Twitter分布式自增ID算法Snowflake
2016-06-25 19:43
218 查看
Twitter分布式自增ID算法Snowflake
在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位
机器ID 10位 毫秒内序列12位。
在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
把时间戳,工作机器id,序列号组合在一起。
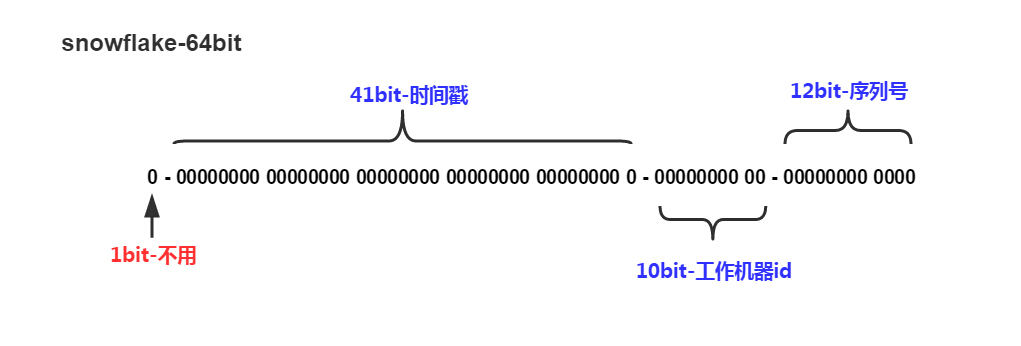
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
uint64_t generateStamp()
{
timeval tv;
gettimeofday(&tv, 0);
return(uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
}
默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。如果你只给时间戳分配39个bit使用,那么根据同样的算法最后年份 = 17.4年。
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
这里的解决方案是需要一个工作id分配的进程,可以使用自己编写一个简单进程来记录分配id,或者利用Mysql auto_increment机制也可以达到效果。

工作进程与工作id分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的id数据落文件,下一次启动直接读取文件里的id使用。
PS:这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记进程id,后5个bit标记线程id之类:D
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
uint64_t waitNextMs(uint64_t lastStamp)
{
uint64_t cur = 0;
do{
cur = generateStamp();
}while(cur <= lastStamp);
returncur;
}
总体来说,是一个很高效很方便的GUID产生算法,一个int64_t字段就可以胜任,不像现在主流128bit的GUID算法,即使无法保证严格的id序列性,但是对于特定的业务,比如用做游戏服务器端的GUID产生会很方便。另外,在多线程的环境下,序列号使用atomic可以在代码实现上有效减少锁的密度。
在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位
机器ID 10位 毫秒内序列12位。
在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
Snowflake – 时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。uint64_t generateStamp()
{
timeval tv;
gettimeofday(&tv, 0);
return(uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
}
默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。如果你只给时间戳分配39个bit使用,那么根据同样的算法最后年份 = 17.4年。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。这里的解决方案是需要一个工作id分配的进程,可以使用自己编写一个简单进程来记录分配id,或者利用Mysql auto_increment机制也可以达到效果。
工作进程与工作id分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的id数据落文件,下一次启动直接读取文件里的id使用。
PS:这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记进程id,后5个bit标记线程id之类:D
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。uint64_t waitNextMs(uint64_t lastStamp)
{
uint64_t cur = 0;
do{
cur = generateStamp();
}while(cur <= lastStamp);
returncur;
}
总体来说,是一个很高效很方便的GUID产生算法,一个int64_t字段就可以胜任,不像现在主流128bit的GUID算法,即使无法保证严格的id序列性,但是对于特定的业务,比如用做游戏服务器端的GUID产生会很方便。另外,在多线程的环境下,序列号使用atomic可以在代码实现上有效减少锁的密度。

相关文章推荐
- ThinkPHP框架学习(1)
- JavaScript利用数组、对象和迭代实现高效率fibonacci数列
- Linux 终端下颜色的输出
- Electron的第一个应用
- Ubuntu 下 使用 adb logcat 显示 Android 日志
- Java实现Mybatis将数据批量插入到Oracle数据库
- HTML5之Ajax跨域的问题和处理
- 表示数值的字符串
- ConcurrentHashMap源代码解读
- The certificate used to sign "app名" has either expired
- Hadoop序列化
- 使用mysql的Concat链接数据
- Mac OS系统磁盘空间不断减少,直到为0
- 提高项目11-让吃货失望的菜单
- 写程序的过程中产生疑惑
- Android Gson解析Json(常规使用)
- hadoop HDFS入门
- PHP中对于错误信息的提示配置?
- HTML5之窗口间通信
- Android各大网络请求库的比较及实战