python大规模数据处理技巧之一:数据常用操作
2016-06-16 09:14
519 查看
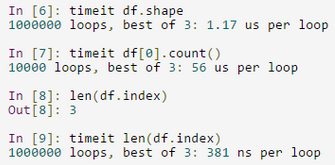
面对读取上G的数据,python不能像做简单代码验证那样随意,必须考虑到相应的代码的实现形式将对效率的影响。如下所示,对pandas对象的行计数实现方式不同,运行的效率差别非常大。虽然时间看起来都微不足道,但一旦运行次数达到百万级别时,其运行时间就根本不可能忽略不计了:
故接下来的几个文章将会整理下渣渣在关于在大规模数据实践上遇到的一些问题,文章中总结的技巧基本是基于pandas,有错误之处望指正。
注意事项:open(file.csv)与pandas包的pd.read_csv(file.csv ): python32位的话会限制内存,提示太大的数据导致内存错误。解决方法是装python64位。如果嫌python各种包安装过程麻烦,可以直接安装Anaconda2 64位版本
简易使用方法:
读取需要的列:
chunker对象指向了多个分块对象,但并没有将实际数据先读入,而是在提取数据时才将数据提取进来。数据的处理和清洗经常使用分块的方式处理,这能大大降低内存的使用量,但相比会更耗时一些
分块读取chunk中的每一行:
分块写出到磁盘:
对于第一个分块使用pandas包的存储IO:
保留header信息,‘w’模式写入
接下的分块写入
去除header信息,‘a’模式写入,即不删除原文档,接着原文档后继续写
少量的数据写出:
少量的数据用pickle(cPickle更快)输出和读取,非常方便 ,下面分别是写出和读入
写出:
读入:
效率高的方法:直接将外部数据读入进来
问题分析:
纵向的合并使用list并不好,因为需要去拆解list的每一个行元素,并用extend去拓展每一行的纵向元素
最好使用dataframe中的concat函数:c = pd.concat([a, b], axis = 1),当axis=0时表示合并行(以行为轴)
类似数据库的表合并:join(待完整)
简单纵向合并数据集:
纵向合并数据集可以考虑一下几种方法:
读取数据为list格式,使用append函数逐行读取
将数据集转换为pandas中的dataframe格式,使用dataframe的merge与concat方法
方法:
方法一:使用dataframe读入,使用concat把每行并起来
方法二:先使用list读入并起来,最后转换成dataframe
方法三:先使用list读入并起来大块的list,每块list转换成dataframe后用concat合并起来
比较:方法一由于concat的静态性,每次要重新分配资源,故跑起来很慢; 方法二与三:会快很多,但具体没有测试,以下是使用方法三的代码:
<未完待续>
故接下来的几个文章将会整理下渣渣在关于在大规模数据实践上遇到的一些问题,文章中总结的技巧基本是基于pandas,有错误之处望指正。
1、外部csv文件读写
大数据量csv读入到内存
分析思路:数据量非常大时,比如一份银行一个月的流水账单,可能有高达几千万的record。对于一般性能的计算机,有或者是读入到特殊的数据结构中,内存的存储可能就非常吃力了。考虑到我们使用数据的实际情况,并不需要将所有的数据提取出内存。当然读入数据库是件比较明智的做法。若不用数据库呢?可将大文件拆分成小块按块读入后,这样可减少内存的存储与计算资源注意事项:open(file.csv)与pandas包的pd.read_csv(file.csv ): python32位的话会限制内存,提示太大的数据导致内存错误。解决方法是装python64位。如果嫌python各种包安装过程麻烦,可以直接安装Anaconda2 64位版本
简易使用方法:
chunker = pd.read_csv(PATH_LOAD, chunksize = CHUNK_SIZE)
读取需要的列:
columns = ("date_time", "user_id")
chunks_train = pd.read_csv(filename, usecols = columns, chunksize = 100000)chunker对象指向了多个分块对象,但并没有将实际数据先读入,而是在提取数据时才将数据提取进来。数据的处理和清洗经常使用分块的方式处理,这能大大降低内存的使用量,但相比会更耗时一些
分块读取chunk中的每一行:
for rawPiece in chunker_rawData: current_chunk_size = len(rawPiece.index) #rawPiece 是dataframe for i in range(current_chunk_size ): timeFlag = timeShape(rawPiece.ix[i]) #获取第i行的数据
将数据存到硬盘
直接写出到磁盘:data.to_csv(path_save, index = False, mode = 'w')`
分块写出到磁盘:
对于第一个分块使用pandas包的存储IO:
保留header信息,‘w’模式写入
data.to_csv(path_save, index = False, mode = 'w')
接下的分块写入
去除header信息,‘a’模式写入,即不删除原文档,接着原文档后继续写
data.to_csv(path_save, index = False, header = False, mode = a')
少量的数据写出:
少量的数据用pickle(cPickle更快)输出和读取,非常方便 ,下面分别是写出和读入
写出:
import cPickle as pickle def save_trainingSet(fileLoc, X, y): pack = [X, y] with open(fileLoc, 'w') as f: pickle.dump(pack, f)
读入:
import cPickle as pickle def read_trainingSet(fileLoc): with open(fileLoc, 'r') as f: pack = pickle.load(f) return pack[0], pack[1]
高效读取外部csv到python内部的list数据结构
效率低下的方法:使用pd读入需要从pd转换到python本身的数据结构,多此一举userList = [] content = pd.read_csv(filename) for i in range(len(content)): line = content.ix[i]['id'] userList.append(line)
效率高的方法:直接将外部数据读入进来
userList = []
f = open(filename)
content = f.readlines()
for line in content:
line = line.replace('\n', '').split(',')
userList.append(line)2、数据分析时常用数据结构之间的转化
数据集的横向与纵向合并
简单地横向合并数据集:问题分析:
纵向的合并使用list并不好,因为需要去拆解list的每一个行元素,并用extend去拓展每一行的纵向元素
最好使用dataframe中的concat函数:c = pd.concat([a, b], axis = 1),当axis=0时表示合并行(以行为轴)
inx1 = DataFrame(np.random.randn(nSample_neg), columns = ['randVal']) inx2 = DataFrame(range(nSample_neg), columns = ['inxVal']) inx = pd.concat([inx1, inx2], axis = 1)
类似数据库的表合并:join(待完整)
ret = ret.join(dest_small, on="srch_destination_id", how='left', rsuffix="dest")
简单纵向合并数据集:
纵向合并数据集可以考虑一下几种方法:
读取数据为list格式,使用append函数逐行读取
将数据集转换为pandas中的dataframe格式,使用dataframe的merge与concat方法
方法:
方法一:使用dataframe读入,使用concat把每行并起来
方法二:先使用list读入并起来,最后转换成dataframe
方法三:先使用list读入并起来大块的list,每块list转换成dataframe后用concat合并起来
比较:方法一由于concat的静态性,每次要重新分配资源,故跑起来很慢; 方法二与三:会快很多,但具体没有测试,以下是使用方法三的代码:
data = [] cleanedPiece = [] for i in range(CHUNK_SIZE): line = rawPiece.ix[i] uid = [line['user_id'], line['item_id'], line['behavior_type'], timeFlag] cleanedPiece.append(uid) cleanedPiece = DataFrame(cleanedPiece, columns = columns) data = pd.concat([data, cleanedPiece], axis = 0)
<未完待续>

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- 我是运营,我没有假期
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例