Android平台——解析XML数据
2016-06-26 16:09
435 查看
XML(Extensible Markup Language)可扩展标记语言,HTML主要用于显示数据,有预定义标签,而xml主要用于存储和传输数据,没有预定义的标签
在Android中,常见的XML解析器分别为DOM解析器、SAX解析器和PULL解析器
(1)DOM解析器
DOM是一种树型结构,它允许开发人员使用内置的api来对遍历xml数据,检索其中的信息。当DOM解析xml数据时,需要读入整个文档,如果文档过大,将会十分耗内存。
(2)SAX解析器
SAX是一种基于事件的解析方式, Android并未提供对Java StAX API的支持。
(3)PULL解析器
PULL解析器类似SAX,也是基于事件的,且PULL小巧轻便,简单易用,解析速度也快,非常适合在Android移动设备中使用。
下面将对books.xml这个文件进行解析,books.xml代码如下:
使用DOM解析器解析:
运行结果:
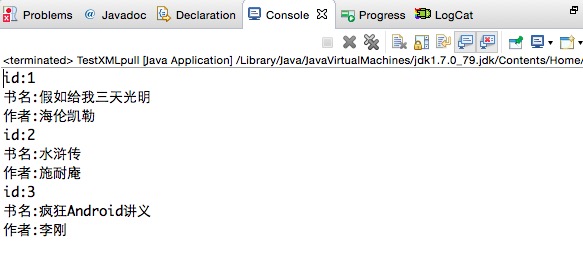
使用PULL解析器解析:
执行结果:

在Android中,常见的XML解析器分别为DOM解析器、SAX解析器和PULL解析器
(1)DOM解析器
DOM是一种树型结构,它允许开发人员使用内置的api来对遍历xml数据,检索其中的信息。当DOM解析xml数据时,需要读入整个文档,如果文档过大,将会十分耗内存。
(2)SAX解析器
SAX是一种基于事件的解析方式, Android并未提供对Java StAX API的支持。
(3)PULL解析器
PULL解析器类似SAX,也是基于事件的,且PULL小巧轻便,简单易用,解析速度也快,非常适合在Android移动设备中使用。
下面将对books.xml这个文件进行解析,books.xml代码如下:
<?xml version="1.0" encoding="utf-8"?> <books> <book id="1"> <name>假如给我三天光明</name> <auther>海伦凯勒</auther> </book> <book id="2"> <name>水浒传</name> <auther>施耐庵</auther> </book> <book id="3"> <name>疯狂Android讲义</name> <auther>李刚</auther> </book> </books>
使用DOM解析器解析:
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
// builder.parse()有多种参数,可以根据项目要求自行选择
Document document = builder.parse(new File("books.xml"));
// 得到根节点<books>
Element element = document.getDocumentElement();
// 得到子节点<book>,返回一个list
NodeList nodeList = element.getElementsByTagName("book");
// 遍历每一个<book>子节点中的内容
for (int i = 0; i < nodeList.getLength(); i++) {
Element book = (Element) nodeList.item(i);
System.out.println("id:" + book.getAttribute("id"));
System.out.println("书名:" + book.getElementsByTagName("name").item(0).getTextContent());
System.out.println("作者:" + book.getElementsByTagName("auther").item(0).getTextContent());
}运行结果:
使用PULL解析器解析:
public class MainActivity extends Activity {
private int type;
private TextView text;
// 得到PULL解析器的一个实例
private XmlPullParser mXmlPullParser = Xml.newPullParser();
private StringBuilder sb = new StringBuilder();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
text = (TextView) findViewById(R.id.text);
new Thread() {
public void run() {
try {
// 设置数据源
mXmlPullParser.setInput(getAssets().open("books.xml"), "utf-8");
// 得到事件类型,比如START_DOCUMENT,END_DOCUMENT,START_TAG,END_TAG....
type = mXmlPullParser.getEventType();
while (type != XmlPullParser.END_DOCUMENT) {
String tagName = mXmlPullParser.getName();
switch (mXmlPullParser.getEventType()) {
case XmlPullParser.START_TAG:
if (tagName.equals("book")) {
// 获取属性值
sb.append("id:" + mXmlPullParser.getAttributeValue(null, "id") + "\n");
} else if (tagName.equals("name")) {
// 获取name标签的值
sb.append("书名:" + mXmlPullParser.nextText() + "\n");
} else if (tagName.equals("auther")) {
// 获取auther标签的值
sb.append("作者:" + mXmlPullParser.nextText() + "\n");
}
break;
case XmlPullParser.END_TAG:
break;
}
// 下一个标签
type = mXmlPullParser.next();
}
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
runOnUiThread(new Runnable() {
public void run() {
text.setText(sb.toString());
}
});
};
}.start();
}
}执行结果:

相关文章推荐
- 使用C++实现JNI接口需要注意的事项
- Android IPC进程间通讯机制
- Android Manifest 用法
- [转载]Activity中ConfigChanges属性的用法
- Android之获取手机上的图片和视频缩略图thumbnails
- Android之使用Http协议实现文件上传功能
- Android学习笔记(二九):嵌入浏览器
- android string.xml文件中的整型和string型代替
- i-jetty环境搭配与编译
- android之定时器AlarmManager
- android wifi 无线调试
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- android 代码实现控件之间的间距
- android FragmentPagerAdapter的“标准”配置
- Android"解决"onTouch和onClick的冲突问题
- android:installLocation简析
- android searchView的关闭事件
- SourceProvider.getJniDirectories