JAXP对XML文档进行DOM解析实现增删改
2016-05-19 20:33
495 查看
上一节用JAXP对xml文档解析读取了其中的数据点击查看上一节内容,现在实行xml文档的增删改:
xml文档:
运行add():

运行add2():

运行addAttr():
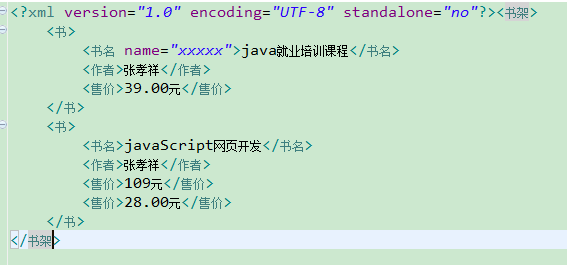
运行delete1():

运行delete2():

运行update():
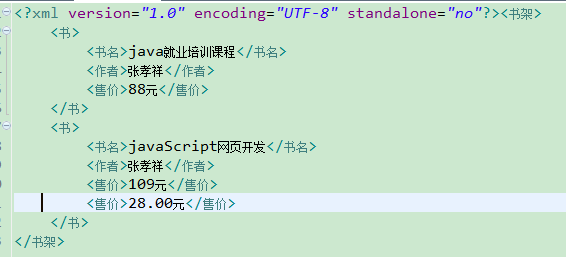
xml文档:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <书架> <书> <书名 name="xxxx">java就业培训课程</书名> <作者>张孝祥</作者> <售价>39.00元</售价> </书> <书> <书名>javaScript网页开发</书名> <作者>张孝祥</作者> <售价>109元</售价> <售价>28.00元</售价> </书> </书架>
package xml;
import java.io.FileOutputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.junit.Test;
import org.junit.experimental.theories.suppliers.TestedOn;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class Demo4 {
//向xml文档中添加节点: 在第一个书节点上添加<售价>59.00元</售价>
@Test
public void add() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
//创建节点
Element price=document.createElement("售价"); //创建一个“售价”标签
price.setTextContent("59.00元"); //节点添加内容
//把创建的节点挂到第一本书上
Element book=(Element) document.getElementsByTagName("书").item(0); //得到第一个书节点
book.appendChild(price); //挂上子节点
//注:此时内存中的对象树已经更新,但是还未把内存中更新的对象树重新写回到xml文档中,所以此时xml文档不会有任何变化
//把更新后的内存写回到xml文档
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
//向xml文档中指定位置上添加节点: 在第一个书节点上添加<售价>59.00元</售价>
@Test
public void add2() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
//创建节点
Element price=document.createElement("售价"); //创建一个“售价”标签
price.setTextContent("59.00元"); //节点添加内容
//得到参考节点
Element refNode=(Element) document.getElementsByTagName("售价").item(0); //得到第一个书标签里的售价标签
//得到要插入子元素的几点
Element book=(Element) document.getElementsByTagName("书").item(0); //得到第一个书节点
//往book节点指定位置插入子节点
book.insertBefore(price, refNode); //在参考节点refNode之前插入price
//注:此时内存中的对象树已经更新,但是还未把内存中更新的对象树重新写回到xml文档中,所以此时xml文档不会有任何变化
//把更新后的内存写回到xml文档
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
//向xml文档节点上添加属性: <书名>java就业培训课程</书名>上添加name="xxxxx"属性
@Test
public void addAttr() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
Element bookname=(Element) document.getElementsByTagName("书名").item(0); //得到"书名"这个节点
bookname.setAttribute("name", "xxxxx");
//把更新后的内存写回到xml文档
d8dd
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
@Test
public void delete1() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
//得到要删除的节点
Element e=(Element) document.getElementsByTagName("售价").item(0);
//得到要删除的节点的爸爸
Element book=(Element) document.getElementsByTagName("书").item(0);
//爸爸删除子节点
book.removeChild(e);
//把更新后的内存写回到xml文档
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
//删除整个xml文档
@Test
public void delete2() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
//得到要删除的节点
Element e=(Element) document.getElementsByTagName("售价").item(0);
// e.getParentNode().removeChild(e); //得到e的父节点,再调用父节点删除子节点的方法
// e.getParentNode().getParentNode().removeChild(e.getParentNode()); //得到爷爷,来删除爸爸
e.getParentNode().getParentNode().getParentNode().removeChild(e.getParentNode().getParentNode());
//把更新后的内存写回到xml文档
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
//更新售价
@Test
public void update() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //创建一个工厂
DocumentBuilder builder=factory.newDocumentBuilder(); //newDocumentBuilder()返回dom解析器,得到解析器
Document document= builder.parse("src/xml/book.xml"); //解析文档,拿到代表文档的document
Element e=(Element) document.getElementsByTagName("售价").item(0);
e.setTextContent("88元");
//把更新后的内存写回到xml文档
TransformerFactory tffactory=TransformerFactory.newInstance(); //得到一个工厂
Transformer tf=tffactory.newTransformer(); //拿到转换器
//调用转换器的转换方法,将内存中的document转到文档中,先将dom变成source
tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/xml/book.xml")));
}
}运行add():
运行add2():
运行addAttr():
运行delete1():
运行delete2():
运行update():

相关文章推荐
- XML 与 JSON 优劣对比
- As3.0 xml + Loader应用代码
- 网马生成器 MS Internet Explorer XML Parsing Buffer Overflow Exploit (vista) 0day
- ext读取两种结构的xml的代码
- 实例解析Ruby程序中调用REXML来解析XML格式数据的用法
- Ruby中XML格式数据处理库REXML的使用方法指南
- C#针对xml基本操作及保存配置文件应用实例
- Ruby使用REXML库来解析xml格式数据的方法
- Ruby程序中创建和解析XML文件的方法
- Ruby的XML格式数据解析库Nokogiri的使用进阶
- asp下查询xml的实现代码
- sqlserver FOR XML PATH 语句的应用
- 使用sp_xml_preparedocument处理XML文档的方法
- EBS xml publisher中文乱码问题及解决办法
- C#中的Linq to Xml详解
- C#操作XML文件实例汇总
- SQL Server中的XML数据进行insert、update、delete
- Ruby中使用Nokogiri包来操作XML格式数据的教程
- C#实现将文件转换为XML的方法