Visualizing MNIST 降维探索
2016-06-24 00:00
501 查看
摘要: 最近在学习tensorflow,第一次接触机器学习方面的东西,很多名词第一次听说。总之,探索的过程是艰辛的,但是,艰辛不能白费,为了使艰辛的价值最大化,故希望整理出一些自己的所得,奉献给热爱学习的伙伴们共勉。
这是一篇国外的文章,发表在github上 链接如下 http://colah.github.io/posts/2014-10-Visualizing-MNIST/ 由于是英文版,故由笔者整理为中文版,如有错误,欢迎指正。
正文:
从某些层面上来讲,很少有人能真正理解机器学习。
人类天生可以理解二维和三围(不要想多)的事物 ,二维的事物大家可以回想一下小时候我们的老师在黑板上画三角,正方形;三围的事物大家可以想象魔方。通过后天的努力,人类也可许以想象一下四维的事物,比如克莱因瓶,再高的纬度就很难想象了,但是机器学习领域的计算通常涉及到几千几万甚至几百万的纬度。因此,当你试图把一件事物分解成很多纬度的时候,即使很简单的东西也变得非常难于理解。
难道人类就没有希望了吗?
回答是:不会!别忘了,通常人类通过自身无法自己解决的事情会借助工具来实现它。其实世界上有一种技术叫做“降维”,这种技术可以把高纬度的事物翻译成低纬度的便于人们理解的事物。有了降维技术,很多高纬度的东西就可以通过一定的处理展示在我们的眼前。
这些是我们玩转机器学习的基础,有了这些,我们才能更深入地研究神经网络。
所以第一步,我们来学习降维技术,然后我们需要一个数据集来支撑我们的实验。
MNIST是一个数据集,里面存储了一些28*28像素点的图片,图片的内容是手写的0-9.




MNIST数据集里面的每一张图片其实都可以用一组数字来描述

每一张图片都有28*28像素,我们得到一个28*28的二维数组,我们可以把每个数组描述为28*28= 784纬度的向量,每个向量都包含了一个0-1的值,用来表示这个点的颜色深度(0是白色,1是黑色,0-1之间是灰色),因此我们可以把MNIST看作是一组784纬度的向量的合集。
并不是所有的784维的向量都可以识别成MNIST里面的数字,下面是我们找的一些典型的图片,看起来是不是像旧式电视机没有频道的样子。这些点是随机分布的,有白的,黑的,还有灰的,杂乱无章地组织在了一起。

而MNIST里面的图片通常会显得特征清晰,而且里面的内容显而易见。
关于MNIST的低纬度排列和构成,人们提出了许多理论,还有很多数据为这些理论做支撑。其中,机器学习领域里面有一个比较流行的说法是流体假设:MNIST是一种低纬度流体形态,不断地流经包含它的高纬度空间,并使空间发生变化;还有一种假设类似于拓扑结构:数据就像一个拓扑图一样伸入它的高纬度空间。(才学有限,只能翻译成这样了,感觉很科幻)
但是没有人真正的理解。
MNIST的形态
我们可以先从一维开始入手,这是最简单的。这里的内容,我基本不再参考原版,完全是自己的理解,因为原版的内容过于生涩和专业,我希望第一次看这篇文章的人就能理解里面的内容。我们选取了四张图片,在每张图片上选了一个点,蓝色标记的位置就是我们选取的点,每个点之前我们说过了,都有一个0-1代表的类似于颜色深度的值,从纯白到纯黑。我们选取的点很不幸被蓝色给盖住了,但是我们可以想象的到其实它是什么颜色的。根据颜色深度的不同,我们把他们显示在了这个一维坐标系中。这个坐标系只有一个X轴,从做到右颜色值不断变黑。图片中我们标记的每个点的颜色值都可以在这个坐标轴中找到并对应起来。这就是一张图片里面一个点的一维表述。当然这里的每张图片,我们之前提到过可以看作是784维的。一维只是我们进入这个世界的第一站,接下来第二站:二维。

现在我们从二维世界的角度来继续探究MNIST的形态,阿西巴,真是太激动人心了,刚才我们在每张图片里面选了一个点,构建了一个一维坐标系,现在我们在每张图片里面选取两个点,怎么表述这两个点呢,放到一维坐标系?明显不合适。打个比方,一辆车越走越远,你很难想象把时间和距离都放到一个坐标轴上的情况,因为这两个属性虽然相关但是不同。再增加一个纬度的话就能很好地表述两个点了。在这里,也请各位先不要由坐标点联想到任何函数关系。我们只是简单地通过这个二维坐标系来观察一些事情。

关于这张图,笔者一开始不是很理解,但是把玩了一会之后开始有点明白了,建议看不懂的朋友们也去原网页把玩把玩,这个图在原网页是可以交互的,慢慢就会明白什么意思了。这里有两个坐标轴,每个坐标轴代表了一张图片上一个点的像素颜色强度,坐标系里面每个有颜色的点代表了一张数字图片。坐标点所处的位置跟我们在左边和下边两张图片里面的选点有关。这个点是可以手动选取的,选定的点被蓝色标记。这里我故意在两张图片上选取了同一个点,所以,大家可以看到坐标系上面的点变成了一条直线,并且是45°角对角线。因为在一张图片上,这个点的颜色深度和在另外一张图片上的点颜色深度相同(同一个点嘛)。那么接下来我稍作变换
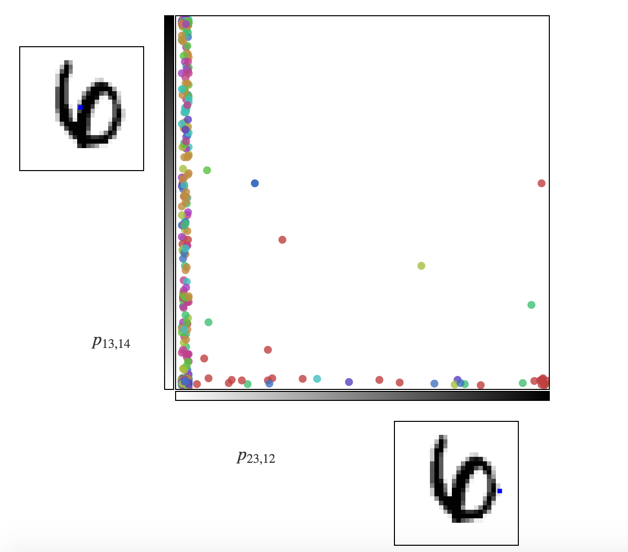
我把下面那张图片的点往右移了一下,坐标系里面的点马上发生了很大的变化。大家可以把鼠标放在坐标系的点上,看看每张图片被选定的像素点的情况,这里我就不做赘述了,有问题可以评论留言。
是不是感觉到了一丝丝喜悦:原来是这样啊,太简单了,这样就实现了高纬度的降维,并且可视化了呀。但是情况并不是这么简单,对于一张图片来说你不可能仅凭两个点来把它描述出来。可以想象到了吧,成千上万的点,成千上万的纬度。
刚才我们从不同的纬度讨论了一下MNIST,现在我们从不同的角度展开探讨,换个看问题的角度也许我们能发现更多的惊喜。
从什么角度看问题现在成为了我们最头疼的事情,试想一下,我们从不同的角度来观察一个784维的物体会有什么样的结果,我知道这很难想象。接下推荐大家去看一篇文章,否则很难理解下面的东西 http://www.360doc.com/content/13/1124/02/9482_331688889.shtml
我们看下面两张图片,显示的图形有两种颜色构成,红色和蓝色两种颜色。这两张图是经过PCA分析了大量图片之后生成的用于识别手写阿拉伯数字的权重分布图,红色和蓝色的分布如下图。看不懂不要紧,接着往下看。

我们看不同数字对于上图左一来说满足的情况如何,首先是1,我们看到第一张图片的数字1很巧妙地跟红色站在了一起,只有顶部和底部很少的部分和蓝色的圆圈重合在一起。我们通过肉眼观察到1这个数字红色占了很大一部分。接下来是2,2基本上也是红色为主,红色区域基本落在了2里面,但是相比1来说,2里面也混入了很多的蓝色。8我们看出了,红色区域两端已经落在了空白部分,只有中间和数字重叠,而蓝色区域更多地落在了8上,明显比2要多,所以从8开始,已经是蓝多红少了。最后是0,我们可以看出,与1相反,极大部分蓝色与0重合而几乎没有红色落在数字0的轮廓区域。我们也将红色与蓝色的比例从大到小做成了一个坐标轴。效果如下:

现在我们可以通过不同的角度来看这些数字的形体了。
又看到这张图了,不过仔细瞪大眼睛看一下就会发现和原来那张不太一样,原来那张只选择了一个点,而现在我们用两种不同的颜色组成了一个分布。我们可以看到,2这个数字在左边分布中稍稍地偏向于蓝色。而在下面那张图片中,轻微地偏向于红色。我们可以看到2字与这两张图片的匹配并不是很好,没有特别明显的特征倾向。

我们观察一下特征明显的点,当我们把鼠标放上去,我们发现,这些点基本是1,这些点满足了这两张图红色权重的特征,而且严重满足。那么这两张图是不是就是筛选1的?在这里我们仔细观察一下这两张权重图,我们发现,第一张图里面有好几种数字的特征,其中蓝色权重我们可以看出来有2,有9,依稀有0;红色有1,有7,还可能有5。下面这张图就简单一些了,好像红色就是1,蓝色就是0。所以我们可以看到1这个数字基本上都较为明显符合图1和图2的红色权重。

我们可以看到0会较为符合蓝色权重,而且较为符合下面一张图的蓝色权重。

现在是不是比之前要好太多了,起码在一张图上面能够较为清晰地把一些数字给区别开了,但是我们还没有达到完美。
如果这些点之间的距离在我们的模型中的一样,那么我们就可以构建出一个非常美妙的模型了(真不知道为啥老外那么多废话)
让我们更加精确一些地描述一下好了,假使我们有两个点,xi和xj,这里讲到xi和xj的距离,其实有两层含义,一个是我们预测的距离,另一个是他们原本的距离。我们用下面这个公式来描述他们的差距。如果这个值越大,说明距离越大,值越小说明距离越接近。如果等于0的话说明完美匹配。这其实是一个优化问题,而深度学习系统正是为了解决这个问题的。
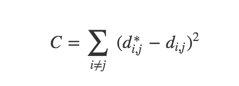
我们接下来随机选择一些点,然后开始进行 gradient descent。
这是一篇国外的文章,发表在github上 链接如下 http://colah.github.io/posts/2014-10-Visualizing-MNIST/ 由于是英文版,故由笔者整理为中文版,如有错误,欢迎指正。
正文:
从某些层面上来讲,很少有人能真正理解机器学习。
人类天生可以理解二维和三围(不要想多)的事物 ,二维的事物大家可以回想一下小时候我们的老师在黑板上画三角,正方形;三围的事物大家可以想象魔方。通过后天的努力,人类也可许以想象一下四维的事物,比如克莱因瓶,再高的纬度就很难想象了,但是机器学习领域的计算通常涉及到几千几万甚至几百万的纬度。因此,当你试图把一件事物分解成很多纬度的时候,即使很简单的东西也变得非常难于理解。
难道人类就没有希望了吗?
回答是:不会!别忘了,通常人类通过自身无法自己解决的事情会借助工具来实现它。其实世界上有一种技术叫做“降维”,这种技术可以把高纬度的事物翻译成低纬度的便于人们理解的事物。有了降维技术,很多高纬度的东西就可以通过一定的处理展示在我们的眼前。
这些是我们玩转机器学习的基础,有了这些,我们才能更深入地研究神经网络。
所以第一步,我们来学习降维技术,然后我们需要一个数据集来支撑我们的实验。
MNIST是一个数据集,里面存储了一些28*28像素点的图片,图片的内容是手写的0-9.
MNIST数据集里面的每一张图片其实都可以用一组数字来描述
每一张图片都有28*28像素,我们得到一个28*28的二维数组,我们可以把每个数组描述为28*28= 784纬度的向量,每个向量都包含了一个0-1的值,用来表示这个点的颜色深度(0是白色,1是黑色,0-1之间是灰色),因此我们可以把MNIST看作是一组784纬度的向量的合集。
并不是所有的784维的向量都可以识别成MNIST里面的数字,下面是我们找的一些典型的图片,看起来是不是像旧式电视机没有频道的样子。这些点是随机分布的,有白的,黑的,还有灰的,杂乱无章地组织在了一起。
而MNIST里面的图片通常会显得特征清晰,而且里面的内容显而易见。
关于MNIST的低纬度排列和构成,人们提出了许多理论,还有很多数据为这些理论做支撑。其中,机器学习领域里面有一个比较流行的说法是流体假设:MNIST是一种低纬度流体形态,不断地流经包含它的高纬度空间,并使空间发生变化;还有一种假设类似于拓扑结构:数据就像一个拓扑图一样伸入它的高纬度空间。(才学有限,只能翻译成这样了,感觉很科幻)
但是没有人真正的理解。
MNIST的形态
我们可以先从一维开始入手,这是最简单的。这里的内容,我基本不再参考原版,完全是自己的理解,因为原版的内容过于生涩和专业,我希望第一次看这篇文章的人就能理解里面的内容。我们选取了四张图片,在每张图片上选了一个点,蓝色标记的位置就是我们选取的点,每个点之前我们说过了,都有一个0-1代表的类似于颜色深度的值,从纯白到纯黑。我们选取的点很不幸被蓝色给盖住了,但是我们可以想象的到其实它是什么颜色的。根据颜色深度的不同,我们把他们显示在了这个一维坐标系中。这个坐标系只有一个X轴,从做到右颜色值不断变黑。图片中我们标记的每个点的颜色值都可以在这个坐标轴中找到并对应起来。这就是一张图片里面一个点的一维表述。当然这里的每张图片,我们之前提到过可以看作是784维的。一维只是我们进入这个世界的第一站,接下来第二站:二维。
现在我们从二维世界的角度来继续探究MNIST的形态,阿西巴,真是太激动人心了,刚才我们在每张图片里面选了一个点,构建了一个一维坐标系,现在我们在每张图片里面选取两个点,怎么表述这两个点呢,放到一维坐标系?明显不合适。打个比方,一辆车越走越远,你很难想象把时间和距离都放到一个坐标轴上的情况,因为这两个属性虽然相关但是不同。再增加一个纬度的话就能很好地表述两个点了。在这里,也请各位先不要由坐标点联想到任何函数关系。我们只是简单地通过这个二维坐标系来观察一些事情。
关于这张图,笔者一开始不是很理解,但是把玩了一会之后开始有点明白了,建议看不懂的朋友们也去原网页把玩把玩,这个图在原网页是可以交互的,慢慢就会明白什么意思了。这里有两个坐标轴,每个坐标轴代表了一张图片上一个点的像素颜色强度,坐标系里面每个有颜色的点代表了一张数字图片。坐标点所处的位置跟我们在左边和下边两张图片里面的选点有关。这个点是可以手动选取的,选定的点被蓝色标记。这里我故意在两张图片上选取了同一个点,所以,大家可以看到坐标系上面的点变成了一条直线,并且是45°角对角线。因为在一张图片上,这个点的颜色深度和在另外一张图片上的点颜色深度相同(同一个点嘛)。那么接下来我稍作变换
我把下面那张图片的点往右移了一下,坐标系里面的点马上发生了很大的变化。大家可以把鼠标放在坐标系的点上,看看每张图片被选定的像素点的情况,这里我就不做赘述了,有问题可以评论留言。
是不是感觉到了一丝丝喜悦:原来是这样啊,太简单了,这样就实现了高纬度的降维,并且可视化了呀。但是情况并不是这么简单,对于一张图片来说你不可能仅凭两个点来把它描述出来。可以想象到了吧,成千上万的点,成千上万的纬度。
刚才我们从不同的纬度讨论了一下MNIST,现在我们从不同的角度展开探讨,换个看问题的角度也许我们能发现更多的惊喜。
从什么角度看问题现在成为了我们最头疼的事情,试想一下,我们从不同的角度来观察一个784维的物体会有什么样的结果,我知道这很难想象。接下推荐大家去看一篇文章,否则很难理解下面的东西 http://www.360doc.com/content/13/1124/02/9482_331688889.shtml
我们看下面两张图片,显示的图形有两种颜色构成,红色和蓝色两种颜色。这两张图是经过PCA分析了大量图片之后生成的用于识别手写阿拉伯数字的权重分布图,红色和蓝色的分布如下图。看不懂不要紧,接着往下看。
我们看不同数字对于上图左一来说满足的情况如何,首先是1,我们看到第一张图片的数字1很巧妙地跟红色站在了一起,只有顶部和底部很少的部分和蓝色的圆圈重合在一起。我们通过肉眼观察到1这个数字红色占了很大一部分。接下来是2,2基本上也是红色为主,红色区域基本落在了2里面,但是相比1来说,2里面也混入了很多的蓝色。8我们看出了,红色区域两端已经落在了空白部分,只有中间和数字重叠,而蓝色区域更多地落在了8上,明显比2要多,所以从8开始,已经是蓝多红少了。最后是0,我们可以看出,与1相反,极大部分蓝色与0重合而几乎没有红色落在数字0的轮廓区域。我们也将红色与蓝色的比例从大到小做成了一个坐标轴。效果如下:
现在我们可以通过不同的角度来看这些数字的形体了。
又看到这张图了,不过仔细瞪大眼睛看一下就会发现和原来那张不太一样,原来那张只选择了一个点,而现在我们用两种不同的颜色组成了一个分布。我们可以看到,2这个数字在左边分布中稍稍地偏向于蓝色。而在下面那张图片中,轻微地偏向于红色。我们可以看到2字与这两张图片的匹配并不是很好,没有特别明显的特征倾向。
我们观察一下特征明显的点,当我们把鼠标放上去,我们发现,这些点基本是1,这些点满足了这两张图红色权重的特征,而且严重满足。那么这两张图是不是就是筛选1的?在这里我们仔细观察一下这两张权重图,我们发现,第一张图里面有好几种数字的特征,其中蓝色权重我们可以看出来有2,有9,依稀有0;红色有1,有7,还可能有5。下面这张图就简单一些了,好像红色就是1,蓝色就是0。所以我们可以看到1这个数字基本上都较为明显符合图1和图2的红色权重。
我们可以看到0会较为符合蓝色权重,而且较为符合下面一张图的蓝色权重。
现在是不是比之前要好太多了,起码在一张图上面能够较为清晰地把一些数字给区别开了,但是我们还没有达到完美。
Optimization-Based Dimensionality Reduction
既然我们要达到完美,那么问题来了,完美是怎么定义的?如果这些点之间的距离在我们的模型中的一样,那么我们就可以构建出一个非常美妙的模型了(真不知道为啥老外那么多废话)
让我们更加精确一些地描述一下好了,假使我们有两个点,xi和xj,这里讲到xi和xj的距离,其实有两层含义,一个是我们预测的距离,另一个是他们原本的距离。我们用下面这个公式来描述他们的差距。如果这个值越大,说明距离越大,值越小说明距离越接近。如果等于0的话说明完美匹配。这其实是一个优化问题,而深度学习系统正是为了解决这个问题的。
我们接下来随机选择一些点,然后开始进行 gradient descent。

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- bp神经网络及matlab实现
- 反向传播(Backpropagation)算法的数学原理
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- AI和IA之随想
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能入门教程之十一 最强网络DLSTM 双向长短期记忆网络(阿里小AI实现)
- TensorFlow人工智能入门教程之十四 自动编码机AutoEncoder 网络
- TensorFlow人工智能引擎入门教程所有目录
- Tensorflow 深度学习分布式实现方式
- 如何用70行代码实现深度神经网络算法
- 人工智能冲击下,IT人员如何提前避免被淘汰?
- 你的车有了这样的车载操作系统,溜到飞起
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐
- http-关于application/x-www-form-urlencoded等字符编码的解释说明