Hadoop平台运用朴素贝叶斯算法进行文档分类总结
2016-05-24 16:44
471 查看
上一篇文章介绍了朴素贝叶斯算法的基本思想,这里主要讲解一下在Hadoop中运用朴素贝叶斯算法进行文档分类的思路。
关于文档分类系统的实现,Github源码及测试数据:https://github.com/xingzhexiaozhu/Classify-Dos
朴素贝叶斯分类器基于一个简单的假定,即给定的目标值属性之间是相互独立。贝叶斯公式之所以有用是因为在日常生活中,我们可以很容易得到P(A|B),而很难得出P(B|A),但我们更关心P(B|A),所以就可以根据贝叶斯公式来计算。
应用在文档分类中有:P(c|d)=(P(c)P(d|c))/P(d),而对于一份文档在分类时则考虑其中的每个单词的概率在该类中出现的概率P(d│c)=P(tk1│c)P(tk2│c)…P(tkn|c),判断每个文档属于哪个类别时时总有P(d)不变,所以等式左边正比于分子,即公式:
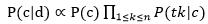
最后对于待分类文档,求出该文档在各类别中的概率,哪个概率大就将该项分类到对应的类别中,即

(2)分类器训练阶段:输入是训练集合及特征属性,计算出各个类在训练样本中出现的先验概率及各特征属性对应类别的条件概率,输出分类器;
(3)应用阶段:输入分类器及测试集合,输出待分类项与类别的映射关系,即用户期望的分类的结果。
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现的次数之和+1)/(类c的单词总数+训练样本中不重复特征词总数)
先验概率P(c)=类c下的单词总数/整个训练样本的单词总数
(2)伯努力模型(Bernoulli model) ---以文件为粒度
类条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下文件总数+2)
先验概率P(c)=类c下文件总数/整个训练样本的文件总数
(2)Log取对数化乘法运算为加法运算。不论是多项式模型还是伯努力模型计算条件概率时,都涉及到多个属性的概率值相乘的情况,当足够多的小数相乘时就会出现下溢导致最终得到不准确的结果。这时可以借助对数运算的性质,即log(xy)=log(x)+log(y),使得求积运算转化为求和运算,而log函数是单调递增函数,所以可以直接根据log运算的结果判断文档在各个类中的概率的大小而不影响最终分类结果。
关于文档分类系统的实现,Github源码及测试数据:https://github.com/xingzhexiaozhu/Classify-Dos
一、贝叶斯原理
贝叶斯分类算法的理论基于贝叶斯公式,P(B|A)=(P(A|B)P(B))/P(A) ,其中P(A|B)称为条件概率,P(B)先验概率,对应P(B|A)为后验概率。朴素贝叶斯分类器基于一个简单的假定,即给定的目标值属性之间是相互独立。贝叶斯公式之所以有用是因为在日常生活中,我们可以很容易得到P(A|B),而很难得出P(B|A),但我们更关心P(B|A),所以就可以根据贝叶斯公式来计算。
应用在文档分类中有:P(c|d)=(P(c)P(d|c))/P(d),而对于一份文档在分类时则考虑其中的每个单词的概率在该类中出现的概率P(d│c)=P(tk1│c)P(tk2│c)…P(tkn|c),判断每个文档属于哪个类别时时总有P(d)不变,所以等式左边正比于分子,即公式:
最后对于待分类文档,求出该文档在各类别中的概率,哪个概率大就将该项分类到对应的类别中,即
二、贝叶斯分类器的三个步骤
(1)准备工作阶段:根据实际情况确定特征属性,并对初始数据预处理形成训练集合(唯一的人工阶段,决定最终的分类质量);(2)分类器训练阶段:输入是训练集合及特征属性,计算出各个类在训练样本中出现的先验概率及各特征属性对应类别的条件概率,输出分类器;
(3)应用阶段:输入分类器及测试集合,输出待分类项与类别的映射关系,即用户期望的分类的结果。
三、贝叶斯分类应用在文档分类中的两个模型
(1)多项式模型(multinomial model)---以单词为粒度类条件概率P(tk|c)=(类c下单词tk在各个文档中出现的次数之和+1)/(类c的单词总数+训练样本中不重复特征词总数)
先验概率P(c)=类c下的单词总数/整个训练样本的单词总数
(2)伯努力模型(Bernoulli model) ---以文件为粒度
类条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下文件总数+2)
先验概率P(c)=类c下文件总数/整个训练样本的文件总数
四、贝叶斯分类的两点注意事项
(1)Laplace校准。在计算概率时,有可能出现这种情况,即在测试集中出现的单词在训练集中没有出现过,这时直接计算的话其概率就为0,然后导致结果不准确,上面的公式在分子、分母中加上平滑因子就可以处理这种情况;(2)Log取对数化乘法运算为加法运算。不论是多项式模型还是伯努力模型计算条件概率时,都涉及到多个属性的概率值相乘的情况,当足够多的小数相乘时就会出现下溢导致最终得到不准确的结果。这时可以借助对数运算的性质,即log(xy)=log(x)+log(y),使得求积运算转化为求和运算,而log函数是单调递增函数,所以可以直接根据log运算的结果判断文档在各个类中的概率的大小而不影响最终分类结果。
五、设计MapReduce算法
先将数据集分成两部分,一部分作训练集,另一部分作测试集。针对两种模型,可分别设计对应的MapReduce算法,用训练集训练出分类模型,用测试集进行分类结果测试。最终采用P、R和F1进行分类准确率、召回率的评估。
相关文章推荐
- 解决域名访问出现中文乱码,而本地测试不会出现的问题
- 用AVAudioRecorder录音,AVAudioPlayer播放声音很小
- centos7安装docker
- 低权重网站通过外链获得流量的办法
- linux上安装Eclipse
- Matika版OpenStack伪生产环境部署-自动化安装CentOS7
- hive自定义udf实现md5功能
- 基于概率论的分类方法:朴素贝叶斯---过滤网站恶意留言
- linux驱动---用I/O命令访问PCI总线设备配置空间
- linux驱动---用I/O命令访问PCI总线设备配置空间
- shell 中正则表达式替换赋值 测试示例
- linux驱动---用I/O命令访问PCI总线设备配置空间
- linux驱动---用I/O命令访问PCI总线设备配置空间
- linux 中软链接的使用
- linux内核细节-va_arg、va_end、va_start、printf
- Codecademy网站安利 及 javaScript学习
- Linux常用命令
- 检索用opencv常用函数
- Apache+Tomcat集群配置
- Linux环境中使用“sudo echo....”提示权限不够的解决办法