使用 Spark Streaming 检测关键词
2016-05-16 10:55
337 查看
许多公司使用 Apache Hadoop 等分布式文件系统来存储和分析数据。借助脱机 Hadoop 的流式传输分析,您可存储大量的大数据并实时分析它们。本文展示了一个使用 Spark Streaming 实现实时关键词检测的例子。
Spark Streaming 是 Spark API 的一个扩展,它支持对实时数据流执行可扩展的、容错的处理。Spark Streaming 拥有丰富的适配器,允许应用程序开发人员对各种数据源读写数据,包括 Hadoop 分布式文件系统 (HDFS)、Kafka、Twitter 等。
前提条件
必备软件:IBM InfoSphere® BigInsights 4.0 或更高版本和 Apache Maven。
必备知识:中级 Java™ 开发技能,初步了解 Hadoop 和 Spark。
解决方案概述
Spark Streaming 应用程序由一个或多个互联的、离散化的流 (DStream) 组成。每个 DStream 由一系列弹性分布式数据集 (RDD,Resilient Distributed Dataset) 组成,这些数据集是不可变的分布式数据集的抽象。Spark 支持不同的应用程序开发语言,包括 Java、Scala 和 Python。对于本文,我们将使用 Java 语言逐步展示如何开发关键词检测应用程序。
图 1 显示了这个关键词检测应用程序的总体视图。
图 1. 关键词检测应用程序的结构图
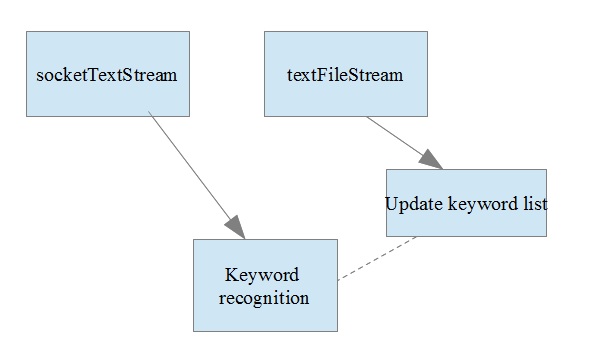
解释图 1 中的组件
SocketTextStream 允许您绑定并监听一个传输控制协议 (TCP) 套接字上的消息。SocketTextStream 的输出被提供给一个自定义流,后者使用当前关键词列表来查找相匹配的标记。
TextFileStream 用于监视 Hadoop 目录。只要它检测到一个新文件,就会读取该文件并将其转换为 DStream。使用 TextFileStream 读取的值和一个自定义逻辑来更新内部关键词列表。
关键词检测逻辑使用更新后的关键词列表,所以该图使用虚线来表示此关系。
每个组件的实现细节
每个 Spark Streaming 应用程序首先都需要一个流式处理上下文,如下面的代码段所示。“上下文” 要求您传递一个持续时间参数,该参数定义一个批次。
[Java] 纯文本查看 复制代码
?
socketTextStream 绑定到一个指定的主机接口和给定的端口号,并生成 DStream。
[Java] 纯文本查看 复制代码
?
textFileStream 使用 textFile 从 Hadoop 读取并行关键词字典文件。处理该文件后,会更新内部列表中的关键词。
[Java] 纯文本查看 复制代码
?
从 SocketStream 读取的 DStream 用于同关键词列表进行对比,如以下代码所示。使用命令 wordPresent.print(); 时,结果会显示在控制台上。
[Java] 纯文本查看 复制代码
?
下面的清单给出了本文中所用示例的完整代码。
[Java] 纯文本查看 复制代码
?
编译并启动程序
对于本文中的示例,我们使用 Maven 来安装和构建应用程序。如果使用 Maven,请确保在 pom.xml 中添加了合适的依赖项。这些依赖项主要是 spark-core 和 spark-streaming 库。
以下代码给出了我们应用程序中使用的 pom 依赖项代码段:
[Plain Text] 纯文本查看 复制代码
?
编译应用程序并创建 jar 文件后,使用下面的命令将应用程序提交到 Spark 调度程序:
[Shell] 纯文本查看 复制代码
?
因为 Spark 实例在单个具有 4 个核心的单个主机上运行,所以我们为 –master 参数使用 local[4] 值。我们的应用程序接受两个参数:主机名和端口。
应用程序假设有一个服务器进程在端口 9212 上运行并发布数据。为了在测试环境中模拟一个服务器,我们使用 nc (netcat) Linux 命令:nc -l 9212。
nc 命令绑定到 9212。我们传入终端中的任何输入内容都会转发到所有正在监听端口 9212 的客户端。
所有方面都正确设置后,所提交的作业会开始运行并监听端口 9212。您应在终端上得到以下确认消息:
[Plain Text] 纯文本查看 复制代码
?
现在,让我们更新该程序使用的内部字典。第 1.2 节中的代码可监听 Hadoop 目录 /tmp/Streamtest 中的更改事件。如果尚未创建该目录,请首先创建它,然后使用下面给出的命令上传关键词文件:
[Shell] 纯文本查看 复制代码
?
检测到一个新文件时,会执行后续的 RDD。
[Plain Text] 纯文本查看 复制代码
?
其中一个关键词是 "risk"。现在我提交 nc 中的关键词,如下面的清单所示。
[Shell] 纯文本查看 复制代码
?
然后,Spark 会检测到该关键词并在控制台上标记为 true。
[Plain Text] 纯文本查看 复制代码
?
未来增强
您可进一步增强此应用程序,从而处理完整的字符串,而不是单个标记。
您可将关键词检测状态写入到一个文件中,或者写入到一个 UI 呈现服务的端口。
异常条件
如果出现 "connection refused error",可能是因为:
HDFS 和 Yet another resource negotiator (YARN) 未运行
服务器进程未在来源端口上运行。在我们的例子中,来源端口为 9121。
Spark Streaming 是 Spark API 的一个扩展,它支持对实时数据流执行可扩展的、容错的处理。Spark Streaming 拥有丰富的适配器,允许应用程序开发人员对各种数据源读写数据,包括 Hadoop 分布式文件系统 (HDFS)、Kafka、Twitter 等。
前提条件
必备软件:IBM InfoSphere® BigInsights 4.0 或更高版本和 Apache Maven。
必备知识:中级 Java™ 开发技能,初步了解 Hadoop 和 Spark。
解决方案概述
Spark Streaming 应用程序由一个或多个互联的、离散化的流 (DStream) 组成。每个 DStream 由一系列弹性分布式数据集 (RDD,Resilient Distributed Dataset) 组成,这些数据集是不可变的分布式数据集的抽象。Spark 支持不同的应用程序开发语言,包括 Java、Scala 和 Python。对于本文,我们将使用 Java 语言逐步展示如何开发关键词检测应用程序。
图 1 显示了这个关键词检测应用程序的总体视图。
图 1. 关键词检测应用程序的结构图
解释图 1 中的组件
SocketTextStream 允许您绑定并监听一个传输控制协议 (TCP) 套接字上的消息。SocketTextStream 的输出被提供给一个自定义流,后者使用当前关键词列表来查找相匹配的标记。
TextFileStream 用于监视 Hadoop 目录。只要它检测到一个新文件,就会读取该文件并将其转换为 DStream。使用 TextFileStream 读取的值和一个自定义逻辑来更新内部关键词列表。
关键词检测逻辑使用更新后的关键词列表,所以该图使用虚线来表示此关系。
每个组件的实现细节
每个 Spark Streaming 应用程序首先都需要一个流式处理上下文,如下面的代码段所示。“上下文” 要求您传递一个持续时间参数,该参数定义一个批次。
[Java] 纯文本查看 复制代码
?
[Java] 纯文本查看 复制代码
?
[Java] 纯文本查看 复制代码
?
[Java] 纯文本查看 复制代码
?
[Java] 纯文本查看 复制代码
?
对于本文中的示例,我们使用 Maven 来安装和构建应用程序。如果使用 Maven,请确保在 pom.xml 中添加了合适的依赖项。这些依赖项主要是 spark-core 和 spark-streaming 库。
以下代码给出了我们应用程序中使用的 pom 依赖项代码段:
[Plain Text] 纯文本查看 复制代码
?
[Shell] 纯文本查看 复制代码
?
应用程序假设有一个服务器进程在端口 9212 上运行并发布数据。为了在测试环境中模拟一个服务器,我们使用 nc (netcat) Linux 命令:nc -l 9212。
nc 命令绑定到 9212。我们传入终端中的任何输入内容都会转发到所有正在监听端口 9212 的客户端。
所有方面都正确设置后,所提交的作业会开始运行并监听端口 9212。您应在终端上得到以下确认消息:
[Plain Text] 纯文本查看 复制代码
?
[Shell] 纯文本查看 复制代码
?
[Plain Text] 纯文本查看 复制代码
?
[Shell] 纯文本查看 复制代码
?
[Plain Text] 纯文本查看 复制代码
?
您可进一步增强此应用程序,从而处理完整的字符串,而不是单个标记。
您可将关键词检测状态写入到一个文件中,或者写入到一个 UI 呈现服务的端口。
异常条件
如果出现 "connection refused error",可能是因为:
HDFS 和 Yet another resource negotiator (YARN) 未运行
服务器进程未在来源端口上运行。在我们的例子中,来源端口为 9121。

相关文章推荐
- WebStrom中的一些技巧和用法
- 线程通讯-传统方式
- 第二章 Stream API
- ym—— Android网络框架Volley(体验篇)
- Spring AOP @AspectJ 入门基础
- The golden ratio: 1.618
- [LeetCode] Flatten Nested List Iterator
- Spark批量写数据入HBase
- POJ-1151-Atlantis-求矩形面积并(线段树+扫描线)
- nodejs+mysql+css项目1
- Android中Fragment切换时重叠透明问题总结
- 百度之星2016资格赛之部分题解
- Oracle Sequence创建与使用
- WINAPI *** _in_ and _out_ and _in_opt_
- GEOSQL存储机制导致的效率问题
- Java源码分析之LinkedList
- java 泛型详解
- HDU 1147 Pick-up sticks(线段相交)
- [mjpeg @ 0x27ee9e0] buffer smaller than minimum size
- 解决魅族手机listview等下拉出现hold字样的问题