利用python模拟登录
2016-05-22 20:35
656 查看
最近在学习网络爬虫,记录下详细过程以便以后查看。
利用python模拟登录,主要参考这篇文章http://blog.csdn.net/crazyuo/article/details/8662025,自己实现可以登录。
附上源码:
#encoding=utf-8
import urllib
import urllib2
import cookielib
from _LWPCookieJar import LWPCookieJar
from logging.handlers import HTTPHandler
#登录界面的主页
hosturl='http://www.renren.com'
#需要将密码和用户名等发送到的页面,需要抓包
#在firefox浏览器上登录,F12,找到POST,login,其中的请求网址即是
#而参数里有表单需要填的东西
posturl='http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2016401925736'
#生成cookie
cj=cookielib.LWPCookieJar()#LWPCookieJar返回的对象可以从硬盘加载Cookie,同时还能向硬盘读取Cookie
cookie_support=urllib2.HTTPCookieProcessor(cj)
opener=urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
#打开登录界面,获取cookie并将cookie保存下来
h=urllib2.urlopen(hosturl)
#构造头,方法和上面获取posturl方法一样
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':'http://www.renren.com/'}
#表单数据,方法同上
postdata={
'email':"*****", #自己的邮箱
'icode':"",
'origURL':"http://www.renren.com/home",
'domain':"renren.com",
'key_id':"1",
'captcha_type':"web_login",
'password':"1b2f4dcaae1b6c35ae8e248d2c4e60ea09c97a771514763146936af23a0127f8",#加密后的密码
'rkey':"d0cf42c2d3d337f9e5d14083f2d52cb2",
'f':"http%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DNuOWcFY5vnkONBdyip4Gb465jXUQpVZlEwT1gOUJ6ry%26wd%3D%26eqid%3Dbbc02beb00346b3200000005574198bf"
}
#将数据进行编码
postdata=urllib.urlencode(postdata)
#构造一个请求
request=urllib2.Request(posturl,postdata,headers)
#发送一个请求
response=urllib2.urlopen(request)
#现在可以访问需要登录才能访问的页面了
print urllib2.urlopen('http://www.renren.com').read()
在firefox浏览器上抓包,得到posturl,headers和postdata过程如下:
打开人人的登录主页,按F12开始抓包,登录人人,然后在下面找到POST,login什么的
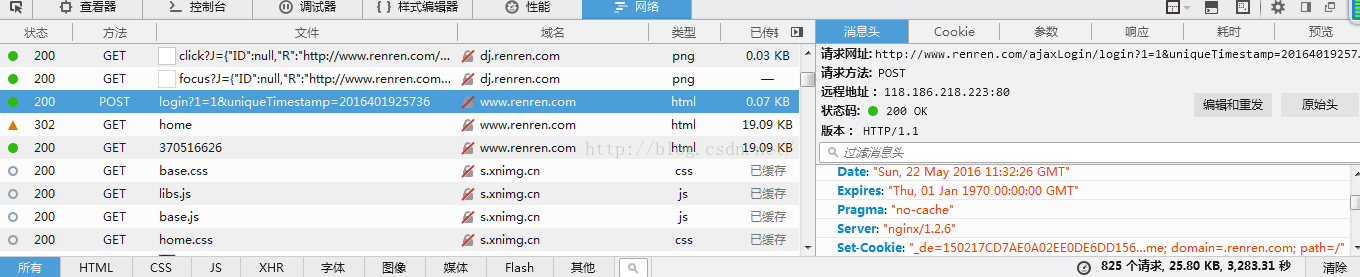
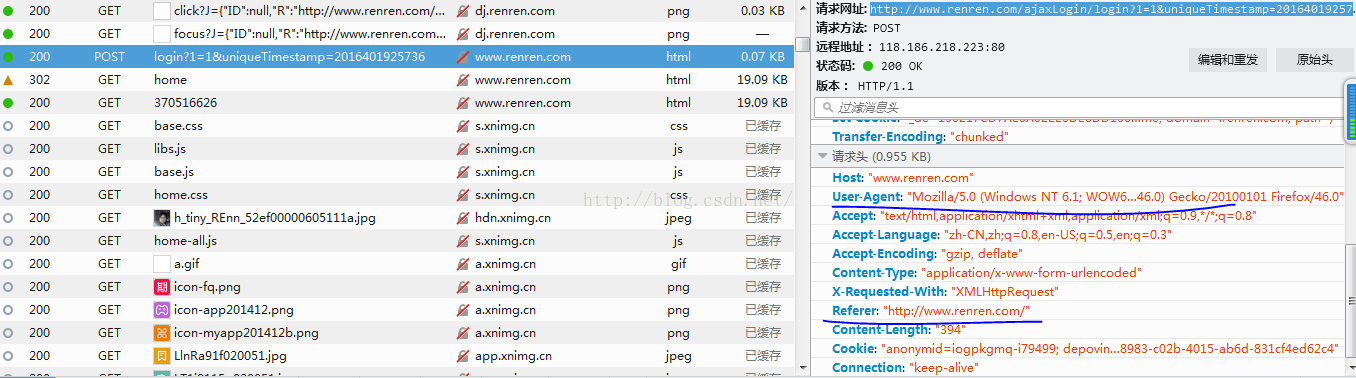
其中消息头中的请求网址就是posturl,在请求头中可以找到headers
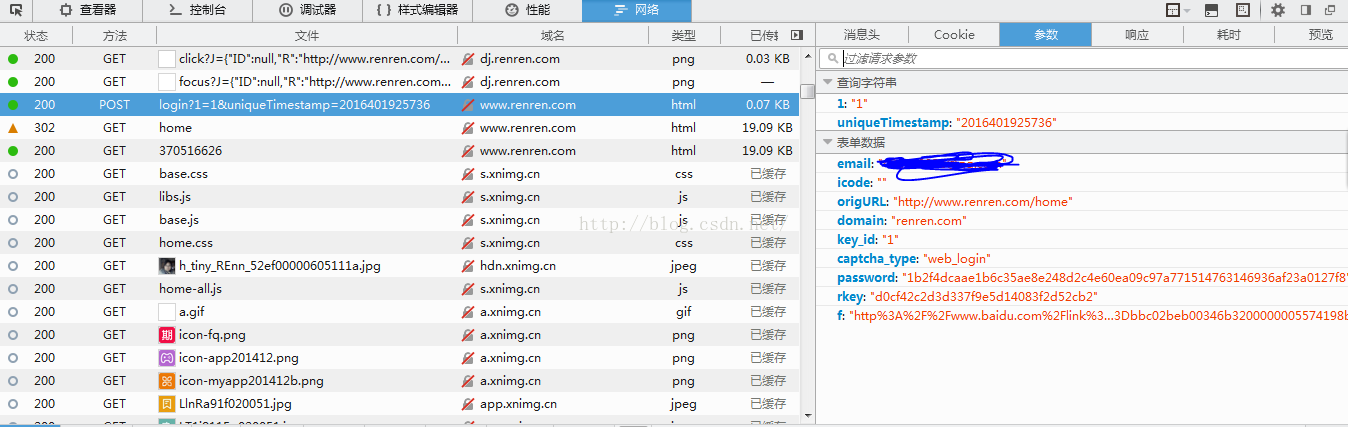
postdata在参数里
好了,差不多就这些了。
登录电驴的练习。 其中创建的cookie对象与上面有一些区别。
#encoding=utf-8
import urllib
import urllib2
import cookielib
from _LWPCookieJar import LWPCookieJar
from logging.handlers import HTTPHandler
hosturl='http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'
posturl='http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'
filename='cookie.txt'
cj=cookielib.MozillaCookieJar(filename)
cookie_support=urllib2.HTTPCookieProcessor(cj)
opener=urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
h=urllib2.urlopen(hosturl)
cj.save(ignore_discard=True, ignore_expires=True)
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':'http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'}
postdata={
'username':"",
'password':"",
'continue':"http://www.verycd.com/",
'fk':"",
'save_cookie':"1",
'login_submit':"登录"
}
postdata=urllib.urlencode(postdata)
request=urllib2.Request(posturl,postdata,headers)
response=urllib2.urlopen(request)
print urllib2.urlopen('http://www.verycd.com/').read()
利用python模拟登录,主要参考这篇文章http://blog.csdn.net/crazyuo/article/details/8662025,自己实现可以登录。
附上源码:
#encoding=utf-8
import urllib
import urllib2
import cookielib
from _LWPCookieJar import LWPCookieJar
from logging.handlers import HTTPHandler
#登录界面的主页
hosturl='http://www.renren.com'
#需要将密码和用户名等发送到的页面,需要抓包
#在firefox浏览器上登录,F12,找到POST,login,其中的请求网址即是
#而参数里有表单需要填的东西
posturl='http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2016401925736'
#生成cookie
cj=cookielib.LWPCookieJar()#LWPCookieJar返回的对象可以从硬盘加载Cookie,同时还能向硬盘读取Cookie
cookie_support=urllib2.HTTPCookieProcessor(cj)
opener=urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
#打开登录界面,获取cookie并将cookie保存下来
h=urllib2.urlopen(hosturl)
#构造头,方法和上面获取posturl方法一样
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':'http://www.renren.com/'}
#表单数据,方法同上
postdata={
'email':"*****", #自己的邮箱
'icode':"",
'origURL':"http://www.renren.com/home",
'domain':"renren.com",
'key_id':"1",
'captcha_type':"web_login",
'password':"1b2f4dcaae1b6c35ae8e248d2c4e60ea09c97a771514763146936af23a0127f8",#加密后的密码
'rkey':"d0cf42c2d3d337f9e5d14083f2d52cb2",
'f':"http%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DNuOWcFY5vnkONBdyip4Gb465jXUQpVZlEwT1gOUJ6ry%26wd%3D%26eqid%3Dbbc02beb00346b3200000005574198bf"
}
#将数据进行编码
postdata=urllib.urlencode(postdata)
#构造一个请求
request=urllib2.Request(posturl,postdata,headers)
#发送一个请求
response=urllib2.urlopen(request)
#现在可以访问需要登录才能访问的页面了
print urllib2.urlopen('http://www.renren.com').read()
在firefox浏览器上抓包,得到posturl,headers和postdata过程如下:
打开人人的登录主页,按F12开始抓包,登录人人,然后在下面找到POST,login什么的
其中消息头中的请求网址就是posturl,在请求头中可以找到headers
postdata在参数里
好了,差不多就这些了。
登录电驴的练习。 其中创建的cookie对象与上面有一些区别。
#encoding=utf-8
import urllib
import urllib2
import cookielib
from _LWPCookieJar import LWPCookieJar
from logging.handlers import HTTPHandler
hosturl='http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'
posturl='http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'
filename='cookie.txt'
cj=cookielib.MozillaCookieJar(filename)
cookie_support=urllib2.HTTPCookieProcessor(cj)
opener=urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
h=urllib2.urlopen(hosturl)
cj.save(ignore_discard=True, ignore_expires=True)
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':'http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/'}
postdata={
'username':"",
'password':"",
'continue':"http://www.verycd.com/",
'fk':"",
'save_cookie':"1",
'login_submit':"登录"
}
postdata=urllib.urlencode(postdata)
request=urllib2.Request(posturl,postdata,headers)
response=urllib2.urlopen(request)
print urllib2.urlopen('http://www.verycd.com/').read()

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- 我投了份简历,接到了十八个骚扰电话