Python3学习笔记05-字典、文件输入输出、模块、函数参数传递
2016-06-09 00:00
976 查看
前边基础教程介绍了基本概念,特别是对象和类。
下面对基础教程的进一步拓展,说明Python的细节。希望在进阶教程之后,你对Python有一个更全面的认识。
##一、词典
之前我们说了,列表是Python里的一个类。一个特定的表,比如说nl = [1,3,8],就是这个类的一个对象。我们可以调用这个对象的一些方法,比如 nl.append(15)。
我们要介绍一个新的类,词典 (dictionary)。与列表相似,词典也可以储存多个元素。这种储存多个元素的对象称为容器(container)。
###1、基本概念
常见的创建词典的方法:
词典和表类似的地方,是包含有多个元素,每个元素以逗号分隔。但词典的元素包含有两部分,键和值,常见的是以字符串来表示键,也可以使用数字或者真值来表示键(不可变的对象可以作为键)。值可以是任意对象。键和值两者一一对应。
比如上面的例子中,‘tom’对应11,'sam对应57,'lily'对应100
与表不同的是,词典的元素没有顺序。你不能通过下标引用元素。词典是通过键来引用。
构建一个新的空的词典:
在词典中增添一个新元素的方法:
这里,我们引用一个新的键,并赋予它对应的值。
###2、词典元素的循环调用
在循环中,dict的每个键,被提取出来,赋予给key变量。
通过print的结果,我们可以再次确认,dic中的元素是没有顺序的。
###3、词典的常用方法
另外有一个很常用的用法:
del是Python中保留的关键字,用于删除对象。
与表类似,你可以用**len()**查询词典中的元素总数。
##二、文本文件的输入输出
Python具有基本的文本文件读写功能。Python的标准库提供有更丰富的读写功能。
文本文件的读写主要通过open()[b]所构建的文件对象[/b]来实现。
###1、创建文件对象
我们打开一个文件,并使用一个对象来表示该文件:
最常用的模式有:
r 打开只读文件,该文件必须存在。
r+ 打开可读写的文件,该文件必须存在。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
比如:
###2、文件对象的方法
读取:
写入:
关闭文件:
从上图我们可以看出,用"r"打开不存在的文件,则会报错。打开文件进行权限赋予,如果赋予只写文件则,打开后文件后不可读。打开,读取,写入,关闭四个基本操作文件的方法。
##三、模块
我们之前看到了函数和对象。从本质上来说,它们都是为了更好的组织已经有的程序,以方便重复利用。
**模块(module)**也是为了同样的目的。在Python中,一个.py文件就构成一个模块。通过模块,你可以调用其它文件中的程序。
###1、引入模块
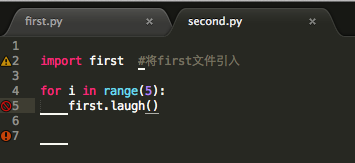
我们先写一个first.py文件,内容如下:
再写一个second.py,并引入first中的程序:
在second.py中,我们使用了first.py中定义的laugh()函数。
引入模块后,可以通过 模块.对象 的方式来调用引入模块中的某个对象。上面例子中,first为引入的模块,laugh()是我们所引入的对象。
以上代码执行后会报错:
SyntaxError: Non-ASCII character '\xe5' in file
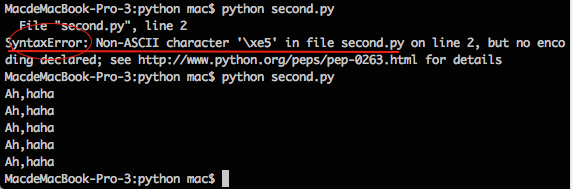
原因:Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他的语言,比如小日本的日语……),此时即使你把自己编写的Python源文件以UTF-8格式保存了;但实际上,这依然是不行的。
解决方法:在源码的第一行添加以下语句:
或者
(注:此语句一定要添加在源代码的第一行)
Python中还有其它的引入方式:
这些引用方式,可以方便后面的程序书写。
###2、搜索路径
Python会在以下路径中搜索它想要寻找的模块:
程序所在的文件夹
操作系统环境变量PYTHONPATH所包含的路径
标准库的安装路径
如果你有自定义的模块,或者下载的模块,可以根据情况放在相应的路径,以便Python可以找到。
###3、模块包
可以将功能相似的模块放在同一个文件夹(比如说this_dir)中,构成一个模块包。通过
引入this_dir文件夹中的module模块。
该文件夹中必须包含一个** init.py** 的文件,提醒Python,该文件夹为一个模块包。init.py 可以是一个空文件。
##四、函数的参数传递
我们已经接触过函数(function)的参数(arguments)传递。当时我们根据位置,传递对应的参数。我们将接触更多的参数传递方式。
回忆一下位置传递:
在调用 f 时,1,2,3根据位置分别传递给了a,b,c。
###1、关键字传递
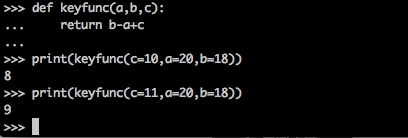
有些情况下,用位置传递会感觉比较死板。关键字(keyword)传递是根据每个参数的名字传递参数。关键字并不用遵守位置的对应关系。依然沿用上面f的定义,更改调用方式:
关键字传递可以和位置传递混用。但位置参数要出现在关键字参数之前:
示例:
###2、参数默认值
在定义函数的时候,使用形如a=19的方式,可以给参数赋予默认值(default)。如果该参数最终没有被传递值,将使用该默认值。
在第一次调用函数f时, 我们并没有足够的值,c没有被赋值,c将使用默认值10.
第二次调用函数的时候,c被赋值为1,不再使用默认值。
###3、包裹传递
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)[b]位置参数,或者包裹关键字参数[/b],来进行参数传递,会非常有用。
下面是包裹位置传递的例子:
两次调用,尽管参数个数不同,都基于同一个func定义。在func的参数表中,所有的参数被name收集,根据位置合并成一个元组(tuple),这就是包裹位置传递。
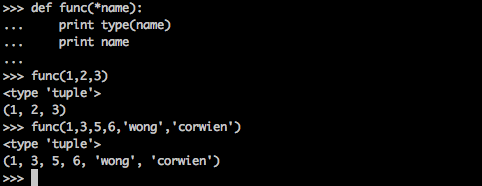
为了提醒Python参数,name是包裹位置传递所用的元组名,在定义func时,在name前加*号。
下面是包裹关键字传递的例子:
与上面一个例子类似,dict是一个字典,收集所有的关键字,传递给函数func。为了提醒Python,参数dict是包裹关键字传递所用的字典,**在dict前加 ** **。
包裹传递的关键在于定义函数时,在相应元组或字典前加 * 或 * * 。
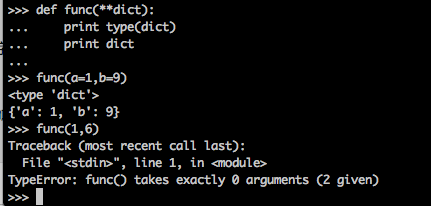
注意:字典传递的参数必须传递参数名,参数值形式,如果直接传入参数值则会报错。
###4、解包裹
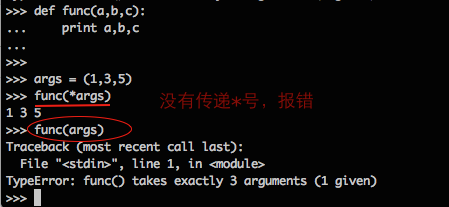
* 和 **,也可以在调用的时候使用,即解包裹(unpacking), 下面为例:
在这个例子中,所谓的解包裹,就是在传递tuple时,让tuple的每一个元素对应一个位置参数。在调用func时使用 * ,是为了提醒Python:我想要把args拆成分散的三个元素,分别传递给a,b,c。(设想一下在调用func时,args前面没有 * 会是什么后果?)
相应的,也存在对词典的解包裹,使用相同的func定义,然后:
在传递词典dict时,让词典的每个键值对作为一个关键字传递给func。
###5、混合
在定义或者调用参数时,参数的几种传递方式可以混合。但在过程中要小心前后顺序。基本原则是:先位置,再关键字,再包裹位置,再包裹关键字,并且根据上面所说的原理细细分辨。
注意:请注意定义时和调用时的区分。包裹和解包裹并不是相反操作,是两个相对独立的过程。
注:本Python学习笔记是按照Vamei的博客教程来学习的,如有兴趣可以参考Vamei Python快速开发博文
下面对基础教程的进一步拓展,说明Python的细节。希望在进阶教程之后,你对Python有一个更全面的认识。
##一、词典
之前我们说了,列表是Python里的一个类。一个特定的表,比如说nl = [1,3,8],就是这个类的一个对象。我们可以调用这个对象的一些方法,比如 nl.append(15)。
我们要介绍一个新的类,词典 (dictionary)。与列表相似,词典也可以储存多个元素。这种储存多个元素的对象称为容器(container)。
###1、基本概念
常见的创建词典的方法:
>>>dic = {'tom':11, 'sam':57,'lily':100}
>>>print type(dic)词典和表类似的地方,是包含有多个元素,每个元素以逗号分隔。但词典的元素包含有两部分,键和值,常见的是以字符串来表示键,也可以使用数字或者真值来表示键(不可变的对象可以作为键)。值可以是任意对象。键和值两者一一对应。
比如上面的例子中,‘tom’对应11,'sam对应57,'lily'对应100
与表不同的是,词典的元素没有顺序。你不能通过下标引用元素。词典是通过键来引用。
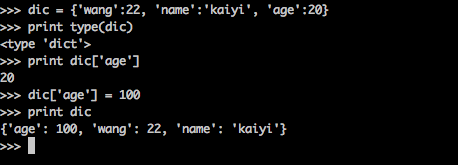
>>>print dic['tom'] >>>dic['tom'] = 30 >>>print dic
构建一个新的空的词典:
>>>dic = {}
>>>print dic在词典中增添一个新元素的方法:
>>>dic['lilei'] = 99 >>>print dic
这里,我们引用一个新的键,并赋予它对应的值。
###2、词典元素的循环调用
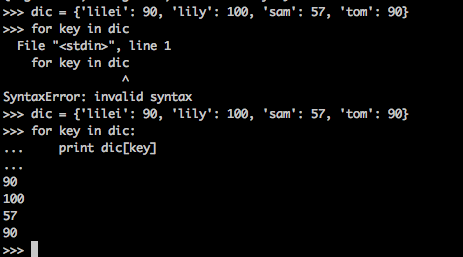
dic = {'lilei': 90, 'lily': 100, 'sam': 57, 'tom': 90}
for key in dic:
print dic[key]在循环中,dict的每个键,被提取出来,赋予给key变量。
通过print的结果,我们可以再次确认,dic中的元素是没有顺序的。
###3、词典的常用方法
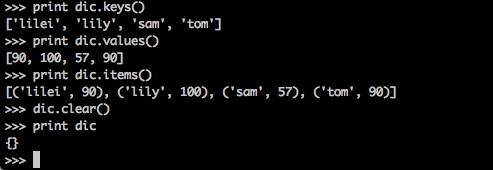
>>>print dic.keys() # 返回dic所有的键
>>>print dic.values() # 返回dic所有的值
>>>print dic.items() # 返回dic所有的元素(键值对)
>>>dic.clear() # 清空dic,dict变为{}另外有一个很常用的用法:
>>>del dic['tom'] # 删除 dic 的‘tom’元素
del是Python中保留的关键字,用于删除对象。
与表类似,你可以用**len()**查询词典中的元素总数。
>>>print len(dic)
##二、文本文件的输入输出
Python具有基本的文本文件读写功能。Python的标准库提供有更丰富的读写功能。
文本文件的读写主要通过open()[b]所构建的文件对象[/b]来实现。
###1、创建文件对象
我们打开一个文件,并使用一个对象来表示该文件:
对象名 = open(文件名,模式)
最常用的模式有:
r 打开只读文件,该文件必须存在。
r+ 打开可读写的文件,该文件必须存在。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
比如:
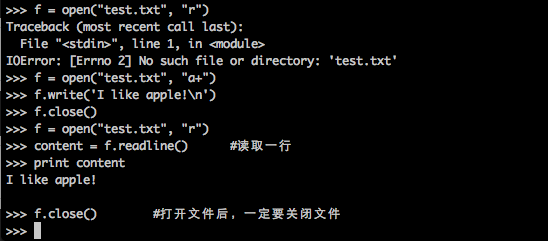
>>>f = open("test.txt","r")###2、文件对象的方法
读取:
content = f.read(N) # 读取N bytes的数据 content = f.readline() # 读取一行 content = f.readlines() # 读取所有行,储存在列表中,每个元素是一行。
写入:
f.write('I like apple!\n') # 将'I like apple'写入文件并换行关闭文件:
f.close() # 不要忘记关闭文件
从上图我们可以看出,用"r"打开不存在的文件,则会报错。打开文件进行权限赋予,如果赋予只写文件则,打开后文件后不可读。打开,读取,写入,关闭四个基本操作文件的方法。
##三、模块
我们之前看到了函数和对象。从本质上来说,它们都是为了更好的组织已经有的程序,以方便重复利用。
**模块(module)**也是为了同样的目的。在Python中,一个.py文件就构成一个模块。通过模块,你可以调用其它文件中的程序。
###1、引入模块
我们先写一个first.py文件,内容如下:
def laugh(): print 'HaHaHaHa'
再写一个second.py,并引入first中的程序:
import first #将first文件引入 for i in range(10): first.laugh()
在second.py中,我们使用了first.py中定义的laugh()函数。
引入模块后,可以通过 模块.对象 的方式来调用引入模块中的某个对象。上面例子中,first为引入的模块,laugh()是我们所引入的对象。
以上代码执行后会报错:
SyntaxError: Non-ASCII character '\xe5' in file
原因:Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他的语言,比如小日本的日语……),此时即使你把自己编写的Python源文件以UTF-8格式保存了;但实际上,这依然是不行的。
解决方法:在源码的第一行添加以下语句:
# -*- coding: UTF-8 -*-
或者
#coding=utf-8
(注:此语句一定要添加在源代码的第一行)
#coding=utf-8import first #将first文件引入
for i in range(5):
first.laugh()
Python中还有其它的引入方式:
import a as b # 引入模块a,并将模块a重命名为b from a import function1 # 从模块a中引入function1对象。调用a中对象时,我们不用再说明模块,即直接使用function1,而不是a.function1。 from a import * # 从模块a中引入所有对象。调用a中对象时,我们不用再说明模块,即直接使用对象,而不是a.对象。
这些引用方式,可以方便后面的程序书写。
###2、搜索路径
Python会在以下路径中搜索它想要寻找的模块:
程序所在的文件夹
操作系统环境变量PYTHONPATH所包含的路径
标准库的安装路径
如果你有自定义的模块,或者下载的模块,可以根据情况放在相应的路径,以便Python可以找到。
###3、模块包
可以将功能相似的模块放在同一个文件夹(比如说this_dir)中,构成一个模块包。通过
import this_dir.module
引入this_dir文件夹中的module模块。
该文件夹中必须包含一个** init.py** 的文件,提醒Python,该文件夹为一个模块包。init.py 可以是一个空文件。
##四、函数的参数传递
我们已经接触过函数(function)的参数(arguments)传递。当时我们根据位置,传递对应的参数。我们将接触更多的参数传递方式。
回忆一下位置传递:
def f(a,b,c): return a+b+c print(f(1,2,3))
在调用 f 时,1,2,3根据位置分别传递给了a,b,c。
###1、关键字传递
有些情况下,用位置传递会感觉比较死板。关键字(keyword)传递是根据每个参数的名字传递参数。关键字并不用遵守位置的对应关系。依然沿用上面f的定义,更改调用方式:
print(f(c=3,b=2,a=1))
关键字传递可以和位置传递混用。但位置参数要出现在关键字参数之前:
print(f(1,c=3,b=2))
示例:
###2、参数默认值
在定义函数的时候,使用形如a=19的方式,可以给参数赋予默认值(default)。如果该参数最终没有被传递值,将使用该默认值。
def f(a,b,c=10): return a+b+c print(f(3,2)) print(f(3,2,1))
在第一次调用函数f时, 我们并没有足够的值,c没有被赋值,c将使用默认值10.
第二次调用函数的时候,c被赋值为1,不再使用默认值。
###3、包裹传递
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)[b]位置参数,或者包裹关键字参数[/b],来进行参数传递,会非常有用。
下面是包裹位置传递的例子:
def func(*name): print type(name) print name func(1,4,6) func(5,6,7,1,2,3)
两次调用,尽管参数个数不同,都基于同一个func定义。在func的参数表中,所有的参数被name收集,根据位置合并成一个元组(tuple),这就是包裹位置传递。
为了提醒Python参数,name是包裹位置传递所用的元组名,在定义func时,在name前加*号。
下面是包裹关键字传递的例子:
def func(**dict): print type(dict) print dict func(a=1,b=9) func(m=2,n=1,c=11)
与上面一个例子类似,dict是一个字典,收集所有的关键字,传递给函数func。为了提醒Python,参数dict是包裹关键字传递所用的字典,**在dict前加 ** **。
包裹传递的关键在于定义函数时,在相应元组或字典前加 * 或 * * 。
注意:字典传递的参数必须传递参数名,参数值形式,如果直接传入参数值则会报错。
###4、解包裹
* 和 **,也可以在调用的时候使用,即解包裹(unpacking), 下面为例:
def func(a,b,c): print a,b,c args = (1,3,4) func(*args)
在这个例子中,所谓的解包裹,就是在传递tuple时,让tuple的每一个元素对应一个位置参数。在调用func时使用 * ,是为了提醒Python:我想要把args拆成分散的三个元素,分别传递给a,b,c。(设想一下在调用func时,args前面没有 * 会是什么后果?)
相应的,也存在对词典的解包裹,使用相同的func定义,然后:
dict = {'a':1,'b':2,'c':3}
func(**dict)在传递词典dict时,让词典的每个键值对作为一个关键字传递给func。
###5、混合
在定义或者调用参数时,参数的几种传递方式可以混合。但在过程中要小心前后顺序。基本原则是:先位置,再关键字,再包裹位置,再包裹关键字,并且根据上面所说的原理细细分辨。
注意:请注意定义时和调用时的区分。包裹和解包裹并不是相反操作,是两个相对独立的过程。
注:本Python学习笔记是按照Vamei的博客教程来学习的,如有兴趣可以参考Vamei Python快速开发博文

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法