The Elements of Statistical Learning (第4章)
2016-06-02 15:20
183 查看
这本书的写法真不符合我口味。
判别准则,判别分析 , 其实说的就是分类方法,分类公式。
LDA(Linear Discriminant Analysis)
从概率角度看待这个问题,可以认为分类问题就是知道了x值,求x属于哪一个类别的概率最大的问题,也就是求所有后验概率1,...,k中最大的那一个。

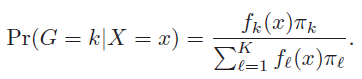
然后比较这K个后验证概率的大小,找最大了。最简单的方法就是两两比较。 比如A-B两者相减大于零 或者 两者相除大于1,下文用的是相除后取对数,判断是否大于0
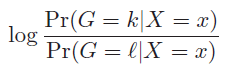
(2)
若假设每一个类别中的x服从高斯分布,那么就有:
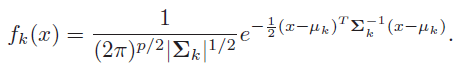
先考虑协方差矩阵相等的情形,这时候(2)式就化为
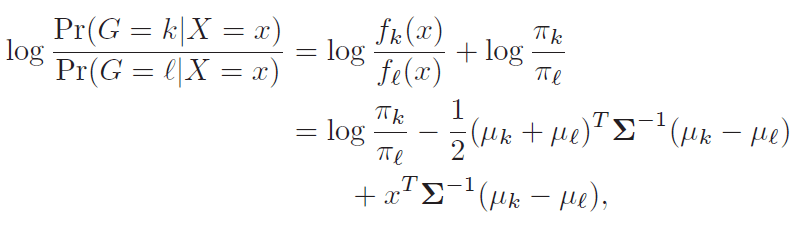
(3)
判断该式是否大于0。 然后观察上式,k,l部分能分离,然后可以等价于
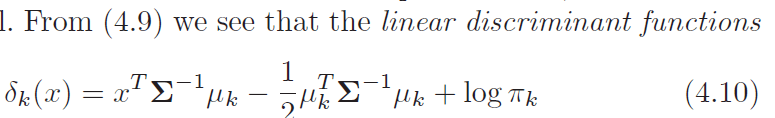
k分别取k与l,然后对减,与(3)式,因此我们只要考虑该式,比大小即可。然后该式就是最终得到的所谓的 线性判别函数了,然后就是实际应用中的LDA算法了。
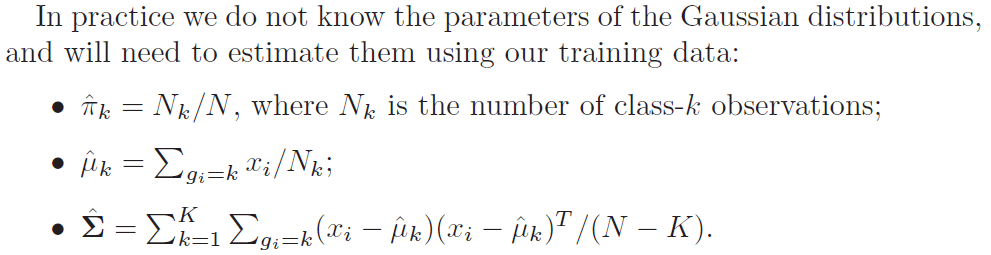
接下来关于算法具体理论证明以及实现的更详细的部分就去看LDA算法系列吧。
考虑完了特殊情形,再回到一般的情形进行考虑。

就得到了QDA判别准则。
判别准则,判别分析 , 其实说的就是分类方法,分类公式。
LDA(Linear Discriminant Analysis)
从概率角度看待这个问题,可以认为分类问题就是知道了x值,求x属于哪一个类别的概率最大的问题,也就是求所有后验概率1,...,k中最大的那一个。
然后比较这K个后验证概率的大小,找最大了。最简单的方法就是两两比较。 比如A-B两者相减大于零 或者 两者相除大于1,下文用的是相除后取对数,判断是否大于0
(2)
若假设每一个类别中的x服从高斯分布,那么就有:
先考虑协方差矩阵相等的情形,这时候(2)式就化为
(3)
判断该式是否大于0。 然后观察上式,k,l部分能分离,然后可以等价于
k分别取k与l,然后对减,与(3)式,因此我们只要考虑该式,比大小即可。然后该式就是最终得到的所谓的 线性判别函数了,然后就是实际应用中的LDA算法了。
接下来关于算法具体理论证明以及实现的更详细的部分就去看LDA算法系列吧。
考虑完了特殊情形,再回到一般的情形进行考虑。
就得到了QDA判别准则。

相关文章推荐
- Gradle学习系列之三——读懂Gradle语法
- Machine Vision知识积累
- Hadoop 3.0纠删码(Erasure Coding):节省一半存储空间
- 图解Android Studio导入Eclipse项目源码
- 第二阶段站立会议第七天
- 用户信息修改页面搭建
- iOS 颜色填充
- Oracle 海量数据处理- 索引的选择
- 04-树4 是否同一棵二叉搜索树
- Linux环境下安装MySQL|Linux下Mysql安装教程
- C语言实现字符串的查找和替换
- 集合替换元素
- mysql基础(二)
- git clone: error: RPC failed; result=56, HTTP code = 200
- 1.7三分钟读懂Saas、Paas、IaaS的区别
- LLDB调试命令(一) p 和 po 命名行的鼻祖 expression 命令
- 【转】忙里偷闲写的小例子---读取android根目录下的文件或文件夹
- git patch
- 【Java】StopWatch任务执行时间监视器
- adaboost简介