管理维护Replica Sets
2016-06-20 10:09
302 查看
1、读写分离
有一些第三方的工具,提供了一些可以让数据库进行读写分离的工具。我们现在是否有一个疑问,从库要是能进行查询就更好了,这样可以分担主库的大量的查询请求。1、 先向主库中插入一条测试数据
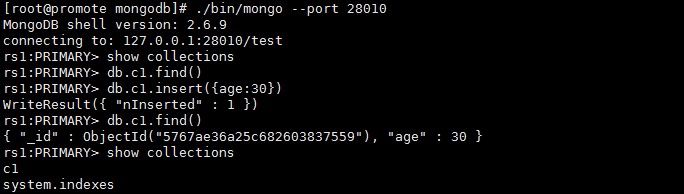
2、 在从库进行查询等操作

当查询时报错了,说明是个从库且不能执行查询的操作
3、 让从库可以读,分担主库的压力
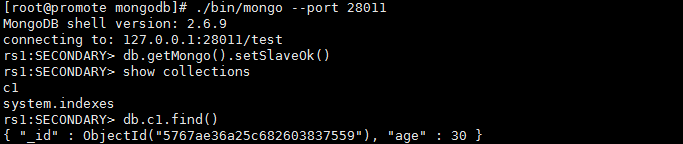
看来我们要是执行db.getMongo().setSlaveOk(), 我们就可查询从库了。
2、故障转移
复制集比传统的Master-Slave 有改进的地方就是他可以进行故障的自动转移,如果我们停掉复制集中的一个成员,那么剩余成员会再自动选举出一个成员,做为主库,例如:我们将28010 这个主库停掉,然后再看一下复制集的状态。1、杀掉28010 端口的MongoDB
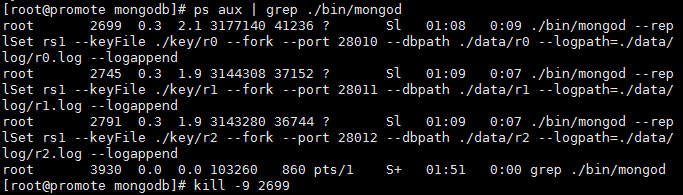
2、 查看复制集状态
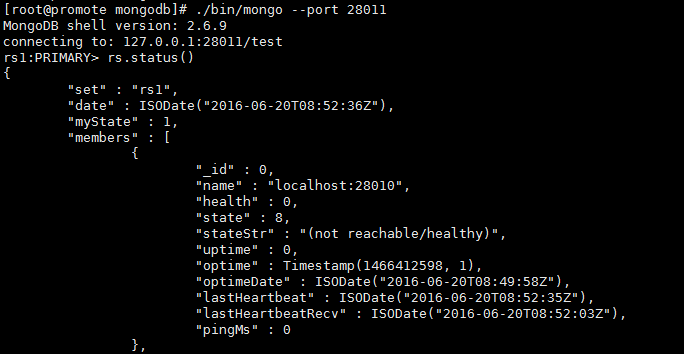
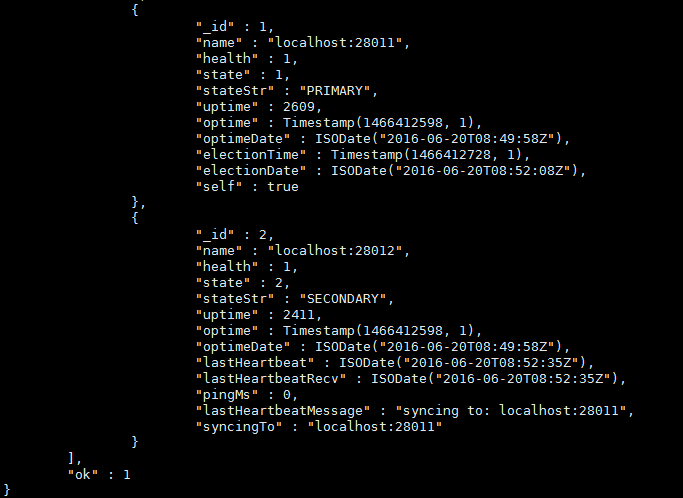
可以看到28010 这个端口的MongoDB 出现了异常,而系统自动选举了28012 这个端口为主,所以这样的故障处理机制,能将系统的稳定性大大提高。
3、增减节点
MongoDB Replica Sets 不仅提供高可用性的解决方案,它也同时提供负载均衡的解决方案,增减Replica Sets 节点在实际应用中非常普遍,例如当应用的读压力暴增时,3 台节点的环境已不能满足需求,那么就需要增加一些节点将压力平均分配一下;当应用的压力小时,可以减少一些节点来减少硬件资源的成本;总之这是一个长期且持续的工作。3、1 增加节点
官方给我们提了2 个方案用于增加节点,一种是通过oplog 来增加节点,一种是通过数据库快照(--fastsync)和oplog 来增加节点,下面将分别介绍。(1)通过oplog增加节点
①、配置并启动新节点,启用28013这个端口给新的节点

②、添加此新节点到现有的Replica Sets

③、查看Replica Sets我们可以清晰的看到内部是如何添加28013这个新节点的.
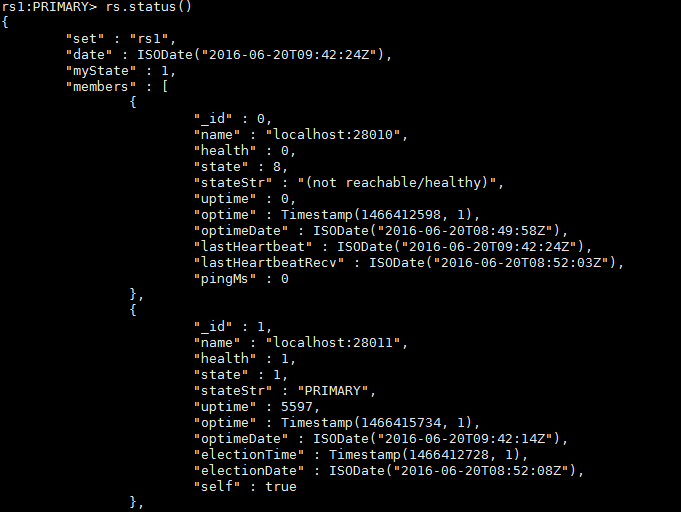
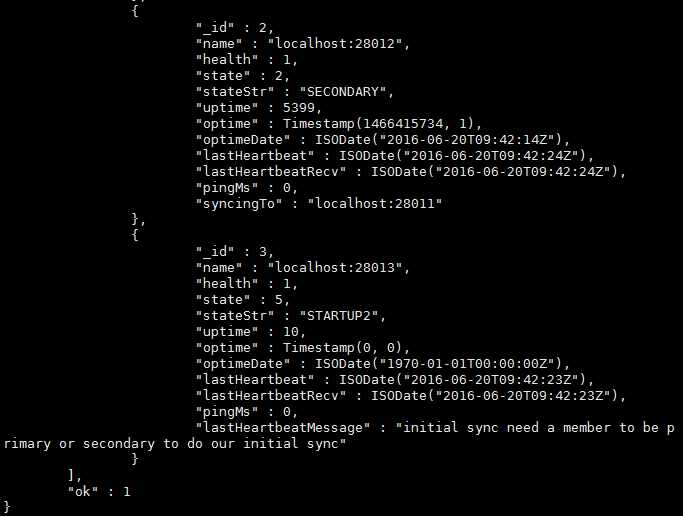
④、验证数据已经同步过来了

通过数据库快照(--fastsync)和oplog增加节点
通过oplog 直接进行增加节点操作简单且无需人工干预过多,但oplog 是capped collection,采用循环的方式进行日志处理,所以采用oplog 的方式进行增加节点,有可能导致数据的不一致,因为日志中存储的信息有可能已经刷新过了。不过没关系,我们可以通过数据库快照(--fastsync)和oplog 结合的方式来增加节点,这种方式的操作流程是,先取某一个复制集成员的物理文件来做为初始化数据,然后剩余的部分用oplog 日志来追,最终达到数据一致性.
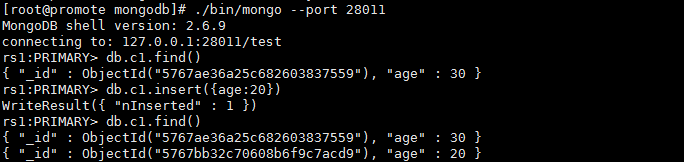
①、取某一个复制集成员的物理文件来做为初始化数据

②、在取完物理文件后,在c1集中插入一条新文档,用于最后验证此更新也同步了
③、启用28014这个端口给新的节点

④、添加28014节点
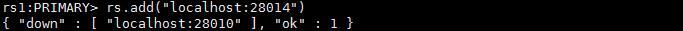
⑤、验证数据已经同步过来了

3、2 减少节点
下面将刚刚添加新节点28014 从复制集中去除掉,只需执行rs.remove 指令就可以了,具体如下:
查看复制集状态,可以看到现在只有28010、28011、28012 这三个成员,原来的28013 和28014 都成功去除了。

相关文章推荐
- 嵌入式Linux系统启动过程
- Image.open() cannot identify image file
- LINUX常用命令
- PopupWindow弹窗
- 树莓派上基于图形界面的安装程序-synaptic
- Tomcat如何检测内存泄漏
- Tomcat如何检测内存泄漏
- 安装交叉编译器后,无法执行arm-linux-gcc -v
- 自动车牌识别(ANPR)练习项目学习笔记4(基于opencv)
- Linux下修改文件创建时间(修改文件更改时间)
- Handler,Looper,Message的深入理解
- opencv在ubuntu下的安装
- linux内核部件分析之——设备驱动模型之class
- Android 系统架构
- syntax error: Bad for loop variable 解决办法
- Linux内核日志开关
- Linux操作系统的权限代码分析【转】
- Linux 指令
- Windows 7上执行Cake 报错原因是Powershell 版本问题
- ROS, the Robot Operating System, Is Growing Faster Than Ever, Celebrates 8 Years