Deep Residual Learning for Image Recognition
2016-06-18 19:57
411 查看
传说中的ResNet, 已获CVPR best paper, Kaiming He 已跳FB.
更深的网络面临另一困境:with the network depth increasing, accuracy gets saturated and then degrades rapidly.而且这种情况并不是因为过拟合导致的,原因在于,对于当前的网络,增加更多的层,会导致训练误差更大. 如下图所示
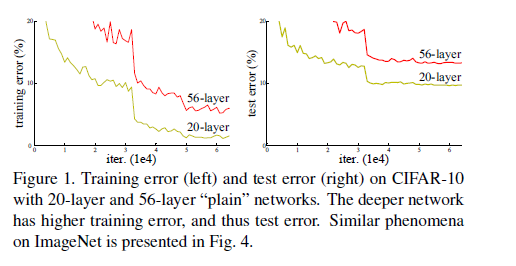
对于VGG构建deeper model的经验:新加的layer应该是identity mapping, 高层的layer是从浅层的layer copy得到初始化值,这种模型结构引导的趋势应当是深度网络应该比它自身的shallower counterpart有更小的训练误差,或者说,假如我们新增的layer权值全部为0的话,就应该和原始的网络相同,即这种方法构建出的网络解空间应当包含原先的浅层网络的解,但是实验中却出现了如上图那样的degradation problem.
So,文章要做的事情就是解决这个问题,并且
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping
by a stack of nonlinear layers.
将原先的mapping function由F(x)变为F(x)+ x, 引入这种方式后,并不会增加更多的参数,可以按照原先的优化方法进行训练,在这种情况下:
1.if identity were optimal, easy to set weights as 0;
2.if optimal mapping is closer to identity, easier to find small fluctuations.
实验证明:
1)这种方法更容易优化,training error更小
2)通过增加深度,能得到accuracy gain, 即能够做到网络越深,准确率越高. 不会出现以上的的degradation problem. 这个碉堡.

这部分没懂.

The network ends with a global average pooling layer and a 1000-way fc layer with softmax. 和VGG比 由于少了最后两层4096的全连接,总参数少了很多, 34-layer的参数数量大概是VGG-19的18%.
3*3的卷积核,padding=1,卷积过后,feature map 大小不变,可以直接使用identity mapping, 但是每经过一个pooling层,尺寸减半(为什么是dimension increase ?),这时候就需要match dimension. 通常有两种方法: (这部分操作待补充)
1. 用0补足
2.使用F(x)+wx



Abstract :
1.depth的又一次延伸,but still having lower complexity.Introduction:
imagenet 最近的几次比赛来看,包括VGG,Inception均是越来越深的网络结构,driven by this, Is learning better networks as easy as stacking more layers? 以前深度网络主要的的问题在于训练时不收敛,梯度消失或爆炸问题,有了各种初始化方法(xavier, msra)和BN以后,这种情况得到了比较好的解决。更深的网络面临另一困境:with the network depth increasing, accuracy gets saturated and then degrades rapidly.而且这种情况并不是因为过拟合导致的,原因在于,对于当前的网络,增加更多的层,会导致训练误差更大. 如下图所示
对于VGG构建deeper model的经验:新加的layer应该是identity mapping, 高层的layer是从浅层的layer copy得到初始化值,这种模型结构引导的趋势应当是深度网络应该比它自身的shallower counterpart有更小的训练误差,或者说,假如我们新增的layer权值全部为0的话,就应该和原始的网络相同,即这种方法构建出的网络解空间应当包含原先的浅层网络的解,但是实验中却出现了如上图那样的degradation problem.
So,文章要做的事情就是解决这个问题,并且
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping
by a stack of nonlinear layers.
将原先的mapping function由F(x)变为F(x)+ x, 引入这种方式后,并不会增加更多的参数,可以按照原先的优化方法进行训练,在这种情况下:
1.if identity were optimal, easy to set weights as 0;
2.if optimal mapping is closer to identity, easier to find small fluctuations.
实验证明:
1)这种方法更容易优化,training error更小
2)通过增加深度,能得到accuracy gain, 即能够做到网络越深,准确率越高. 不会出现以上的的degradation problem. 这个碉堡.
Related Work
Residual Representations and shortcut-connections这部分没懂.
Network Design
The network ends with a global average pooling layer and a 1000-way fc layer with softmax. 和VGG比 由于少了最后两层4096的全连接,总参数少了很多, 34-layer的参数数量大概是VGG-19的18%.
3*3的卷积核,padding=1,卷积过后,feature map 大小不变,可以直接使用identity mapping, 但是每经过一个pooling层,尺寸减半(为什么是dimension increase ?),这时候就需要match dimension. 通常有两种方法: (这部分操作待补充)
1. 用0补足
2.使用F(x)+wx
Training:
Experimental Results:
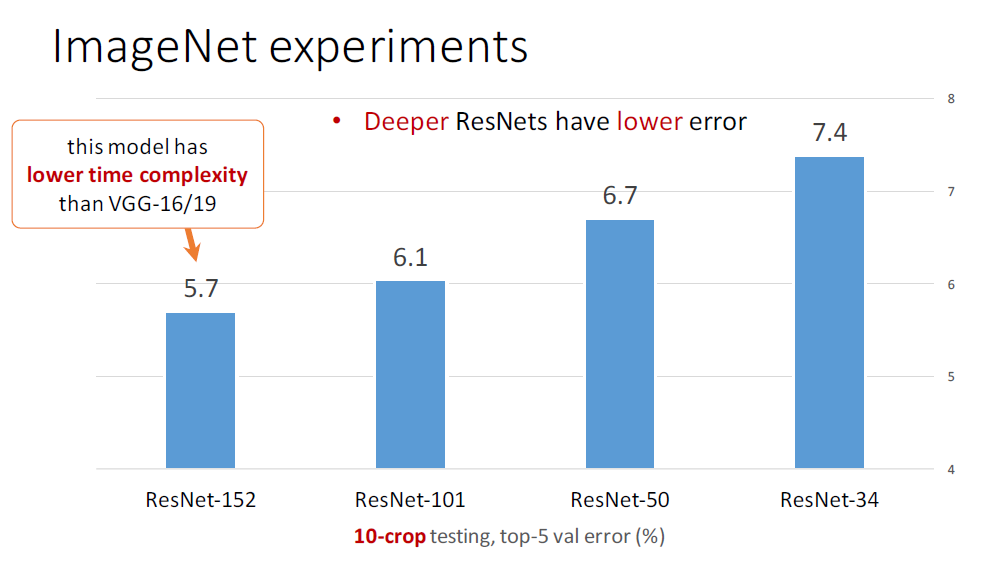
deeper + thinner的威力
Discuss

相关文章推荐
- 软件附加题简答
- maven笔记
- 上海科目三要点
- SwipeRefreshLayout 与 CoordinatorLayout 嵌套刷新
- Exchanger示例
- spring 笔记
- iOS代码规范文档
- Android 5.0中设置全屏无标题
- 对软件工程的看法总结
- 14 指针及其运算
- macbook win10下声音键和触摸板右键键盘灯无法使用解决方法
- 如何在5.0上实现button的Ripple(水波效果)
- iOS项目架构文档
- echarts
- 弹性布局
- 嵌入式 Linux C语言(七)——结构体
- STL-power算法实现
- 自定义Builder的构造
- Unreal Engine 4 —— Ghost Mesh Plugin的开发日志
- 质数因子