Python函数式编程——map()、reduce()
2016-05-24 14:22
411 查看
Python函数式编程——map()、reduce()
更多6
提起map和reduce想必大家并不陌生,Google公司2003年提出了一个名为MapReduce的编程模型[1],用于处理大规模海量数据,并在之后广泛的应用于Google的各项应用中,2006年Apache的Hadoop项目[2]正式将MapReduce纳入到项目中。
好吧,闲话少说,今天要介绍的是Python函数式编程中的另外两个内建函数
map()和
reduce(),而不是Google的MapReduce。
1.map()
格式:map( func, seq1[, seq2...] )
Python函数式编程中的
map()函数是将func作用于seq中的每一个元素,并用一个列表给出返回值。如果func为None,作用同
zip()。
当seq只有一个时,将func函数作用于这个seq的每个元素上,得到一个新的seq。下图说明了只有一个seq的时候map()函数是如何工作的(本文图片来源:《Core Python Programming (2nd edition)》)。
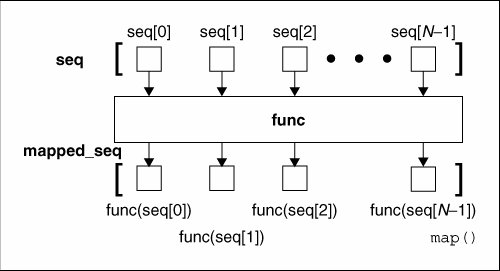
可以看出,seq中的每个元素都经过了func函数的作用,得到了func(seq
)组成的列表。
下面举一个例子进行说明。假设我们想要得到一个列表中数字%3的余数,那么可以写成下面的代码。
Python函数式编程之map使用(一个seq)
Python
# 使用map
print map( lambda x: x%3, range(6) ) # [0, 1, 2, 0, 1, 2]
#使用列表解析
print [x%3 for x in range(6)] # [0, 1, 2, 0, 1, 2]
| 1 2 3 4 5 6 | # 使用map print map( lambda x: x%3, range(6) ) # [0, 1, 2, 0, 1, 2] #使用列表解析 [x%3 for x in range(6)] # [0, 1, 2, 0, 1, 2] |
filter()一样,使用了列表解析的方法代替map执行。那么,什么时候是列表解析无法代替map的呢?
原来,当seq多于一个时,map可以并行地对每个seq执行如下图所示的过程:
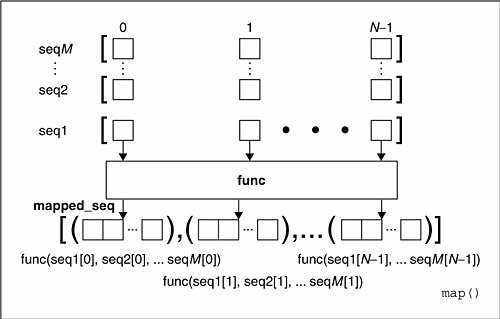
也就是说每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的积,可以想象,这是一种可能会经常出现的状况,而如果不是用map的话,就要使用一个for循环,依次对每个位置执行该函数。
Python函数式编程之map使用(多个seq)
Python
print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18]
| 1 | print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18] |
Python函数式编程之map使用(多个seq)
Python
print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)]
| 1 | print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)] |
zip()了。
Python函数式编程之map使用(func为None)
Python
print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
print zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
| 1 2 3 | print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)] zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)] |
2.reduce()
格式:reduce( func, seq[, init] )
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的式子来说明:
reduce( func, [1, 2,3] ) = func( func(1, 2), 3)
下面是reduce函数的工作过程图:
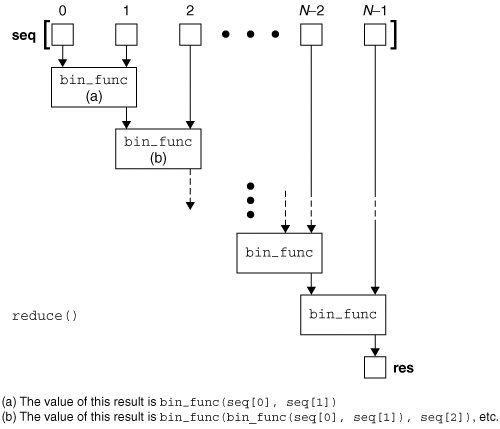
举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
Python函数式编程之reduce使用
Python
n = 5
print reduce(lambda x, y: x * y, range(1, n + 1)) # 120
| 1 2 | n = 5 print reduce(lambda x, y: x * y, range(1, n + 1)) # 120 |
Python函数式编程之reduce使用
Python
m = 2
n = 5
print reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240
| 1 2 3 | m = 2 n = 5 reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240 |
3.参考文献
[1] Lammel R. Google’s MapReduce programming model – Revisited[J]. Science of Computer Programming, 2008,70(1):208-237.[2] Hadoop[EB/OL]. http://hadoop.apache.org.
本文内容遵从CC3.0版权协议,转载请注明:转自Pythoner
本文链接地址:Python函数式编程——map()、reduce()
相关文章
Python函数式编程——匿名函数lambdaPython函数式编程——偏函数
Python函数式编程——apply()、filter()
Python标准库——collections模块的Counter类
解决matplotlib中文乱码问题(Windows)
Zemanta

相关文章推荐
- python标准库 -- 感想
- Python项目之画幅好画
- 用Python写一个无界面的2048小游戏
- Python class method
- Python【3】-字典dic和集合set
- python内存管理
- 《python3廖雪峰》正则表达式匹配Email地址练习题答案
- ubuntu14.04安装python3
- Python yield 总结
- Python 开发者在迁移到 Go(lang) 时需要知道哪些事?
- Python 开发者在迁移到 Go(lang) 时需要知道哪些事?
- Python中颜色处理
- python telnet
- leetcode 230. Kth Smallest Element in a BST-递归|非递归
- Python中与for循环相关的几个函数
- Python中的分组函数(groupby、itertools)
- 【整理】Python中实际上已经得到了正确的Unicode或某种编码的字符,但是看起来或打印出来却是乱码
- windows上安装Anaconda和python
- 使用python计算夏普比率与最大回撤和最大回撤时间的程序
- 计蒜客难题题库之一 泥塑课 python解答