[机器学习笔记]Note6--神经网络:表达
2016-06-18 20:31
393 查看
继续是机器学习课程的笔记,这节课会介绍神经网络的内容。
当我们希望训练一个模型来识别视觉对象,比如识别一张图片上是否是一辆汽车,一种实现方法是利用许多汽车和非汽车的图片,然后利用图片上一个个像素的值(饱和度或亮度)来作为特征。这也是因为在计算机中,一张图片其实就一个包含所有像素值的矩阵。
如果我们选择的是灰度图片,每个像素则只有一个值,而非RGB值,我们可以选择图片上两个不同位置的两个像素,然后训练一个逻辑回归算法利用这两个像素的值来判断图片上是否是汽车。
但假设我们采用的是50*50像素的小图片,并且我们将所有的像素视为特征,那么就会有2500个特征,而如果我们进一步将两两特征组合构成一个多项式模型,则会有约250022,即接近三百万个特征。普通的逻辑回归模型,不能有效地处理那么多的特征,这个时候就需要神经网络。
神经网络算法的目的是发现一个能模型人类大脑学习能力的算法。研究表明,如果我们将视觉信号传导给大脑中负责其他感觉的大脑皮层处,则这些大脑组织将能学会如何处理视觉信号。
神经网络是模型就是建立在很多神经元之上的,每个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被称为权重(weight)。
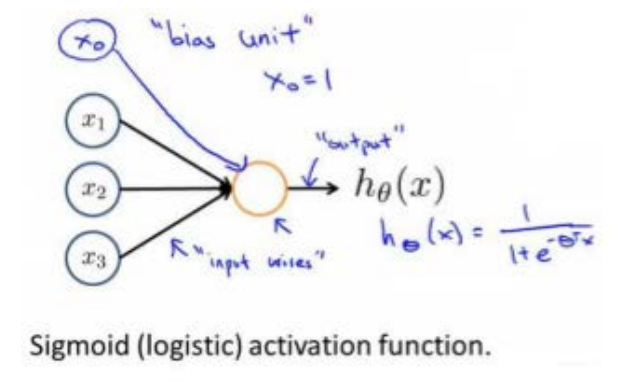
上图中输入是有4个特征,包括人工加入的x0=1,以及x1,x2,x3,其输出就是假设hθ(x)=11+e−θTx,也就是之前逻辑回归中的假设,而黑色的直线表示的就是每种特征的权重值。此外,x0也被称为偏置单元(bias unit),中间红色的圈表示的就是使用的激活函数,这里是使用S形函数,也就是g(z)=11+e−z。
由上图还可以知道,其实神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。
下图是一个3层的神经网络,第一层是输入层,最后一层是输出层,中间一层是隐藏层。我们为每一层都增加一个偏置单元。
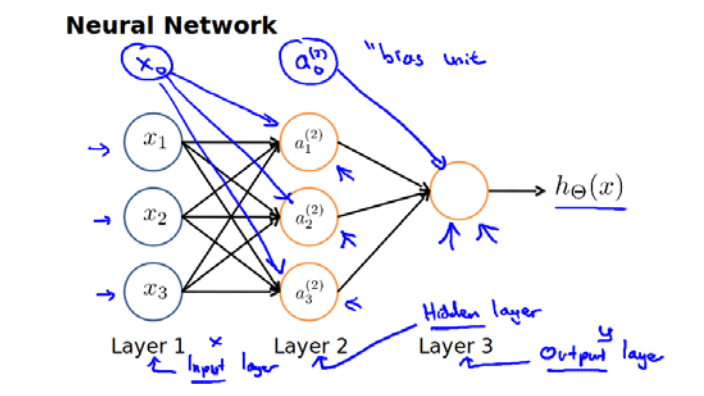
下面引入一些标记来帮助描述模型:
a(j)i 代表第j层的第i个激活单元
θ(j) 代表从第j层映射到第j+1层时的权重的矩阵,例如θ(1)代表从第一层到第二层的权重的矩阵,其尺寸为:**以第j层的激活单元数量为行数,第j+1层的激活单元数为列数的矩阵,即Sj+1∗(Sj+1)。所以如上图的神经网站中θ(1)的尺寸是3*4。
对于上图所示的模型,激活单元和输出分别表达为:
a(2)1=g(θ(1)10x0+θ(1)11x1+θ(1)12x2+θ(1)13x3)a(2)2=g(θ(1)20x0+θ(1)21x1+θ(1)22x2+θ(1)23x3)a(2)3=g(θ(1)30x0+θ(1)31x1+θ(1)32x2+θ(1)33x3)hθ(x)=a(3)1=g(θ(2)10a(2)0+θ(2)11a(2)1+θ(2)12a(2)2+θ(2)13a(2)3)
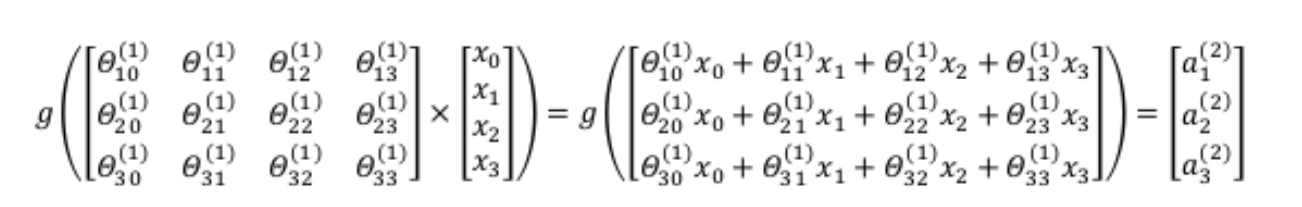
我们令z(2)=θ(1)x,则a(2)=g(z(2)),计算后添加a(2)0=1,计算输出的值:
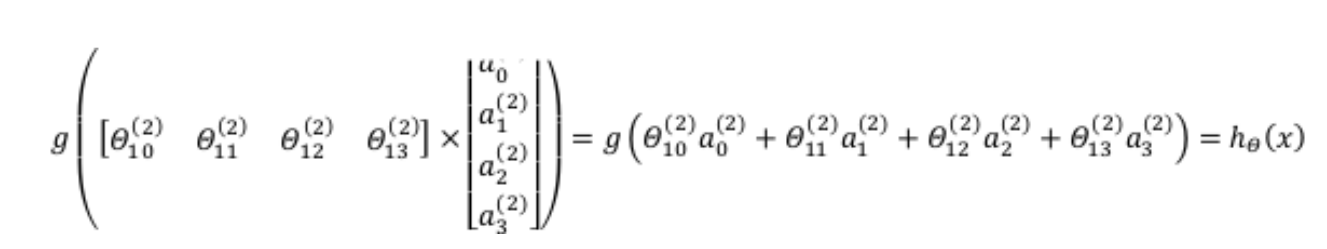
我们令z(2)=θ(1)x,则a(2)=g(z(2)),计算后添加a(2)0=1,计算输出的值:
![此处输入图片的描述][5]
令z(3)=θ(2)a(2),则hθ(x)=a(3)=g(z(3)).
前向传播是一个从输入层到隐藏层再到输出层依次计算激励,即激活函数a的过程。
下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
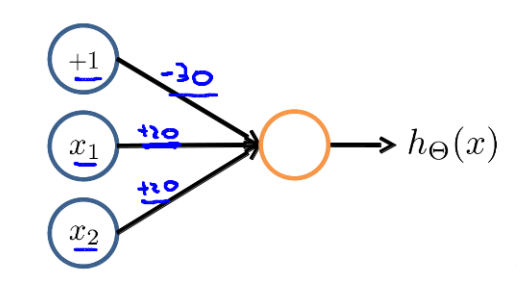
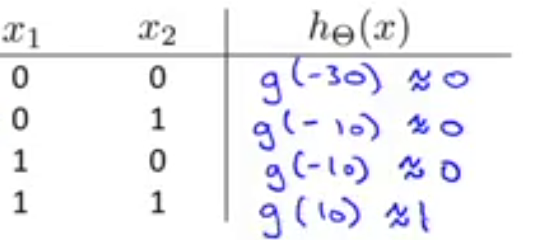
其表达式是hθ(x)=g(−30+20x1+20x2),其可能的输出如下图所示:
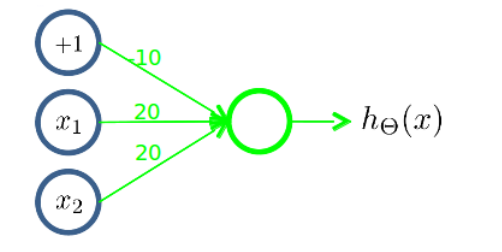
同理,下面的神经元,三个权重分别是-10,20,20,可以被视为作用等同于逻辑或(OR)
下面的神经元,两个权重分别为-10,20,可以视作逻辑非(NOT)
上面是一些基本的逻辑运算符,我们还可以用神经元来组成更为复杂的神经网络以实现更复杂的运算。例如实现XNOR,即异或,即只有输入的两个值都相同,均为1或0时,输出才是1,也就是XNOR=(x1 AND x2)OR ((NOT x1) AND (NOT x2))
其实现如下所示:
首先分别列出三个部分的神经元的实现,
然后组合起来就得到最终的结果:
我们就实现了一个XNOR运算符功能的神经网络。
下面是该神经网络的可能结构示例:
那么神经网络算法的输出结果是下列四种可能情形之一:
⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0100⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0010⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0001⎤⎦⎥⎥⎥,
非线性假设
在之前的课程中,我们看到使用非线性的多项式能够帮助我们建立更好的分类模型。假设我们有非常多的特征,例如100个变量,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合(x1x2+x1x3+x1x4+…+x2x3+x2x4+…+x99x100),那么我们也会有近5000个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。当我们希望训练一个模型来识别视觉对象,比如识别一张图片上是否是一辆汽车,一种实现方法是利用许多汽车和非汽车的图片,然后利用图片上一个个像素的值(饱和度或亮度)来作为特征。这也是因为在计算机中,一张图片其实就一个包含所有像素值的矩阵。
如果我们选择的是灰度图片,每个像素则只有一个值,而非RGB值,我们可以选择图片上两个不同位置的两个像素,然后训练一个逻辑回归算法利用这两个像素的值来判断图片上是否是汽车。
但假设我们采用的是50*50像素的小图片,并且我们将所有的像素视为特征,那么就会有2500个特征,而如果我们进一步将两两特征组合构成一个多项式模型,则会有约250022,即接近三百万个特征。普通的逻辑回归模型,不能有效地处理那么多的特征,这个时候就需要神经网络。
神经网络介绍
神经网络算法源自于对大脑的模仿。神经网络算法在八十到九十年代被广为使用过,但是之后由于其计算量大的原因逐渐减少了使用,而最近,从2006年开始,到后来2012年ImageNet比赛中CNN取得非常大的提升效果,现在神经网络变得非常流行,准确地说是深度神经网络。原因也是因为神经网络是非常依赖计算能力的,而要实现深度神经网络,也就是神经网络的层数更多,需要的计算量更大,但是现在随着计算机硬件的提高,还有就是数据量的增加,使得神经网络又开始流行起来了。神经网络算法的目的是发现一个能模型人类大脑学习能力的算法。研究表明,如果我们将视觉信号传导给大脑中负责其他感觉的大脑皮层处,则这些大脑组织将能学会如何处理视觉信号。
模型表达
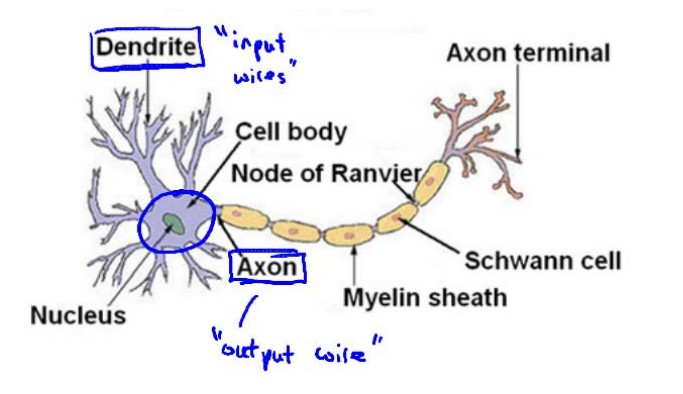
为了构建神经网络模型,我们会参考大脑中的神经网络。每个神经元可以被认为是一个处理单元/神经核(processing unit/Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络,如下图所示:神经网络是模型就是建立在很多神经元之上的,每个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被称为权重(weight)。
上图中输入是有4个特征,包括人工加入的x0=1,以及x1,x2,x3,其输出就是假设hθ(x)=11+e−θTx,也就是之前逻辑回归中的假设,而黑色的直线表示的就是每种特征的权重值。此外,x0也被称为偏置单元(bias unit),中间红色的圈表示的就是使用的激活函数,这里是使用S形函数,也就是g(z)=11+e−z。
由上图还可以知道,其实神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。
下图是一个3层的神经网络,第一层是输入层,最后一层是输出层,中间一层是隐藏层。我们为每一层都增加一个偏置单元。
下面引入一些标记来帮助描述模型:
a(j)i 代表第j层的第i个激活单元
θ(j) 代表从第j层映射到第j+1层时的权重的矩阵,例如θ(1)代表从第一层到第二层的权重的矩阵,其尺寸为:**以第j层的激活单元数量为行数,第j+1层的激活单元数为列数的矩阵,即Sj+1∗(Sj+1)。所以如上图的神经网站中θ(1)的尺寸是3*4。
对于上图所示的模型,激活单元和输出分别表达为:
a(2)1=g(θ(1)10x0+θ(1)11x1+θ(1)12x2+θ(1)13x3)a(2)2=g(θ(1)20x0+θ(1)21x1+θ(1)22x2+θ(1)23x3)a(2)3=g(θ(1)30x0+θ(1)31x1+θ(1)32x2+θ(1)33x3)hθ(x)=a(3)1=g(θ(2)10a(2)0+θ(2)11a(2)1+θ(2)12a(2)2+θ(2)13a(2)3)
正向传播
相对于使用循环来编码,利用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值:我们令z(2)=θ(1)x,则a(2)=g(z(2)),计算后添加a(2)0=1,计算输出的值:
我们令z(2)=θ(1)x,则a(2)=g(z(2)),计算后添加a(2)0=1,计算输出的值:
![此处输入图片的描述][5]
令z(3)=θ(2)a(2),则hθ(x)=a(3)=g(z(3)).
前向传播是一个从输入层到隐藏层再到输出层依次计算激励,即激活函数a的过程。
对神经网络的理解
本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征x1,x2,…,xn,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。而在神经网络中,原始特征只是输入层,在上面三层的神经网络例子中,第三层也就是输出层所做出的预测是利用第二层的特征,而非输入层的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。神经网络示例:二元逻辑运算符
当输入特征是布尔值(0或1)时,我们可以用一个单一的激活层作为二元逻辑运算符,为了表示不同的运算符,我们只需要选择不同的权重即可。下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
其表达式是hθ(x)=g(−30+20x1+20x2),其可能的输出如下图所示:
同理,下面的神经元,三个权重分别是-10,20,20,可以被视为作用等同于逻辑或(OR)
下面的神经元,两个权重分别为-10,20,可以视作逻辑非(NOT)
上面是一些基本的逻辑运算符,我们还可以用神经元来组成更为复杂的神经网络以实现更复杂的运算。例如实现XNOR,即异或,即只有输入的两个值都相同,均为1或0时,输出才是1,也就是XNOR=(x1 AND x2)OR ((NOT x1) AND (NOT x2))
其实现如下所示:
首先分别列出三个部分的神经元的实现,
然后组合起来就得到最终的结果:
我们就实现了一个XNOR运算符功能的神经网络。
多类分类
假如我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,那么在输出层我们应该有4个值,例如,第一个值为1或0用于预测是否是行人,第二个值用来判断是否为汽车。下面是该神经网络的可能结构示例:
那么神经网络算法的输出结果是下列四种可能情形之一:
⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0100⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0010⎤⎦⎥⎥⎥,⎡⎣⎢⎢⎢0001⎤⎦⎥⎥⎥,
小结
本节课是介绍了神经网络的基础知识,包括产生的背景,模型表达以及正向传播的内容。暂时还没有涉及到更深层次的知识。

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- bp神经网络及matlab实现
- 反向传播(Backpropagation)算法的数学原理
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 基于神经网络的预测模型
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐