MapReduce 进阶:Partitioner 组件
2016-06-21 23:47
465 查看
概述
Partitioner 组件可以让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理。如果这么说让你觉得有一些笼统的话,那么本文可能很适合你,因为本文会依据一个具体的实例进行讲解。版权说明
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年6月21日
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/51730960
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
需求场景
假设我们现在要统计各个省份的男女人数,每个省份的数据单独保存。而我们的原始数据是这样的:Fern girl guangdong Alice girl jiangsu Bunny girl shanghai Amy girl xian Walker boy guangdong Ingram boy shichuang Paul boy shichuang Caroline girl jiangsu Esther girl jiangsu Eve girl tianjing
第一个字段为名字,第二个字段为性别,第三个字段为省份。这是其中一个文件中的内容,全部文件的列表如下:
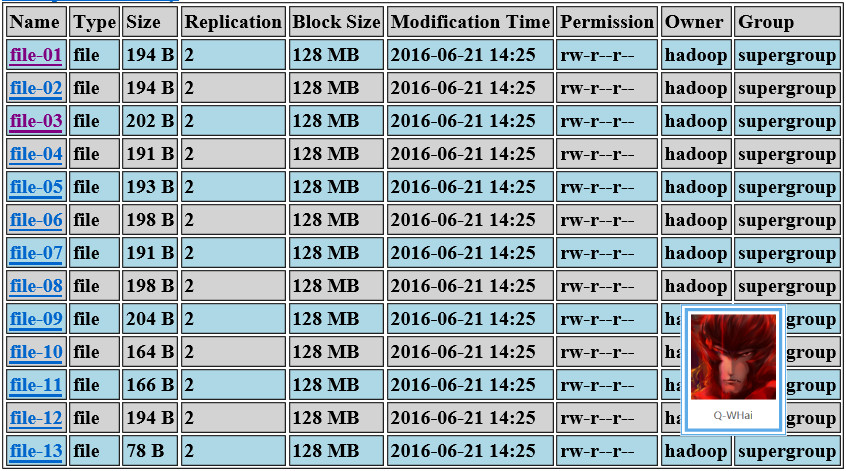
Partitioner 组件
这里我并不打算讨论 Map 与 Reduce 过程,通过前面的学习,这一点我相信你一定是成竹在胸的。HashPartitioner
在一般的 MapReduce 过程中,我们知道可以通过 job.setNumReduceTasks(N) 来创建多个 ReducerTask 进行处理任务。可是,这种情况下,系统会调用默认的 Partitioner 也就是 HashPartitioner 来对 Map 的 key 进行分区。进入 Hadoop 的源码,可以看到 HashPartitioner 的实现其实很简单。如下:
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}HashPartitioner 对分区的处理过程也就是一个 hash 函数的事,hash 的好处是可以很 key 的分布更加随机。可是,hash 处理也有一个比较突出的问题,那就是某一个分区中可能会包含了很多不同的 key。
原因就是因为这里需要对 numReduceTasks 进行取余(取余是必须的,因为 getPartition() 方法的返回值不可以大于 numReduceTasks ),所以你的 hashCode 相差再大也是于事无补。
自定义 Partitioner(Hash)
上面说默认的 HashPartitioner 解决起来会有一些问题,所以这里我们就需要自己定义 Partitioner 组件了。下面是我第一次进行自定义的 Partitioner 组件,也是用到了一个 hashCode()。public static class WordcountHashPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
String location = key.toString().split(":")[0];
return Math.abs(location.hashCode() * 127) % numPartitions;
}
}运行 Hadoop 程序,不出所料也出现相同的问题(key 映射分区的分布不均匀):
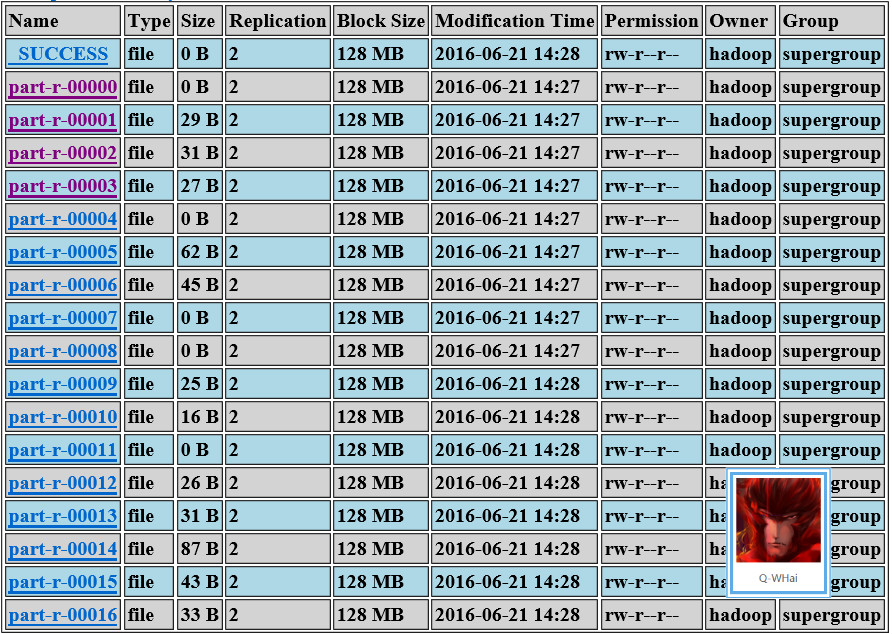
自定义 Partitioner(非 Hash)
从上图的结果中可以看到各个文件的内容相差还是挺大的,尤其是其中还有一些文件没有内容,没有内容的原因是因为,本该写入此文件的数据,被分到了其他分区中了,也就被写入其他文件中了。于是,我修改了 Partitioner 中的代码,不再使用 hash,而是采用一对一映射的方法。代码如下( 这里如果你不喜欢使用 switch … case,那么就使用一些重构手法修改它 ):public static class WordcountHashPartitionerNew extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
String location = key.toString().split(":")[0];
switch (location) {
case "anhui":
return 0;
case "beijing":
return 1;
( ... 此处省略 N 行 ...)
case "zhejiang":
return 16;
}
return 0;
}
}修改之后,再来看执行结果就正常多了。最明显的一点就是没有 0 长度的文件了。检查了其中的文件,也没有发现异常情况。
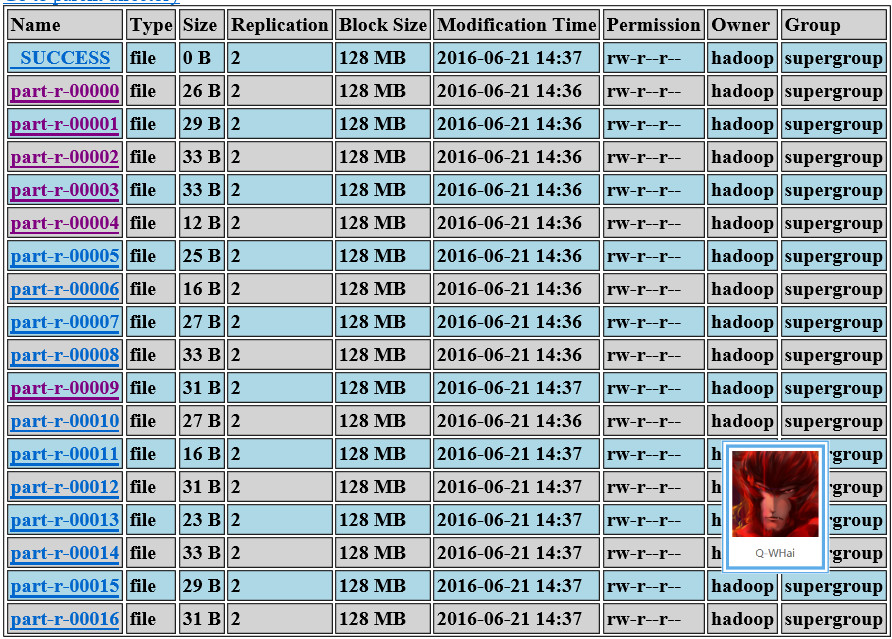
客户端调用
public class PartitionerClient {
( ... 此处省略 N 行 ...)
public static void main(String[] args) throws Exception {
PartitionerClient client = new PartitionerClient();
client.execute(args);
}
private void execute(String[] args) throws Exception {
( ... 此处省略 N 行 ...)
runWordCountJob(inputPath, outputPath);
}
private int runWordCountJob(String inputPath, String outputPath) throws Exception {
( ... 此处省略 N 行 ...)
job.setMapperClass(CorePartitioner.CoreMapper.class);
job.setCombinerClass(CorePartitioner.CoreReducer.class);
job.setPartitionerClass(CorePartitioner.WordcountHashPartitionerNew.class);
job.setNumReduceTasks(17);
job.setReducerClass(CorePartitioner.CoreReducer.class);
( ... 此处省略 N 行 ...)
}
}这里调用的方式也就两句话:
job.setPartitionerClass(CorePartitioner.WordcountHashPartitionerNew.class); job.setNumReduceTasks(17);
前一句没什么好说的,与 job.setMapperClass(CorePartitioner.CoreMapper.class) 都是类似的。关于后一句,也就是设置 ReduceTasks 的个数。这个值会传递给 getPartition() 的 numPartitions 参数。
其他 Partitioner
查看 Partitioner 的 API 可以看到 Partitioner 的 4 个实现类:BinaryPartitioner, HashPartitioner, KeyFieldBasedPartitioner, TotalOrderPartitioner
BinaryPartitioner
HashPartitioner
KeyFieldBasedPartitioner
TotalOrderPartitioner

相关文章推荐
- android Google Map获取地理位置信息的方法
- 详解HDFS Short Circuit Local Reads
- Spark RDD API详解(一) Map和Reduce
- Python中map()函数浅析
- Android使用Google Map浅谈
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- vivi下重新调整分区
- 单机版搭建Hadoop环境图文教程详解
- 逻辑卷管理(LVM) Linux 用户指南
- 建议的服务器分区办法
- 建议的分区办法
- 恢复主引导分区
- SQLServer 通用的分区增加和删除的算法
- 巧妙利用PARTITION分组排名递增特性解决合并连续相同数据行
- Erlang中的映射组Map详细介绍
- c++中map的基本用法和嵌套用法实例分析
- hadoop常见错误以及处理方法详解
- C#判断指定分区是否是ntfs格式的方法