基于keepalived 实现VIP转移,lvs,nginx的高可用
2016-05-20 14:06
766 查看
[b]转自:http://www.tuicool.com/articles/eu26Vz[/b]
[b]一、Keepalived 高可用集群的解决方案[/b]
二、VRRP的有限状态机
三、利用keepalived 实现主从VIP的切换
四、 实现在状态转变的时候自定义进行通知,
五、 实现负载均衡
六:实现nginx的高可用
一、Keepalived 高可用集群的解决方案
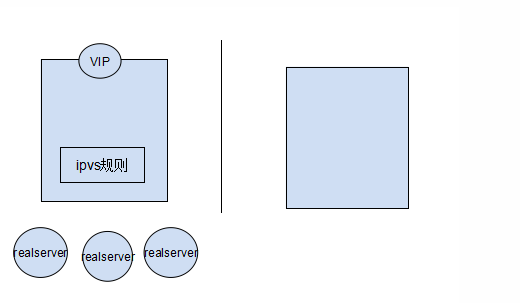
最初的诞生是为ipvs提供高可用的, 在后端的 realserver接收不到主节点的信息之后, keepalived能够自己调用ipvsadm命令生成规则,能够自动实现,将 主节点的VIP以及ipvs规则“拿过来”,应用在从节点上,继续为用户服务 。 还可以实现对后端realserver的健康状况做检测。
keepalived在一个节点上启动之后,会生成一个Master主进程,这个主进程又会生成两个子进程,分别是VRRP Stack(实现vrrp协议的) Checkers(检测ipvs后端realserver的健康状况检测)
二、VRRP的有限状态机

VRRP双方节点都启动以后,要实现状态转换的,刚开始启动的时候,初始状态都是BACKUP,而后向其它节点发送通告,以及自己的优先级信息,谁的优先级高,就转换为MASTER,否则就还是BACKUP,这时候服务就在状态为MASTER的节点上启动,为用户提供服务,如果,该节点挂掉了,则转换为BACKUP,优先级降低,另一个节点转换为MASTER,优先级上升,服务就在此节点启动,VIP,VMAC都会被转移到这个节点上,为用户提供服务,
实验环境:
虚拟主机版本:
CentOS6.4-i686
两个节点:
node1.limian.com 172.16.6.1
node2.limian.com 172.16.6.10
准备
1、节点一:
同步时间:
[root@node1 ~]# ntpdate 172.16.0.1
安装keepalived
[root@node1 ~]# yum -y install keepalived
2、节点二做同样的工作
三、利用keepalived 实现主从VIP的切换
3.1我们修改下keepalived的配置文件:
3.2全局阶段
3.3 定义 vrrp阶段
这样我们主节点的配置文件就修改好了,需要复制到从节点上,再做适当的修改就可以使用了
3.4 登录到从节点 ;
3.5然后在主节点启动服务
3.6在从节点启动服务
[root@node2 keepalived]# service keepalived start
把主节点上的服务停掉,看VIP会不会到从节点上
[root@node2 ~]# ip addr show

3.7在主节点上启动服务
注:
默认情况下ARRP工作在“抢占模式”下,如果发现一个节点的服务停止了,另一个节点会立即把VIP和VMAC“抢过来”,如果在“非抢占模式”下,无论你的优先级过高,一个节点服务停止,另一个节点也不会“抢”VIP和VMAC,除非这个节点挂了,两一个节点才会“抢”。
四、 实现在状态转变的时候自定义进行通知,
4.1这需要依赖于脚本来完成
主节点
转换状态查看是否会收到通知
说明脚本正常工作,那么去编辑配置文件
在全局阶段添加
在 vrrp阶段添加如下几行
4.2将该脚本复制到另一个节点,
并在配置文件中相应的位置添加相同内容
两个节点都重启服务
4.3让主节点变成从节点
通过监控,发现主节点立即变成从节点,并收到一封邮件
五、 实现负载均衡
5.1 编辑配置文件
5.2、在从节点上做同样的修改
5.3重启服务并用ipvsadm命令检测是否会生成规则
但是为什么没有我们定义的两个 realserver呢?那是因为没启动虚拟机呢,健康状况检测没通过,就不会显示了,我们去启动一个虚拟机,并启动服务即可。
并执行如下命令,做lvs负载均衡的DR模型
注:
1、后端的realserver的数量可以添加多台,但是需要在主节点的配置文件中给出相应的配置,并在添加的realserver上执行相关命令即可
2、尽管keepalived可以自行添加ipvs规则,实现负载均衡,但是无法实现动静分离,在生产环境中我们要根据场景选择最佳的方案。
六:实现nginx的高可用
6.1前提
两个节点上都装上nginx服务,并确保httpd没启用
# netstat -tunlp //确保80端口没占用
# service nginx start
6.2为每个节点的 nginx编辑一个页面,以便于效果更直观一些
6.3确保nginx可以正常访问

6.4然后停掉服务,
6.5同步脚本到节点2
6.6在主节点上
[b]一、Keepalived 高可用集群的解决方案[/b]
二、VRRP的有限状态机
三、利用keepalived 实现主从VIP的切换
四、 实现在状态转变的时候自定义进行通知,
五、 实现负载均衡
六:实现nginx的高可用
一、Keepalived 高可用集群的解决方案
最初的诞生是为ipvs提供高可用的, 在后端的 realserver接收不到主节点的信息之后, keepalived能够自己调用ipvsadm命令生成规则,能够自动实现,将 主节点的VIP以及ipvs规则“拿过来”,应用在从节点上,继续为用户服务 。 还可以实现对后端realserver的健康状况做检测。
keepalived在一个节点上启动之后,会生成一个Master主进程,这个主进程又会生成两个子进程,分别是VRRP Stack(实现vrrp协议的) Checkers(检测ipvs后端realserver的健康状况检测)
二、VRRP的有限状态机
VRRP双方节点都启动以后,要实现状态转换的,刚开始启动的时候,初始状态都是BACKUP,而后向其它节点发送通告,以及自己的优先级信息,谁的优先级高,就转换为MASTER,否则就还是BACKUP,这时候服务就在状态为MASTER的节点上启动,为用户提供服务,如果,该节点挂掉了,则转换为BACKUP,优先级降低,另一个节点转换为MASTER,优先级上升,服务就在此节点启动,VIP,VMAC都会被转移到这个节点上,为用户提供服务,
实验环境:
虚拟主机版本:
CentOS6.4-i686
两个节点:
node1.limian.com 172.16.6.1
node2.limian.com 172.16.6.10
准备
1、节点一:
同步时间:
[root@node1 ~]# ntpdate 172.16.0.1
安装keepalived
[root@node1 ~]# yum -y install keepalived
2、节点二做同样的工作
三、利用keepalived 实现主从VIP的切换
3.1我们修改下keepalived的配置文件:
[root@node1 ~]# cd /etc/keepalived/ [root@node1 keepalived]# cp keepalived.conf keepalived.conf.back //先给配置文件备份一下 [root@node1 keepalived]# vim keepalived.conf
3.2全局阶段
global_defs {
notification_email { //定义邮件服务的
root@localhost //定义收件人,这里改为本机,只是测试使用
}
notification_email_from kaadmin@localhost //定义发件人,
smtp_server 127.0.0.1 //定义邮件服务器,一定不能使用外部地址
smtp_connect_timeout 30 //超时时间
router_id LVS_DEVEL
}3.3 定义 vrrp阶段
vrrp_instance VI_1 { //定义虚拟路由,VI_1 为虚拟路由的标示符,自己定义名称
state MASTER //开启后,该节点的优先级比另一节点的优先级高,所以转化为MASTER状态
interface eth0 //所有的通告等信息都从eth0这个接口出去
virtual_router_id 7 //虚拟路由的ID,而且这个ID也是虚拟MAC最后一段的来源,这个ID号一般不能大于255,且这个ID一定不能有冲突
priority 100 //初始优先级
advert_int 1 //通告的个数
authentication { //认证机制
auth_type PASS //认证类型
auth_pass 1111 //密码,应该为随机的字符串
}
virtual_ipaddress { //虚拟地址,即VIP
172.16.6.100
}
}这样我们主节点的配置文件就修改好了,需要复制到从节点上,再做适当的修改就可以使用了
[root@node1 keepalived]# scp keepalived.conf 172.16.6.1:/etc/keepalived/
3.4 登录到从节点 ;
[root@node2 ~]# cd /etc/keepalived/
[root@node2 keepalived]# vim keepalived.conf
vrrp_instance VI_1 {
state BACKUP //修改从节点的状态,主节点为MASTER,从节点就为BACKUP
interface eth0
virtual_router_id 7
priority 99 //修改优先级,注意从节点的优先级一定要小于主节点
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.6.100
}
}3.5然后在主节点启动服务
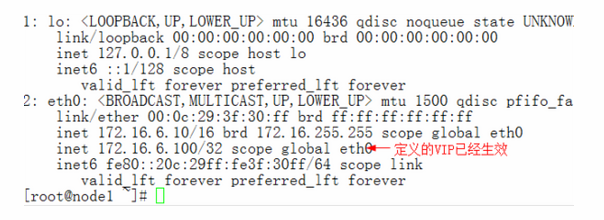
[root@node1 keepalived]# service keepalived start [root@node1 ~]# ip addr show //查看我们定义的VIP
3.6在从节点启动服务
[root@node2 keepalived]# service keepalived start
把主节点上的服务停掉,看VIP会不会到从节点上
[root@node2 ~]# ip addr show
3.7在主节点上启动服务
[root@node1 ~]# service keepalived start [root@node1 ~]# ip addr show //检测结果发现VIP转移到了主节点
注:
默认情况下ARRP工作在“抢占模式”下,如果发现一个节点的服务停止了,另一个节点会立即把VIP和VMAC“抢过来”,如果在“非抢占模式”下,无论你的优先级过高,一个节点服务停止,另一个节点也不会“抢”VIP和VMAC,除非这个节点挂了,两一个节点才会“抢”。
四、 实现在状态转变的时候自定义进行通知,
4.1这需要依赖于脚本来完成
主节点
[root@node1 ~]# cd /etc/keepalived/
[root@node1 keepalived]# vim notify.sh //编写脚本
#!/bin/bash
vip=172.16.6.100
contact='root@localhost'
thisip=`ifconfig eth0 | awk '/inet addr:/{print $2}' | awk -F: '{print $2}'`
Notify() {
mailsubject="$thisip is to bi $vip master"
mailbody="vrrp transaction, $vip floated to $thisip"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac
[root@node1 keepalived]# chmod +x notify.sh
[root@node1 keepalived]# ./notify.sh master
[root@node1 keepalived]# mail //查看有没有收到通知
Heirloom Mail version 12.4 7/29/08. Type ? for help.
"/var/spool/mail/root": 1 message 1 new
>N 1 root Wed Sep 25 14:54 18/668 "172.16.6.10 is to bi 172.16.6.100 mas"
&转换状态查看是否会收到通知
[root@node1 keepalived]# ./notify.sh backup [root@node1 keepalived]# ./notify.sh fault [root@node1 keepalived]# mail Heirloom Mail version 12.4 7/29/08. Type ? for help. "/var/spool/mail/root": 3 messages 2 new 1 root Wed Sep 25 14:54 19/679 "172.16.6.10 is to bi 172.16.6.100 mas" >N 2 root Wed Sep 25 14:57 18/668 "172.16.6.10 is to bi 172.16.6.100 mas" N 3 root Wed Sep 25 14:57 18/668 "172.16.6.10 is to bi 172.16.6.100 mas" &
说明脚本正常工作,那么去编辑配置文件
[root@node1 keepalived]# vim keepalived.conf
在全局阶段添加
vrrp_script chk_mantaince_down{ //定义可以手动控制状态的脚本
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1 //检查时间间隔
weight -2 //如果检测失败,优先级-2
}在 vrrp阶段添加如下几行
track_script { //引用定义的脚本
chk_mantaince_down
}
notify_master"/etc/keepalived/notify.sh master"
notify_backup"/etc/keepalived/notify.sh backup"
notify_fault"/etc/keepalived/notify.sh fault"4.2将该脚本复制到另一个节点,
[root@node1 keepalived]# scp notify.sh 172.16.6.1:/etc/keepalived/
并在配置文件中相应的位置添加相同内容
两个节点都重启服务
4.3让主节点变成从节点
root@node1 keepalived]# touch down
通过监控,发现主节点立即变成从节点,并收到一封邮件
[root@node1 keepalived]# tail -f /var/log/messages You have new mail in /var/spool/mail/root
五、 实现负载均衡
5.1 编辑配置文件
[root@node1 keepalived]# vim keepalived.conf
#####负载均衡阶段#################
virtual_server 172.16.6.100 80 { //指定VIP和端口
delay_loop 6 //延迟多少个周期再启动服务,做服务检测
lb_algo rr loadbalance 负载均衡调度算法
lb_kind DR 类型
nat_mask 255.255.0.0 掩码
persistence_timeout 0 持久连接时间
protocol TCP //协议
real_server 172.16.6.11 80 { //定义后端realserver的属性
weight 1
HTTP_GET { //定义检测的方法
url { //检测的URL
path /
status_code 200 //获取结果的状态码
}
connect_timeout 3 //连接超时时间
nb_get_retry 3 //尝试次数
delay_before_retry 3 //每次尝试连接的等待时间
}
}
real_server 172.16.6.12 80 { //定义后端realserver的属性
weight 1
HTTP_GET { //定义检测的方法
url { //检测的URL
path /
status_code 200 //获取结果的状态码
}
connect_timeout 3 //连接超时时间
nb_get_retry 3 //尝试次数
delay_before_retry 3 //每次尝试连接的等待时间
}
}
}5.2、在从节点上做同样的修改
5.3重启服务并用ipvsadm命令检测是否会生成规则
[root@node1 keepalived]# service keepalived restart [root@node1 keepalived]# ipvsadm -L -n IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 172.16.6.100:80 rr [root@node1 keepalived]#
但是为什么没有我们定义的两个 realserver呢?那是因为没启动虚拟机呢,健康状况检测没通过,就不会显示了,我们去启动一个虚拟机,并启动服务即可。
并执行如下命令,做lvs负载均衡的DR模型
#ifconfig lo:0 172.16.6.11 broadcast 172.16.6.11 netmask 255.255.255.255 up #route add -host 172.16.6.11 dev lo:0 #echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore #echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore #echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce #echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
注:
1、后端的realserver的数量可以添加多台,但是需要在主节点的配置文件中给出相应的配置,并在添加的realserver上执行相关命令即可
2、尽管keepalived可以自行添加ipvs规则,实现负载均衡,但是无法实现动静分离,在生产环境中我们要根据场景选择最佳的方案。
六:实现nginx的高可用
6.1前提
两个节点上都装上nginx服务,并确保httpd没启用
# netstat -tunlp //确保80端口没占用
# service nginx start
6.2为每个节点的 nginx编辑一个页面,以便于效果更直观一些
[root@node1 ~]# vim /usr/share/nginx/html/index.html //节点1 172.16.6.10 [root@node2 ~]# vim /usr/share/nginx/html/index.html //节点2 172.16.6.1
6.3确保nginx可以正常访问
6.4然后停掉服务,
[root@node1 keepalived]# vim notify.sh //修改脚本,让它可以监测nginx服务,并可以启动或关闭服务 ################## case "$1" in master) notify master /etc/rc.d/init.d/nginx start exit 0 ;; backup) notify backup /etc/rc.d/init.d/nginx stop exit 0 ;; fault) notify fault /etc/rc.d/init.d/nginx stop exit 0 ;; ######################################
6.5同步脚本到节点2
[root@node1 keepalived]# scp notify.sh 172.16.6.1:/etc/keepalived/
6.6在主节点上
[root@node1 keepalived]# touch down [root@node1 keepalived]#ss -tunl //发现80端口未被监听 [root@node1 keepalived]# rm -f down [root@node1 keepalived]#ss -tunl //发现80端口已经被监听

相关文章推荐
- D12-Nginx-利用Referer防盗链
- nginx 实现valid_referer全面解析
- nginx开启PHP错误日志
- 开启nginx目录文件列表显示功能
- jenkins 安装配置: centos-master windows/linux-slave + nginx代理 + node + job
- centos 安装配置 rabbitmq 以及nginx转发
- 使用nagios+python监控nginx进程数
- Apache和Nginx的对比
- nginx配置文件nginx.conf conf.d(一般都放这个目录下)
- Nginx架构解析
- nginx 的一些优化(突破十万并发)
- nginx 查看 并发连接数
- Nginx工作原理和优化
- Ubuntu 安装Nginx服务 并搭建文件服务器
- nginx 并发数
- linux 安装nginx
- nginx lua处理图片
- [运维-服务器 – 1A] – nginx.conf(转)
- [运维-服务器 – 2A] – nginx下绑定域名
- Linux下源码安装nginx服务器以及部分配置