Python2 抓取百度贴吧图片
2016-06-13 16:01
309 查看
我这里抓取的百度贴吧的地址是http://tieba.baidu.com/p/2460150866?pn=1。以下是源码,使用的是python2。
下面是抓取的结果
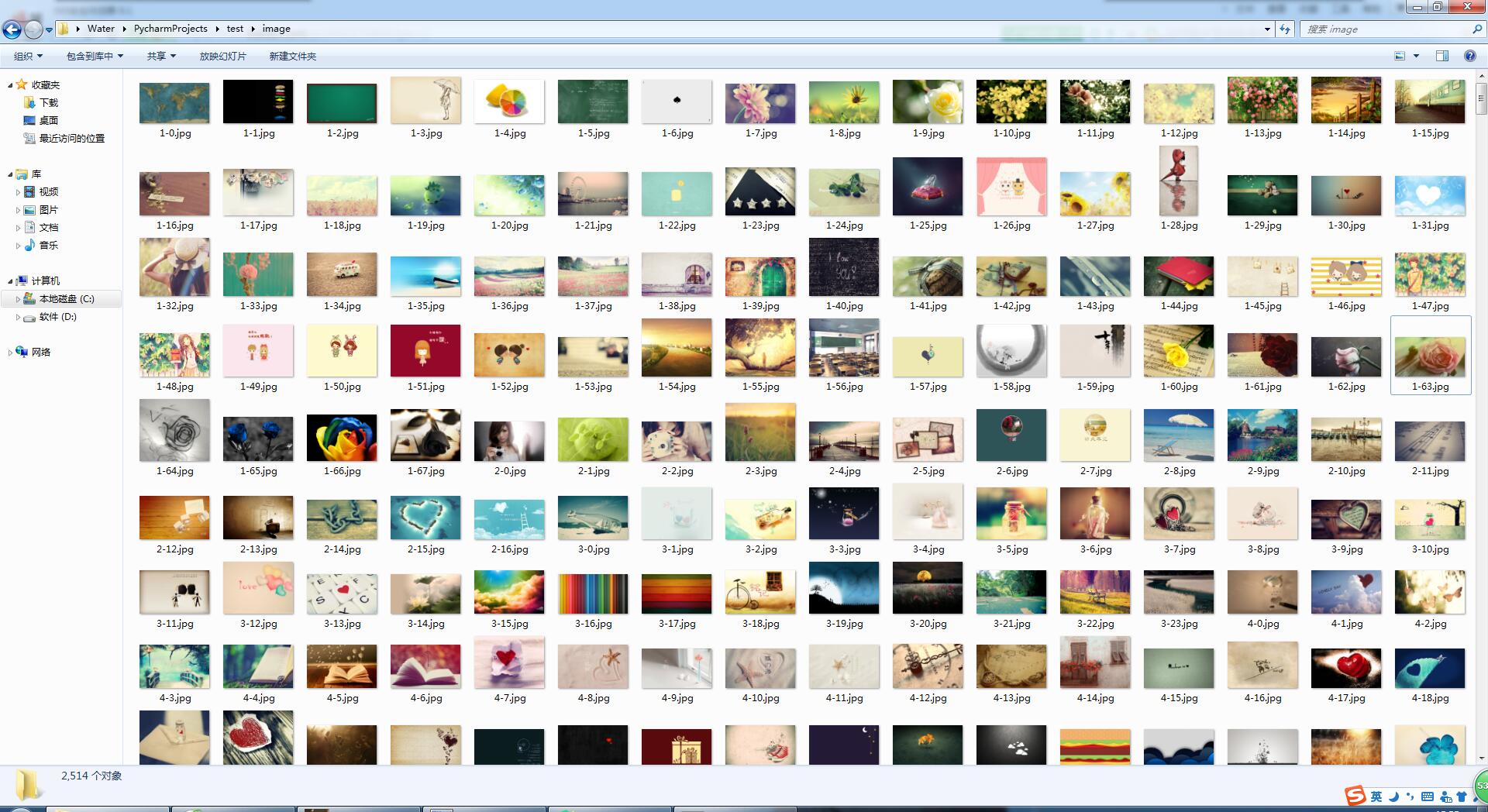
import re #导入正则模块
import urllib #导入url库模块
#抓取页面的源码
def getHtml(url):
page = urllib.urlopen(url) #打开指定的URL
html = page.read() #读取URL的内容并保存
return html #函数返回读取的内容
#下载源码中指定的图片
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)
x = 0
for imgurl in imglist:
print(imgurl)
#下载图片到指定的目录,并且重新命名
urllib.urlretrieve(imgurl,r'C:\Users\Water\PycharmProjects\test\image\%s-%s.jpg' % (i,x))
x = x + 1
#循环抓取所有的页面
i = 1
while i < 74: #贴吧共有74页评论
html = getHtml("http://tieba.baidu.com/p/2460150866?pn=" + str(i))
getImg(html)
i+=1
print(i)下面是抓取的结果

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法