Hadoop学习笔记
2016-06-24 16:55
176 查看
NameNode中目录/文件的元数据为FsImage
FsImage+内存元数据+EditLog = 效率 + 安全
HDFS的容错:节点、网络、存储
监测节点错误:datanode向namanode定时返回心跳监测网络错误:数据传送后返回ACK
监测存储错误:①传输数据损坏,通过数据的checksum监测;
②硬盘存储数据损坏,通过每个block的checksum监测
MapReduce作业的运行流程
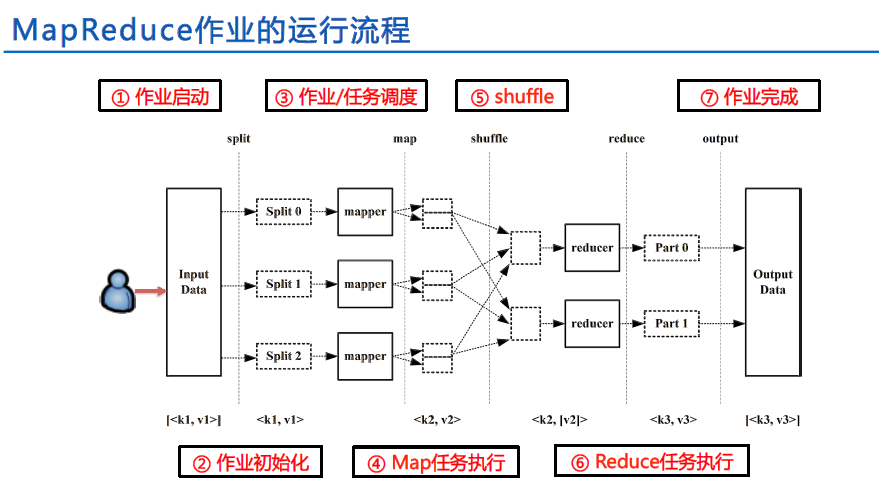
Shuffle处理过程
partition、sort、combine。partition:将map的结果发送到相应的reduce,确保相同的key进入相同reduce。
sort:map后有两次排序。
第一次:文件内部快速排序(sort)。每次spill时,会将中间数据存入本机的一个或几个文件中,并且针对这些文件内部的记录进行一次快速排序;
第二次:多个文件归并排序(merge)。map任务执行完成后会对这些内部排好序的文件做一次归并排序,并将排好序的结果输出到一个大的文件中。
combine:合并map输出的中间数据,减少数据传输,提高处理效率。
MapReduce设计模式
定义:设计模式(Design Pattern)是一套被反复使用、经过分类编目的代码设计经验总结。目的:使用设计模式是为了提高编码效率、提高代码重用率、让代码更容易被他人理解、保证代码可靠性。

相关文章推荐
- LINUX重启MYSQL的命令
- 好的网站运营,就该给用户想要的!关键是怎么给
- Linux内核模块文件组成介绍
- centos7下的kickstart软件包选择被禁止
- linux设置系统环境变量
- yum 指定版本安装
- bash中字符串和数组的遍历
- Linux上开启Telnet服务
- 【OpenCV】有关内存释放 总结
- codesmith 三层架构代码生成
- vim常用按键图示
- centos 使用mutt 命令发送邮件,随笔非教程
- 如何在 KVM 虚拟机上运行 KVM
- 记一次把Windows程序移植到Linux的过程
- CentOS 7下安装MySql 5.6 错误 产生冲突
- OpenCL简单的框架
- nginx的安装及基本配置,及多个域名服务
- Hadoop十年解读与发展预测
- Linux network adapter configuration
- Linux中文件/文本的中文乱码解决方法