发送,那么A就继续发送,直到A收到M成功的应答。
整个过程相当复杂。这个也就是数据一旦分布了,带来最大的问题就是数据一致性的问题。这个成本非常高。
对于第三个问题,这个就比较复杂了
这个最核心的问题就是消息的顺序性,我们只能在每个消息发一个消息的序列号,但是还是没有最好解决这个问题的办法。因为消息接收方不知道顺序。因为即使给他了序列号,也没有办法告诉他,这个应该何时处理。最好的办法是在第二种方式的基础作为一个批次来更新。
这个只是以最简单的例子来说明一下分布式系统的要保证数据一致性是一件代价很大的事情。当然有的博主会说,这个何必这么复杂,直接数据库同步不就可以了。这个例子当然是没有问题的,万一这个几个库的模型都不一样,我发送消息要处理的事情不一样的。怎么办?
先把问题简单化处理,假设A增加一条记录Message_A,发送到M,B增加一条记录MESSAGE_B发送到M,都是通过MQ服务器进行转发,那么M系统接收到条消息,增加两条数据,那么M在把增加的消息群发给A,B,A和B找到自己缺失的数据,更新数据库。这样就完成了一个数据的同步。
从正常情况下来看,都没有问题,逻辑完全合理,但是请考虑以下三个问题
1如何保证A->M的消息,M一定接收到了,同样,如何保证M->A的消息,M一定接收到了
2如果数据需要一致性更新,比如A发送了三条消息给M,M要么全部保存,要么全部不保存,不能够只保存其中的几条记录。我们假设更新的数据是一条条发送的。
3假设同时A发送了多条更新请求,如何保证顺序性要求?
这两个问题就是分布式环境下数据一致性的问题
对于第一个问题,比较好解决,我们先看看一个tcp/ip协议链接建立的过程
我们的思路可以从这个上面出发,在简化一下,就一个请求,一个应答。
简单的通信模型是这样的
A->M :你收到我的一条消息没有,消息的ID是12345
M->A: 我收到了你的一条消息数据,消息数据是ID;12345
这样就一个请求,一个应答,就完成了一次可靠性的传输。如果A一致没有收到M的应答,就不断的重试。这个时候M就必须保证幂等性。不能重复的处理消息。那么最极端的情况是,怎么也收不到M的应答,这个时候是系统故障。自己检查一下吧。
这么设计就要求,A在发送消息的时候持久化这个消息的数据内容,然后不断的重试,一旦接收到M的应答,就删除这条消息。同样,M端也是一样的。不要相信MQ的持久化机制,不是很靠谱的。
那么M给A发送消息也采取类似的原理就可以了。
下面在看看第二个问题,如何保持数据的一致性更新,这个还是可以参考TCP/IP的协议。
首先A发送一条消息给M:我要发送一批消息数据给你,批次号是10000,数据是5条。
M发送一条消息给A:ok,我准备好了,批次号是10000,发送方你A
接着A发送5条消息给M,消息ID分别为1,2,3,4,5,批次号是10000,
紧接着,A发送一个信息给M:我已经完成5小消息的发送,你要提交数据更新了
接下来可能发送两种情况
1那么M发送消息给A:ok,我收到了5条消息,开始提交数据
2那么M也可以发送给A:我收到了5条消息,但是还缺少,请你重新发送,那么A就继续发送,直到A收到M成功的应答。
整个过程相当复杂。这个也就是数据一旦分布了,带来最大的问题就是数据一致性的问题。这个成本非常高。
对于第三个问题,这个就比较复杂了
这个最核心的问题就是消息的顺序性,我们只能在每个消息发一个消息的序列号,但是还是没有最好解决这个问题的办法。因为消息接收方不知道顺序。因为即使给他了序列号,也没有办法告诉他,这个应该何时处理。最好的办法是在第二种方式的基础作为一个批次来更新。
这个只是以最简单的例子来说明一下分布式系统的要保证数据一致性是一件代价很大的事情。当然有的博主会说,这个何必这么复杂,直接数据库同步不就可以了。这个例子当然是没有问题的,万一这个几个库的模型都不一样,我发送消息要处理的事情不一样的。怎么办?

相关文章推荐
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- C#分布式事务的超时处理实例分析
- Erlang分布式节点中的注册进程使用实例
- Memcached 分布式缓存实现原理简介
- C++实现的分布式游戏服务端引擎KBEngine详解
- ASP.NET通过分布式Session提升性能
- Spring+Mybatis+Mysql搭建分布式数据库访问框架的方法
- Python使用multiprocessing实现一个最简单的分布式作业调度系统
- 分享一个简单易用的RPC开源项目—Tatala
- 手把手教你配置Hbase完全分布式环境
- 搭建分布式架构2--CentOs下安装Tomcat7(环境准备)
- 搭建分布式架构4--ZooKeeper注册中心安装
- 分布式任务调度平台XXL-JOB
- Glusterfs:趋于成熟的集群文件系统
- 关于glusterfs的directory-layout-spread参数
- tomcat集群扩展session集中管理,Memcached-session-manager...
- 多任务分布式并发处理
- Redis集群快速搭建
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
- 分布式架构之我见 (片段)