hadoop学习之HDFS(2.1):linux下eclipse中配置hadoop-mapreduce开发环境并运行WordCount.java程序
2016-05-25 10:52
1276 查看
此时我们已经搭建好hadoop完全分布式集群,现在我们来配置eclipse并运行WordCount.java程序。
1,下载解压eclipse,前提要配置好jdk。
2,将下载的文件hadoop-eclipse-plugin-1.2.1.jar(csdn即可找到)放到eclipse下的plugin文件夹下。
3,重新打开eclipse,左侧导航栏可以看到DFS Locations。
4,在右上角显示MR图标:eclipse > window > perspective > open perspective > other > Map/Reduce > OK
5,点击下方”Map/Reduce Location“,右键 > new hadoop location。
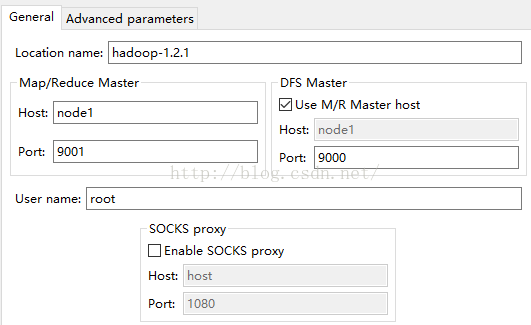
6,下图是具体配置,其中,Location name可以随便起名字。但是,Map/Reduce Master和DFS Master下的Host主机名必须要和core-site.xml中设置的一样,这里我们设置为node1(如果是伪分布式,就是默认的localhost),两个端口号分别是:9001,9000。尤其注意:User
name是配置hadoop的用户名,这里是root,windows下默认不是root,记得要改过来。
7,新建mr工程,new project,使用命令行在hdfs上创建文件夹:/usr/input/wc(并上传文本文件)。
8,src下建包,将hadoop自带的WordCount.java拷贝到包下,只需改程序的第一句:包名修改成现在的包
9,执行程序:Run as > Run Configurations > Arguments 输入/usr/input/wc /usr/output/wc > Run
10,DFS:/usr/output/wc下会出现结果文件。
如果执行过程中出现一下错误信息:
1,Exception in thread "main":Input path does not exist:file: *******
输入路径名的错误,将“/user/root/input”,改为:PathIn="hdfs://localhost:9000/user/root/input"。
2,出现如下信息:
那么,在项目的src目录下,新建file,名为"log4j.properties",内容为:
或者在eclipse上测试无误后,将程序打包,放到集群上去运行:./hadoop jar wordcount.jar
1,下载解压eclipse,前提要配置好jdk。
2,将下载的文件hadoop-eclipse-plugin-1.2.1.jar(csdn即可找到)放到eclipse下的plugin文件夹下。
3,重新打开eclipse,左侧导航栏可以看到DFS Locations。
4,在右上角显示MR图标:eclipse > window > perspective > open perspective > other > Map/Reduce > OK
5,点击下方”Map/Reduce Location“,右键 > new hadoop location。
6,下图是具体配置,其中,Location name可以随便起名字。但是,Map/Reduce Master和DFS Master下的Host主机名必须要和core-site.xml中设置的一样,这里我们设置为node1(如果是伪分布式,就是默认的localhost),两个端口号分别是:9001,9000。尤其注意:User
name是配置hadoop的用户名,这里是root,windows下默认不是root,记得要改过来。
7,新建mr工程,new project,使用命令行在hdfs上创建文件夹:/usr/input/wc(并上传文本文件)。
8,src下建包,将hadoop自带的WordCount.java拷贝到包下,只需改程序的第一句:包名修改成现在的包
9,执行程序:Run as > Run Configurations > Arguments 输入/usr/input/wc /usr/output/wc > Run
10,DFS:/usr/output/wc下会出现结果文件。
如果执行过程中出现一下错误信息:
1,Exception in thread "main":Input path does not exist:file: *******
输入路径名的错误,将“/user/root/input”,改为:PathIn="hdfs://localhost:9000/user/root/input"。
2,出现如下信息:
log4j:WARN No appenders could be found for logger (dao.hsqlmanager). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
那么,在项目的src目录下,新建file,名为"log4j.properties",内容为:
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n但是,这样的配置下,mr程序跑的是本地模式,而非yarn模式,若要将任务提交给yarn来执行,就在项目的src目录下将hadoop的4个配置文件拷过来即可。然后访问node1:8088即可查看mr任务的状态了。或者在eclipse上测试无误后,将程序打包,放到集群上去运行:./hadoop jar wordcount.jar

相关文章推荐
- Linux环境下SVN服务器配置过程
- linux性能调优概述
- Linux常用命令操作
- kickstart无人值守安装CentOS6
- linux file System inode
- linux file System directory
- linux fix superblock not found
- Linux下的Backlight子系统(一)【转】
- linux partition
- Linux+qt生成和调用静态库
- Linux/ visual studio 编译使用Poco
- Linux常用命令
- Linux下使用system()函数一定要谨慎
- Linux File System brief intro
- 在线LDD3[linux device driver]
- Linux设置时间同步
- Linux下安装部署Jboss
- linux硬件设备操作函数 open(/dev/ietctl, O_RDWR|...)
- 网易视频云技术分享:linux软raid的bitmap分析
- Linux下NTP服务器配置