动态分区分配
2016-06-05 10:12
288 查看
一.实验目的
1.通过这次实验,加深对动态分区分配的理解,进一步掌握首次适应算法和最佳适应算法的理解。了 解动态分区分配方式中使用的数据结构和分配算法,进一步加深对动态分区存储管理方式及其实现 过程的理解。提高学生设计实验、发现问题、分析问题和解决问题的能力。
2.学会可变式分区管理的原理是在处理作业过程中建立分区,使分区大小正好适合作业的需求。
3.当一个作业执行完成后,作业所占的分区应归还给系统。
二.实验原理
首次适应算法
以空闲分区链为例来说明采用FF算法时的分配情况。FF算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的分区为止;然后再按照作业的大小,从该分取中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直到链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。该算法倾向于优先利用内存中低地址部分的空闲分区,从而保留了高址部分的大空闲区。这给为以后到达的大作业分配大的内存空间创造了条件,其缺点是低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这无疑会增加查找可用空闲分区时的开销。
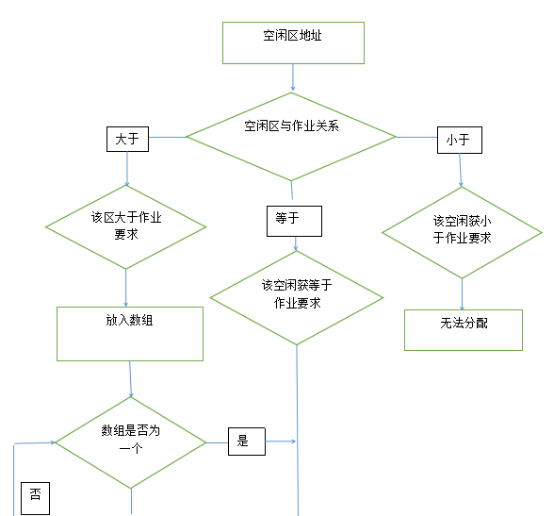
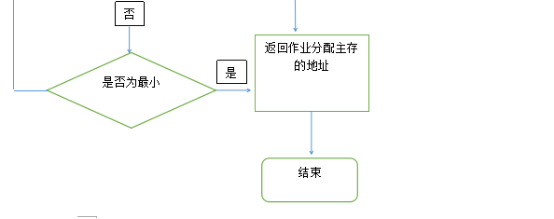
最佳适应算法
所谓“最佳”是指每次为作业分配内存时,总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。为了加速寻找,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成以空闲分区链。这样,第一次找到的能满足要求的空闲区,必然是最佳的。孤立地看,最佳适应算法似乎是最佳的,然而在宏观上却不一定。因为每次分配后所割下来的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的开销。
三.实验流程图
首次适用算法
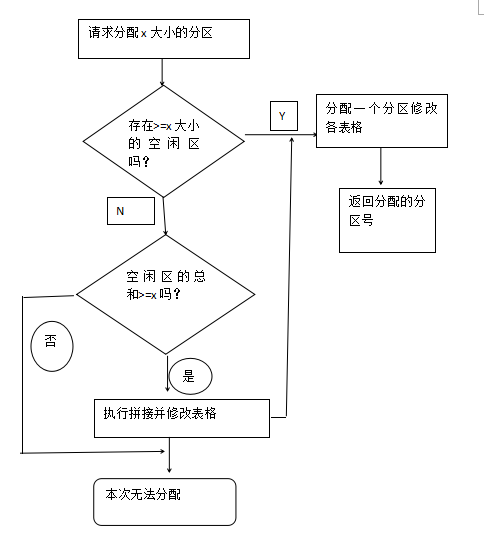
最佳适用算法
四.程序清单(VS 2013)#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
enum STATE
{
Free,
Busy
};
struct subAreaNode
{
int addr; // 起始地址
int size; // 分区大小
int taskId; // 作业号
STATE state; // 分区状态
subAreaNode *pre; // 分区前向指针
subAreaNode *nxt; // 分区后向指针
}subHead;
// 初始化空闲分区链
void intSubArea()
{
// 分配初始分区内存
subAreaNode *fir = (subAreaNode *)malloc(sizeof(subAreaNode));
// 给首个分区赋值
fir->addr = 0;
fir->size = 1000; // 内存初始大小
fir->state = Free;
fir->taskId = -1;
fir->pre = &subHead;
fir->nxt = NULL;
// 初始化分区头部信息
subHead.pre = NULL;
subHead.nxt = fir;
}
// 首次适应算法
int firstFit(int taskId, int size)
{
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
if (p->state == Free && p->size >= size)
{
// 找到要分配的空闲分区
if (p->size - size <= 10)
{
// 整块分配
p->state = Busy;
p->taskId = taskId;
}
else {
// 分配大小为size的区间
subAreaNode *node = (subAreaNode *)malloc(sizeof(subAreaNode));
node->addr = p->addr + size;
node->size = p->size - size;
node->state = Free;
node->taskId = -1;
// 修改分区链节点指针
node->pre = p;
node->nxt = p->nxt;
if (p->nxt != NULL)
{
p->nxt->pre = node;
}
p->nxt = node;
// 分配空闲区间
p->size = size;
p->state = Busy;
p->taskId = taskId;
}
printf("内存分配成功!\n");
return 1;
}
p = p->nxt;
}
printf("找不到合适的内存分区,分配失败...\n");
return 0;
}
// 最佳适应算法
int bestFit(int taskId, int size)
{
subAreaNode *tar = NULL;
int tarSize = 1000 + 1;
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
// 寻找最佳空闲区间
if (p->state == Free && p->size >= size && p->size < tarSize) {
tar = p;
tarSize = p->size;
}
p = p->nxt;
}
if (tar != NULL) {
// 找到要分配的空闲分区
if (tar->size - size <= 10)
{
// 整块分配
tar->state = Busy;
tar->taskId = taskId;
}
else
{
// 分配大小为size的区间
subAreaNode *node = (subAreaNode *)malloc(sizeof(subAreaNode));
node->addr = tar->addr + size;
node->size = tar->size - size;
node->state = Free;
node->taskId = -1;
// 修改分区链节点指针
node->pre = tar;
node->nxt = tar->nxt;
if (tar->nxt != NULL)
{
tar->nxt->pre = node;
}
tar->nxt = node;
// 分配空闲区间
tar->size = size;
tar->state = Busy;
tar->taskId = taskId;
}
printf("内存分配成功!\n");
return 1;
}
else
{
printf("找不到合适的内存分区,分配失败...\n");
return 0;
}
}
int freeSubArea(int taskId) // 回收内存
{
int flag = 0;
subAreaNode *p = subHead.nxt, *pp;
while (p != NULL)
{
if (p->state == Busy && p->taskId == taskId)
{
flag = 1;
if ((p->pre != &subHead && p->pre->state == Free)
&& (p->nxt != NULL && p->nxt->state == Free))
{
// 情况1:合并上下两个分区
// 先合并上区间
pp = p;
p = p->pre;
p->size += pp->size;
p->nxt = pp->nxt;
pp->nxt->pre = p;
free(pp);
// 后合并下区间
pp = p->nxt;
p->size += pp->size;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else if ((p->pre == &subHead || p->pre->state == Busy)
&& (p->nxt != NULL && p->nxt->state == Free))
{
// 情况2:只合并下面的分区
pp = p->nxt;
p->size += pp->size;
p->state = Free;
p->taskId = -1;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else if ((p->pre != &subHead && p->pre->state == Free)
&& (p->nxt == NULL || p->nxt->state == Busy))
{
// 情况3:只合并上面的分区
pp = p;
p = p->pre;
p->size += pp->size;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else
{
// 情况4:上下分区均不用合并
p->state = Free;
p->taskId = -1;
}
}
p = p->nxt;
}
if (flag == 1)
{
// 回收成功
printf("内存分区回收成功...\n");
return 1;
}
else
{
// 找不到目标作业,回收失败
printf("找不到目标作业,内存分区回收失败...\n");
return 0;
}
}
// 显示空闲分区链情况
void showSubArea()
{
printf("*********************************************\n");
printf("** 当前的内存分配情况如下: **\n");
printf("*********************************************\n");
printf("** 起始地址 | 空间大小 | 工作状态 | 作业号 **\n");
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
printf("**-----------------------------------------**\n");
printf("**");
printf(" %3d k |", p->addr);
printf(" %3d k |", p->size);
printf(" %s |", p->state == Free ? "Free" : "Busy");
if (p->taskId > 0)
{
printf(" %2d ", p->taskId);
}
else
{
printf(" ");
}
printf("**\n");
p = p->nxt;
}
printf("*********************************************\n");
}
int main()
{
int option, ope, taskId, size;
// 初始化空闲分区链
intSubArea();
// 选择分配算法
while (1)
{
printf("\n\n");
printf("\t****************请选择要模拟的分配算法******************\n");
printf("\n\n");
printf("\t \t 0 首次适应算法 \n");
printf("\n\n");
printf("\t \t 1 最佳适应算法 \n");
printf("\n\n");
printf("\t\t\t\t你的选择是:");
scanf("%d", &option);
if (option == 0)
{
printf("你选择了首次适应算法,下面进行算法的模拟\n");
break;
}
else if (option == 1)
{
printf("你选择了最佳适应算法,下面进行算法的模拟\n");
break;
}
else
{
printf("错误:请输入 0/1\n\n");
}
}
// 模拟动态分区分配算法
while (1)
{
printf("\n");
printf("*********************************************\n");
printf("** 1: 分配内存 2: 回收内存 0: 退出 **\n");
printf("*********************************************\n");
scanf("%d", &ope);
if (ope == 0) break;
if (ope == 1) {
// 模拟分配内存
printf("请输入作业号: ");
scanf("%d", &taskId);
printf("请输入需要分配的内存大小(KB): ");
scanf("%d", &size);
if (size <= 0)
{
printf("错误:分配内存大小必须为正值\n");
continue;
}
// 调用分配算法
if (option == 0)
{
firstFit(taskId, size);
}
else
{
bestFit(taskId, size);
}
// 显示空闲分区链情况
showSubArea();
}
else if (ope == 2)
{
// 模拟回收内存
printf("请输入要回收的作业号: ");
scanf("%d", &taskId);
freeSubArea(taskId);
// 显示空闲分区链情况
showSubArea();
}
else
{
printf("错误:请输入 0/1/2\n");
}
}
printf("分配算法模拟结束\n");
system("pause");
return 0;
}
五.实验结果截图
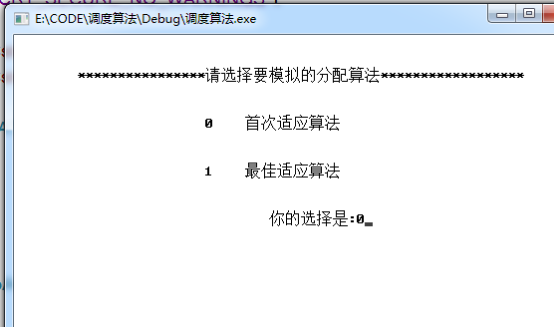
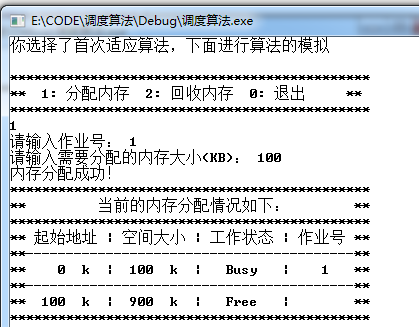
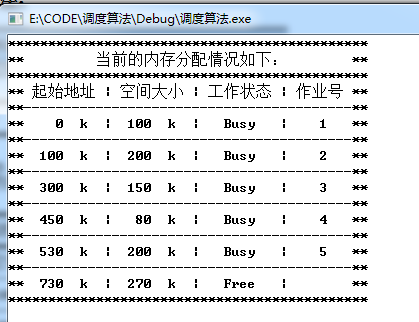
经过多次内存后:
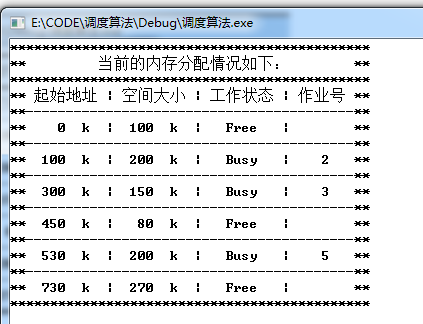
回收作业1和作业4后:
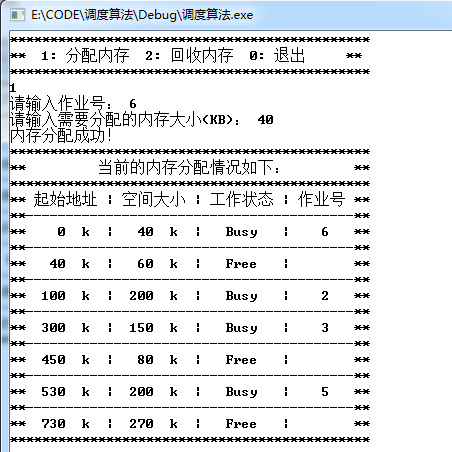
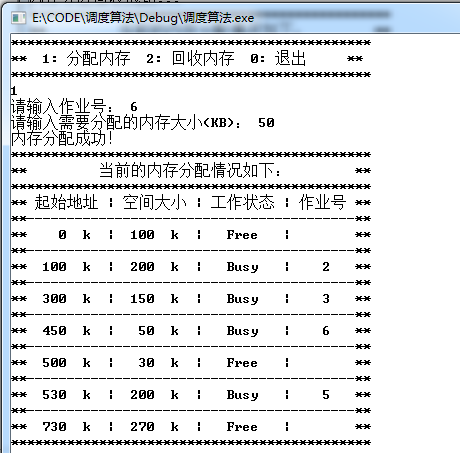
此时分两种情况分别模拟首次使用算法和最佳使用算法为作业6分配40KB内存:
模拟首次适应算法:
最佳适用算法:
六.结果分析
通过多个分区分配,当回收作业1释放100K空间,回收作业4释放80K空间后,再为作业6分配40K空间。首次适用算法会优先拿作业1释放的100K空间为作业6分配内存。最佳适用算法则会优先拿作业4释放的80K空间为作业6分配内存。
根据实验得出结论,首次适用算法是从空闲分区表的头指针开始查找,把最先能够满足要求的空闲区分配给作业。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区,此算法比较节省时间。
最佳适用算法将可利用空闲表中一个不小于“请求”且最接近"请求"的空闲区的一部分分配给用户。分配与回收都需要对可利用空闲表从头至尾查询一遍。在分配时容易产生太小而无法利用的内存碎片,同时这种做法也保留了那些很大的内存块以备响应将来发生的内存量较大的用户的请求。这种分配算法适合请求分配内存大小范围较广的系统,此算法最费时间。
1.通过这次实验,加深对动态分区分配的理解,进一步掌握首次适应算法和最佳适应算法的理解。了 解动态分区分配方式中使用的数据结构和分配算法,进一步加深对动态分区存储管理方式及其实现 过程的理解。提高学生设计实验、发现问题、分析问题和解决问题的能力。
2.学会可变式分区管理的原理是在处理作业过程中建立分区,使分区大小正好适合作业的需求。
3.当一个作业执行完成后,作业所占的分区应归还给系统。
二.实验原理
首次适应算法
以空闲分区链为例来说明采用FF算法时的分配情况。FF算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的分区为止;然后再按照作业的大小,从该分取中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直到链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。该算法倾向于优先利用内存中低地址部分的空闲分区,从而保留了高址部分的大空闲区。这给为以后到达的大作业分配大的内存空间创造了条件,其缺点是低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这无疑会增加查找可用空闲分区时的开销。
最佳适应算法
所谓“最佳”是指每次为作业分配内存时,总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。为了加速寻找,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成以空闲分区链。这样,第一次找到的能满足要求的空闲区,必然是最佳的。孤立地看,最佳适应算法似乎是最佳的,然而在宏观上却不一定。因为每次分配后所割下来的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的开销。
三.实验流程图
首次适用算法
最佳适用算法
四.程序清单(VS 2013)#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
enum STATE
{
Free,
Busy
};
struct subAreaNode
{
int addr; // 起始地址
int size; // 分区大小
int taskId; // 作业号
STATE state; // 分区状态
subAreaNode *pre; // 分区前向指针
subAreaNode *nxt; // 分区后向指针
}subHead;
// 初始化空闲分区链
void intSubArea()
{
// 分配初始分区内存
subAreaNode *fir = (subAreaNode *)malloc(sizeof(subAreaNode));
// 给首个分区赋值
fir->addr = 0;
fir->size = 1000; // 内存初始大小
fir->state = Free;
fir->taskId = -1;
fir->pre = &subHead;
fir->nxt = NULL;
// 初始化分区头部信息
subHead.pre = NULL;
subHead.nxt = fir;
}
// 首次适应算法
int firstFit(int taskId, int size)
{
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
if (p->state == Free && p->size >= size)
{
// 找到要分配的空闲分区
if (p->size - size <= 10)
{
// 整块分配
p->state = Busy;
p->taskId = taskId;
}
else {
// 分配大小为size的区间
subAreaNode *node = (subAreaNode *)malloc(sizeof(subAreaNode));
node->addr = p->addr + size;
node->size = p->size - size;
node->state = Free;
node->taskId = -1;
// 修改分区链节点指针
node->pre = p;
node->nxt = p->nxt;
if (p->nxt != NULL)
{
p->nxt->pre = node;
}
p->nxt = node;
// 分配空闲区间
p->size = size;
p->state = Busy;
p->taskId = taskId;
}
printf("内存分配成功!\n");
return 1;
}
p = p->nxt;
}
printf("找不到合适的内存分区,分配失败...\n");
return 0;
}
// 最佳适应算法
int bestFit(int taskId, int size)
{
subAreaNode *tar = NULL;
int tarSize = 1000 + 1;
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
// 寻找最佳空闲区间
if (p->state == Free && p->size >= size && p->size < tarSize) {
tar = p;
tarSize = p->size;
}
p = p->nxt;
}
if (tar != NULL) {
// 找到要分配的空闲分区
if (tar->size - size <= 10)
{
// 整块分配
tar->state = Busy;
tar->taskId = taskId;
}
else
{
// 分配大小为size的区间
subAreaNode *node = (subAreaNode *)malloc(sizeof(subAreaNode));
node->addr = tar->addr + size;
node->size = tar->size - size;
node->state = Free;
node->taskId = -1;
// 修改分区链节点指针
node->pre = tar;
node->nxt = tar->nxt;
if (tar->nxt != NULL)
{
tar->nxt->pre = node;
}
tar->nxt = node;
// 分配空闲区间
tar->size = size;
tar->state = Busy;
tar->taskId = taskId;
}
printf("内存分配成功!\n");
return 1;
}
else
{
printf("找不到合适的内存分区,分配失败...\n");
return 0;
}
}
int freeSubArea(int taskId) // 回收内存
{
int flag = 0;
subAreaNode *p = subHead.nxt, *pp;
while (p != NULL)
{
if (p->state == Busy && p->taskId == taskId)
{
flag = 1;
if ((p->pre != &subHead && p->pre->state == Free)
&& (p->nxt != NULL && p->nxt->state == Free))
{
// 情况1:合并上下两个分区
// 先合并上区间
pp = p;
p = p->pre;
p->size += pp->size;
p->nxt = pp->nxt;
pp->nxt->pre = p;
free(pp);
// 后合并下区间
pp = p->nxt;
p->size += pp->size;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else if ((p->pre == &subHead || p->pre->state == Busy)
&& (p->nxt != NULL && p->nxt->state == Free))
{
// 情况2:只合并下面的分区
pp = p->nxt;
p->size += pp->size;
p->state = Free;
p->taskId = -1;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else if ((p->pre != &subHead && p->pre->state == Free)
&& (p->nxt == NULL || p->nxt->state == Busy))
{
// 情况3:只合并上面的分区
pp = p;
p = p->pre;
p->size += pp->size;
p->nxt = pp->nxt;
if (pp->nxt != NULL)
{
pp->nxt->pre = p;
}
free(pp);
}
else
{
// 情况4:上下分区均不用合并
p->state = Free;
p->taskId = -1;
}
}
p = p->nxt;
}
if (flag == 1)
{
// 回收成功
printf("内存分区回收成功...\n");
return 1;
}
else
{
// 找不到目标作业,回收失败
printf("找不到目标作业,内存分区回收失败...\n");
return 0;
}
}
// 显示空闲分区链情况
void showSubArea()
{
printf("*********************************************\n");
printf("** 当前的内存分配情况如下: **\n");
printf("*********************************************\n");
printf("** 起始地址 | 空间大小 | 工作状态 | 作业号 **\n");
subAreaNode *p = subHead.nxt;
while (p != NULL)
{
printf("**-----------------------------------------**\n");
printf("**");
printf(" %3d k |", p->addr);
printf(" %3d k |", p->size);
printf(" %s |", p->state == Free ? "Free" : "Busy");
if (p->taskId > 0)
{
printf(" %2d ", p->taskId);
}
else
{
printf(" ");
}
printf("**\n");
p = p->nxt;
}
printf("*********************************************\n");
}
int main()
{
int option, ope, taskId, size;
// 初始化空闲分区链
intSubArea();
// 选择分配算法
while (1)
{
printf("\n\n");
printf("\t****************请选择要模拟的分配算法******************\n");
printf("\n\n");
printf("\t \t 0 首次适应算法 \n");
printf("\n\n");
printf("\t \t 1 最佳适应算法 \n");
printf("\n\n");
printf("\t\t\t\t你的选择是:");
scanf("%d", &option);
if (option == 0)
{
printf("你选择了首次适应算法,下面进行算法的模拟\n");
break;
}
else if (option == 1)
{
printf("你选择了最佳适应算法,下面进行算法的模拟\n");
break;
}
else
{
printf("错误:请输入 0/1\n\n");
}
}
// 模拟动态分区分配算法
while (1)
{
printf("\n");
printf("*********************************************\n");
printf("** 1: 分配内存 2: 回收内存 0: 退出 **\n");
printf("*********************************************\n");
scanf("%d", &ope);
if (ope == 0) break;
if (ope == 1) {
// 模拟分配内存
printf("请输入作业号: ");
scanf("%d", &taskId);
printf("请输入需要分配的内存大小(KB): ");
scanf("%d", &size);
if (size <= 0)
{
printf("错误:分配内存大小必须为正值\n");
continue;
}
// 调用分配算法
if (option == 0)
{
firstFit(taskId, size);
}
else
{
bestFit(taskId, size);
}
// 显示空闲分区链情况
showSubArea();
}
else if (ope == 2)
{
// 模拟回收内存
printf("请输入要回收的作业号: ");
scanf("%d", &taskId);
freeSubArea(taskId);
// 显示空闲分区链情况
showSubArea();
}
else
{
printf("错误:请输入 0/1/2\n");
}
}
printf("分配算法模拟结束\n");
system("pause");
return 0;
}
五.实验结果截图
经过多次内存后:
回收作业1和作业4后:
此时分两种情况分别模拟首次使用算法和最佳使用算法为作业6分配40KB内存:
模拟首次适应算法:
最佳适用算法:
六.结果分析
通过多个分区分配,当回收作业1释放100K空间,回收作业4释放80K空间后,再为作业6分配40K空间。首次适用算法会优先拿作业1释放的100K空间为作业6分配内存。最佳适用算法则会优先拿作业4释放的80K空间为作业6分配内存。
根据实验得出结论,首次适用算法是从空闲分区表的头指针开始查找,把最先能够满足要求的空闲区分配给作业。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区,此算法比较节省时间。
最佳适用算法将可利用空闲表中一个不小于“请求”且最接近"请求"的空闲区的一部分分配给用户。分配与回收都需要对可利用空闲表从头至尾查询一遍。在分配时容易产生太小而无法利用的内存碎片,同时这种做法也保留了那些很大的内存块以备响应将来发生的内存量较大的用户的请求。这种分配算法适合请求分配内存大小范围较广的系统,此算法最费时间。

相关文章推荐
- 顺序表的静态存储
- TCP建立连接和拆除连接的过程
- printf函数源码实现
- 强悍的 vim —— 删除空行、删除注释以及加注释解注释
- memset函数源码分析
- memset函数源码实现
- 求数组长度sizeof
- vector中erase用法注意事项
- 笔试题: 不使用中间变量求const字符串长度,即实现求字符串长度库函数strlen函数
- strlen和sizeof的区别和联系
- 写一个递归函数DigitSum(n),输入一个非负整数,返回组成它的数字之和
- 递归实现 n的k次方
- 冒泡排序
- 参数传递 可变长参数函数
- 如何让网页大小自适应的JS代码
- 递归实现 参数字符串中的字符反向排列
- __FILE__ __DATE__ __TIME__ __LINE__
- 宏、函数、宏和函数的区别
- assert用法
- C++ Assert()断言机制原理以及使用