快速了解innodb锁概念
2016-06-21 16:08
190 查看
innodb的锁分两类:lock和latch。
其中latch主要是保证并发线程操作临界资源的正确性,要求时间非常短,所以没有死锁检测机制。latch包括mutex(互斥量)和rwlock(读写锁)。
而lock是面向事务,操作(表、页、行)等对象,用来管理共享资源的并发访问,是有死锁检测机制的。
现在我们要着重讲的是innodb的lock锁,下面我们先来介绍几个概念。
行锁:innodb实现了多粒度锁,作用对象为表则为表锁,作用对象为行(Record)则为行锁。其中行锁包括共享行锁和排他行锁。
共享行锁(S):允许事务读取一行数据。
排他行锁(X):允许事务删除或更新一行数据。
意向锁:数据库需要对细粒度的对象上锁,需要首先给粗粒度的对象上锁。在粗粒度对象上上的锁成为意向锁。innodb的意向锁包括共享意向表锁和排他意向表锁。
共享意向表锁(IS):S锁对应IS锁
排他意向表锁(IX):X锁对应IS锁
锁兼容:兼容是指在同一对象上允许同种或不同种锁同时存在。
lock锁的分类
innodb实现了行级锁,包括行级共享锁(S)及行级排它锁(X),其中S和S是兼容的,其它都是不兼容的。所谓兼容是指对同一记录(row)锁的兼容性情况。innodb通过意向锁实现多粒度锁定。对innodb而言只有表意向共享锁(IS)和表意向排他锁(IX)。在给表加行锁前,需要先对该表加意向锁。因为意向锁是表级别的,而innodb的其它锁是行级别的,所以如果不是全表扫,意向锁是不会对堵塞其它请求的。(小编这里特地做了一个实验,发现select * from t1 where id=5 for update,此时id上面没有索引,走的是全表扫描,确实堵塞了其它任何请求。但给id加上索引,没有走全表时,就没有堵塞其它请求了。)各锁之间的兼容情况请看下图:

简记:含I的锁与含I的锁是相互兼容的
不含I的锁,含S的与含S的兼容与含X的不兼容
不含I的锁,含X的与任何锁都不兼容
如何查看锁
1、通过show engine innodb status\G;
2、直接查询试图 innodb_trx,innodb_locks,innodb_lock_waits;
关于读请求的锁
读请求可以分为两类:一致性锁定读和一致性非锁定读。
一致性锁定读是指读取数据的时候需要给表上加锁,有两种锁定形式:
select * from t1 for update;(加的是X锁)
select * from t1 in share mode;(加的是S锁)
而一致性非锁定读是指读取数据的时候不给表加锁,利用MVCC(multi version concurrency control)特性当读取数据时如果碰到对象已经上了X锁就直接读取镜像数据。又因为事务隔离级别的不同,在不同事务隔离级别下读取的镜像也会不同。
自增长键的锁
一般情况下innodb的主键都会设为自增长,但是当并发往表里插入数据的时候,数据入库的效率会因为自增长的设置而受到影响。5.1.22之前的版本是通过auto_inc locking(锁不是在完成事务后释放而是在完成自增长值插入的SQL后释放)来实现自增长的。5.1.22及之后的版本,innodb提供了一种轻量级互斥量的自增长实现机制,并提供了inodb_atuoinc_lock_mode来控制自增长的模式。该参数的默认值为1.修改为2时效率最高,但是会造成自增长的值不连续并且基于语句级的主从复制也会出现数据不一致的问题。
外键锁问题
生产数据库上是不建议使用外键的。为什么呢。因为对外键的插入和更新会检索父表。而对父表的检索使用的是一致性锁定读(select ... from ...in share mode),这样会堵塞其它事务对父表的请求。
锁的算法
锁有三种算法:
Record Lock:单个记录上的锁
Gap Lock:间隙锁(锁定范围但不包含记录本身)
Next-Key Lock:锁定一个范围并且包括记录本身,Innodb对于行的查询都采用这种算法(为了解决幻读)。但查询的索引含有唯一属性时,innodb存储引擎会对next-key lock进行优化,将其降级为Record Lock。即仅锁住索引本身,而不是范围。若是辅助索引则会分别对当前辅助索引及聚集索引加锁定。对聚集索引采用Record Lock锁定,而辅助索引则使用Next-Key Lock锁定(需要注意的是innodb会对辅助索引的下一个键值上加上gap lock)
阻塞
给一个对象加锁会阻塞其它对象对它的请求,innodb通过设置innodb_lock_wait_timeout来控制等待时间,并通过设置innodb_rollback_on_timeout来设置是否等待超时对事务进行回滚,默认不回滚,超过等待时间则抛出异常,由用户判断是该rollback还是commit。
死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种相互等待的现象。死锁出现的概率是非常低的。innodb内置有死锁检查机制。当出现死锁时会自动回滚占用undo资源少的事务。
锁升级
很多数据库如:SQL server就有锁升级的想象,但是innodb并没有锁升级。这是因为innodb根据事务访问的每个页对锁进行管理,采用位图方式,因此不管一个事务锁住页中的一行还是多个记录,其开销通常都是一样的。
锁的问题
使用锁可能会出现三类问题:
脏读:读到未提交的数据(Read-ncommitted隔离级别);
不可重复读:(Read-committed);
丢失更新:避免丢失更新的方式就是给select ... from ... 加上 for update;
锁的常见的误区
误区一:select col1,col2 from table1 where col1='xxx' 或select count(*) from table1;会锁表;
事实上这样的select语句是不会对访问的资源加锁的。因为这样的查询会使用一致性非锁定读,它访问的是资源的镜像(此处用到的技术是mvcc即multi version concurrency control),所以不会堵塞其它事务也不会被其它事务堵塞(感兴趣的同学可以通过实验验证,不清楚实验方法的话可以私信我)。当然这只是一般的select语句。如果是如下这种格式的语句仍然会对访问的资源加锁:
select col1,col2 from table1 for update;(加X锁)
select col1,col2 from table1 lock in share mode;(加S锁)
关于什么是共享锁(S)什么是互斥锁(X),上面已经做了介绍。我们需要注意的是S锁和S锁是兼容的,S锁和X锁、X锁和X锁是不兼容的。这里说的兼容指的是不同事务对同一行(row)资源的访问的兼容性。显式加锁的select请求,会堵塞其它资源对该表的意向锁请求,从而堵塞其它请求。所以一般情况下,如无特殊需求,是不允许应用对select语句显示加锁的。
误区二:update table1 set col1='xxx' where col2='xxx'不走索引对数据库的性能没有多大影响;
当使用update语句时,首先该语句会对它所访问的表加意向排它锁(IX),如果update语句走了索引,那么它会使用行锁(X) ,只锁定访问的记录及间隙(想了解更多可以百度MySQL锁的算法)。而如果它没有走索引,就会进行全表扫,这时会给整个表加上排他锁(X)。这是这句SQL就会堵塞所有会对该表加意向锁(意向读及意向写)请求,从而堵塞其它请求。
误区三:自增长键会在整个事务过程中,锁住自增长值;
现在我们数据库中的表的主键都是设为自增长的。很多同事认为,这样会不会非常影响数据库的插入效率。事实上使用自增长值确实会影响数据入库的效率,当时mysql 5.1.22版本后,对数据库的自增长设计做了很大的优化,性能已经得到了很大的提升。在5.1.22 之前的版本,使用的是auto_inc locking来生成自增长主键。它并不是在整个事务过程中锁住自增长资源而是在要生产主键的SQL执行完后就释放资源。这就是我们为什么会碰到,事务回滚后,自增长值确仍旧增大的原因。5.1.22及之后,使用了轻量级互斥量(mutex)来实现自增长,并通过inodb_atuoinc_lock_mode来控制自增长的模式。数据库默认改参数值为1,一般情况下都是用mutex来控制自增长,只有当bulk inserts的时候才会使用auto_inc locking模式。
误区四:使用外键加强约束,不会影响性能;
很多同事在设计表结构的时候喜欢使用外键,这里会给大家说明,为什么不建议大家使用外键。
如果使用外键,那么当子表需要更新或插入数据的时候会去检索父表。问题就出现在,检索父表的使用并不是使用的是一致性非锁定读,而是使用的一致性锁定读。
内部检索会是下面的格式:select * from parent where ... lock in share mode;这样的检索就会堵塞同时访问该父表的其它事务的请求,从而影响性能。
其中latch主要是保证并发线程操作临界资源的正确性,要求时间非常短,所以没有死锁检测机制。latch包括mutex(互斥量)和rwlock(读写锁)。
而lock是面向事务,操作(表、页、行)等对象,用来管理共享资源的并发访问,是有死锁检测机制的。
现在我们要着重讲的是innodb的lock锁,下面我们先来介绍几个概念。
行锁:innodb实现了多粒度锁,作用对象为表则为表锁,作用对象为行(Record)则为行锁。其中行锁包括共享行锁和排他行锁。
共享行锁(S):允许事务读取一行数据。
排他行锁(X):允许事务删除或更新一行数据。
意向锁:数据库需要对细粒度的对象上锁,需要首先给粗粒度的对象上锁。在粗粒度对象上上的锁成为意向锁。innodb的意向锁包括共享意向表锁和排他意向表锁。
共享意向表锁(IS):S锁对应IS锁
排他意向表锁(IX):X锁对应IS锁
锁兼容:兼容是指在同一对象上允许同种或不同种锁同时存在。
lock锁的分类
innodb实现了行级锁,包括行级共享锁(S)及行级排它锁(X),其中S和S是兼容的,其它都是不兼容的。所谓兼容是指对同一记录(row)锁的兼容性情况。innodb通过意向锁实现多粒度锁定。对innodb而言只有表意向共享锁(IS)和表意向排他锁(IX)。在给表加行锁前,需要先对该表加意向锁。因为意向锁是表级别的,而innodb的其它锁是行级别的,所以如果不是全表扫,意向锁是不会对堵塞其它请求的。(小编这里特地做了一个实验,发现select * from t1 where id=5 for update,此时id上面没有索引,走的是全表扫描,确实堵塞了其它任何请求。但给id加上索引,没有走全表时,就没有堵塞其它请求了。)各锁之间的兼容情况请看下图:
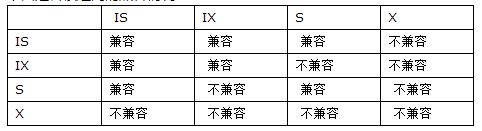
简记:含I的锁与含I的锁是相互兼容的
不含I的锁,含S的与含S的兼容与含X的不兼容
不含I的锁,含X的与任何锁都不兼容
如何查看锁
1、通过show engine innodb status\G;
2、直接查询试图 innodb_trx,innodb_locks,innodb_lock_waits;
关于读请求的锁
读请求可以分为两类:一致性锁定读和一致性非锁定读。
一致性锁定读是指读取数据的时候需要给表上加锁,有两种锁定形式:
select * from t1 for update;(加的是X锁)
select * from t1 in share mode;(加的是S锁)
而一致性非锁定读是指读取数据的时候不给表加锁,利用MVCC(multi version concurrency control)特性当读取数据时如果碰到对象已经上了X锁就直接读取镜像数据。又因为事务隔离级别的不同,在不同事务隔离级别下读取的镜像也会不同。
自增长键的锁
一般情况下innodb的主键都会设为自增长,但是当并发往表里插入数据的时候,数据入库的效率会因为自增长的设置而受到影响。5.1.22之前的版本是通过auto_inc locking(锁不是在完成事务后释放而是在完成自增长值插入的SQL后释放)来实现自增长的。5.1.22及之后的版本,innodb提供了一种轻量级互斥量的自增长实现机制,并提供了inodb_atuoinc_lock_mode来控制自增长的模式。该参数的默认值为1.修改为2时效率最高,但是会造成自增长的值不连续并且基于语句级的主从复制也会出现数据不一致的问题。
外键锁问题
生产数据库上是不建议使用外键的。为什么呢。因为对外键的插入和更新会检索父表。而对父表的检索使用的是一致性锁定读(select ... from ...in share mode),这样会堵塞其它事务对父表的请求。
锁的算法
锁有三种算法:
Record Lock:单个记录上的锁
Gap Lock:间隙锁(锁定范围但不包含记录本身)
Next-Key Lock:锁定一个范围并且包括记录本身,Innodb对于行的查询都采用这种算法(为了解决幻读)。但查询的索引含有唯一属性时,innodb存储引擎会对next-key lock进行优化,将其降级为Record Lock。即仅锁住索引本身,而不是范围。若是辅助索引则会分别对当前辅助索引及聚集索引加锁定。对聚集索引采用Record Lock锁定,而辅助索引则使用Next-Key Lock锁定(需要注意的是innodb会对辅助索引的下一个键值上加上gap lock)
阻塞
给一个对象加锁会阻塞其它对象对它的请求,innodb通过设置innodb_lock_wait_timeout来控制等待时间,并通过设置innodb_rollback_on_timeout来设置是否等待超时对事务进行回滚,默认不回滚,超过等待时间则抛出异常,由用户判断是该rollback还是commit。
死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种相互等待的现象。死锁出现的概率是非常低的。innodb内置有死锁检查机制。当出现死锁时会自动回滚占用undo资源少的事务。
锁升级
很多数据库如:SQL server就有锁升级的想象,但是innodb并没有锁升级。这是因为innodb根据事务访问的每个页对锁进行管理,采用位图方式,因此不管一个事务锁住页中的一行还是多个记录,其开销通常都是一样的。
锁的问题
使用锁可能会出现三类问题:
脏读:读到未提交的数据(Read-ncommitted隔离级别);
不可重复读:(Read-committed);
丢失更新:避免丢失更新的方式就是给select ... from ... 加上 for update;
锁的常见的误区
误区一:select col1,col2 from table1 where col1='xxx' 或select count(*) from table1;会锁表;
事实上这样的select语句是不会对访问的资源加锁的。因为这样的查询会使用一致性非锁定读,它访问的是资源的镜像(此处用到的技术是mvcc即multi version concurrency control),所以不会堵塞其它事务也不会被其它事务堵塞(感兴趣的同学可以通过实验验证,不清楚实验方法的话可以私信我)。当然这只是一般的select语句。如果是如下这种格式的语句仍然会对访问的资源加锁:
select col1,col2 from table1 for update;(加X锁)
select col1,col2 from table1 lock in share mode;(加S锁)
关于什么是共享锁(S)什么是互斥锁(X),上面已经做了介绍。我们需要注意的是S锁和S锁是兼容的,S锁和X锁、X锁和X锁是不兼容的。这里说的兼容指的是不同事务对同一行(row)资源的访问的兼容性。显式加锁的select请求,会堵塞其它资源对该表的意向锁请求,从而堵塞其它请求。所以一般情况下,如无特殊需求,是不允许应用对select语句显示加锁的。
误区二:update table1 set col1='xxx' where col2='xxx'不走索引对数据库的性能没有多大影响;
当使用update语句时,首先该语句会对它所访问的表加意向排它锁(IX),如果update语句走了索引,那么它会使用行锁(X) ,只锁定访问的记录及间隙(想了解更多可以百度MySQL锁的算法)。而如果它没有走索引,就会进行全表扫,这时会给整个表加上排他锁(X)。这是这句SQL就会堵塞所有会对该表加意向锁(意向读及意向写)请求,从而堵塞其它请求。
误区三:自增长键会在整个事务过程中,锁住自增长值;
现在我们数据库中的表的主键都是设为自增长的。很多同事认为,这样会不会非常影响数据库的插入效率。事实上使用自增长值确实会影响数据入库的效率,当时mysql 5.1.22版本后,对数据库的自增长设计做了很大的优化,性能已经得到了很大的提升。在5.1.22 之前的版本,使用的是auto_inc locking来生成自增长主键。它并不是在整个事务过程中锁住自增长资源而是在要生产主键的SQL执行完后就释放资源。这就是我们为什么会碰到,事务回滚后,自增长值确仍旧增大的原因。5.1.22及之后,使用了轻量级互斥量(mutex)来实现自增长,并通过inodb_atuoinc_lock_mode来控制自增长的模式。数据库默认改参数值为1,一般情况下都是用mutex来控制自增长,只有当bulk inserts的时候才会使用auto_inc locking模式。
误区四:使用外键加强约束,不会影响性能;
很多同事在设计表结构的时候喜欢使用外键,这里会给大家说明,为什么不建议大家使用外键。
如果使用外键,那么当子表需要更新或插入数据的时候会去检索父表。问题就出现在,检索父表的使用并不是使用的是一致性非锁定读,而是使用的一致性锁定读。
内部检索会是下面的格式:select * from parent where ... lock in share mode;这样的检索就会堵塞同时访问该父表的其它事务的请求,从而影响性能。

相关文章推荐
- IIS8如何安装和使用URL重写工具-URL Rewrite
- 没有Where条件下group by走索引
- 字符、字符串和文本处理
- Android Volley解析(二)之表单提交篇
- 最大正方形
- 第十五周阅读程序——5
- Activity向Fragment之间传递值
- Pixhawk之姿态解算篇(5)_ECF/EKF/GD介绍
- IOS证书过期,提示This certificate has an invalid issuer
- c++学习main函数输入参数argc argv,vs2008输入参数设置,cmd常用命令
- php中全等(===)和相等(==)的用法区别
- Android消息处理机制(Handler、Looper、MessageQueue与Message)
- maven搭建SpringMVC+Hibernate+Freemarker工程
- iOS自iOS8.0出的指纹解锁api
- 第十篇BootStrap轮播插件使用详解
- CSS小tips
- realtek高清晰音频管理器没有设备高级设置怎么设置音箱与耳机同时响
- 轻松实现Android更换皮肤(主题)
- Nginx根据IP区分实现虚拟主机
- 【p2】·python中嵌套列表list元素输出·模块封装·发布上传(pigeon详细说)