Python 简介和入门
2016-05-12 10:18
459 查看
1.Python简介
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。最新的TIOBE排行榜,Python赶超PHP占据第五, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。

由上图可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!!!
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
目前Python主要应用领域:
云计算: 云计算最火的语言, 典型应用OpenStack
WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
系统运维: 运维人员必备语言
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython,TkInter
Python在一些公司的应用:
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
CIA: 美国中情局网站就是用Python开发的
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
YouTube:世界上最大的视频网站YouTube就是用Python开发的
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发的
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
为什么是Python而不是其他语言?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python 和 C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
Python的种类
Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。
Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。
IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似)
PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。
RubyPython、Brython ...
2.Python发展史
1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
Granddaddy of Python web frameworks, Zope 1 was released in 1999
Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
Python 2.5 - September 19, 2006
Python 2.6 - October 1, 2008
Python 2.7 - July 3, 2010
In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
Python 3.0 - December 3, 2008
Python 3.1 - June 27, 2009
Python 3.2 - February 20, 2011
Python 3.3 - September 29, 2012
Python 3.4 - March 16, 2014
Python 3.5 - September 13, 2015
3.python简单应用
打印输出 print
python2* 支持 print print()两种形式python3* 只能用print()形式
#!/usr/bin/env python # -*- coding: UTF-8 -*- #pyversion:python3.5 #owner:fuzj
name = input("your name: ")
age = int(input("your age: "))
job = input("your job: ")
print("name:" ,name,"age:",age,"job:" , job)
msg='''
Information of %s
name: %s
age: %d
job: %s''' % (name,name,age,job)
print(msg)
#直接打印
print('''
name: {0}
age: {1}
job: {2}
'''.format(name,age,job))
效果:
your name: fuzj
your age: 24
your job: Linux
name: fuzj age: 24 job: Linux
Information of fuzj
name: fuzj
age: 24
job: Linux
name: fuzj
age: 24
job: Linux用户输入:input / raw_input
input
python2* 会把用户的输入的字符串当作变量处理, python3* 会把用户的输入当作普通字符串
raw_input
只适合python2* 把用户的输入当作普通字符串
Python 2.7.10 (default, Jul 14 2015, 19:46:27)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> rs = raw_input("Please Input: ")
Please Input: fuzj
>>> print rs
fuzj
>>> print type(rs)
<type 'str'>
>>> rs = input("Please Input: ") #输入报错,因为找不到asd这个变量
Please Input: asd
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'asd' is not defined
>>> name = "asd" #先定义好name变量。下面再直接引用
>>> rs = input("Please Input: ")
Please Input: name
>>> print rs
asd
>>> print type(rs)
<type 'str'>Python 3.5.1 (v3.5.1:37a07cee5969, Dec 5 2015, 21:12:44)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> rs = raw_input("Please Input: ") #这个内置函数已没有
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'raw_input' is not defined
>>> rs = input("Please Input: ")
Please Input: asd
>>> print(rs)
asd
>>> name = "asd"
>>> rs = input("Please Input: ")
Please Input: name
>>> print(rs)
name用户输入账户密码程序
#!/usr/bin/env python # -*- coding: UTF-8 -*- #pyversion:python3.5 #owner:fuzj
info = {"fuzj":"123123","jeck":"123123"}
user = input("Username: ")
passwd = input("Password: ")
if user in info.keys() and passwd == info[user]:
print("Username is correct...")
print("Welcome to Login....")
else:
print("Username or Password is invalid...")
效果:
python3 login.py
Username: fuzj
Password: 123123
Username is correct...
Welcome to Login....
python3 login.py
Username: fuzj
Password: 454545
Username or Password is invalid...
还可以输入时隐藏密码: 使用getpass模块
#!/usr/bin/env python # -*- coding: UTF-8 -*- #pyversion:python3.5 #owner:fuzj
import getpass
info = {"fuzj":"123123","jeck":"123123"}
user = input("Username: ")
passwd = getpass.getpass("Password: ")
if user in info.keys() and passwd == info[user]:
print("Username is correct...")
print("Welcome to Login....")
else:
print("Username or Password is invalid...")
字符编码
ascii-->unicode-->utf-8python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。

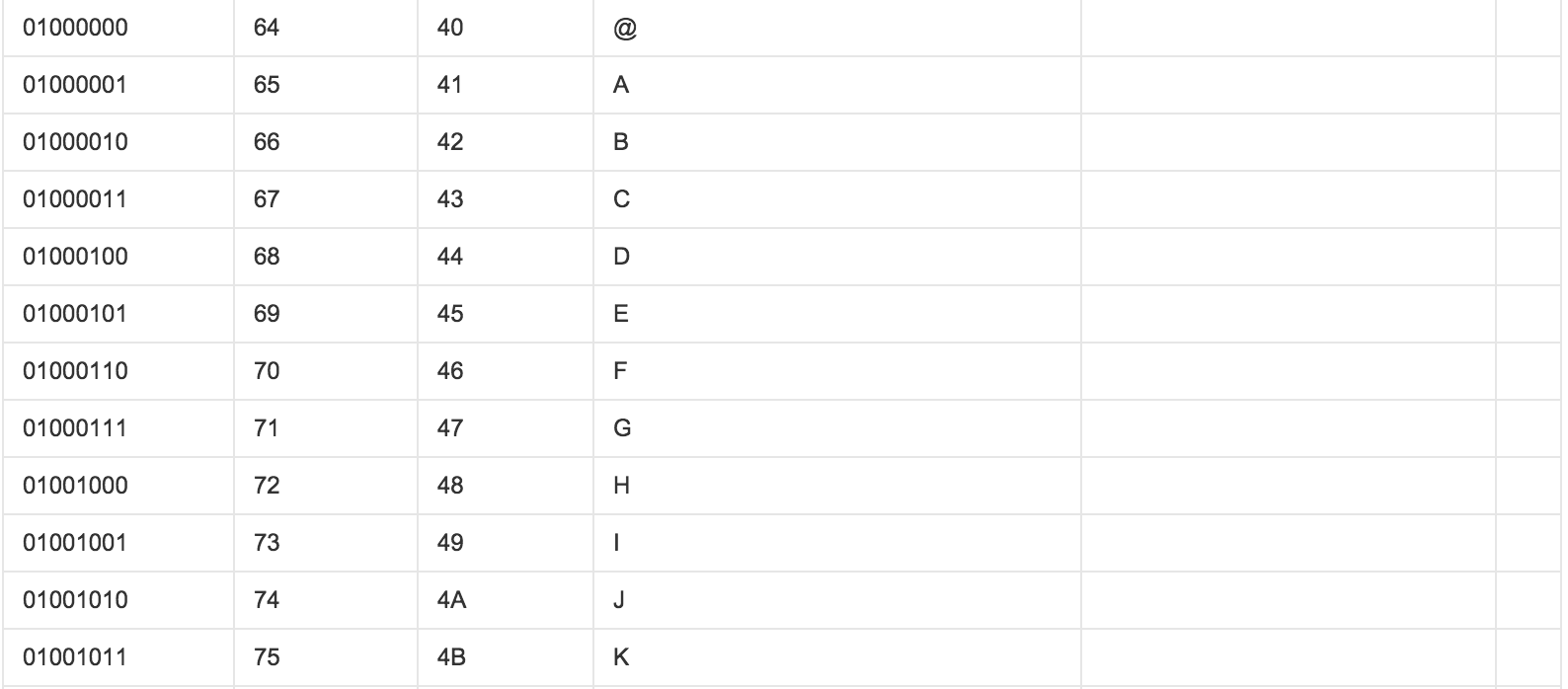
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码,python2* 默认使用ascii 编码,而python3* 默认使用unicode编码
如,在python2 里不声明字符编码的话,输出中文就会报错
#!/usr/bin/env python print "北京欢迎你" 效果: File "test.py", line 3 SyntaxError: Non-ASCII character '\xe5' in file test.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
声明字符编码之后,即可正常显示
#!/usr/bin/env python # -*- coding: UTF-8 -*- print "北京欢迎你" 效果: 北京欢迎你
python3里不需要声明,默认使用utf-8
注释
当行注视:# 被注释内容多行注释:""" 被注释内容 """
编程规范:
缩进统一
同一级别的代码必须一致!(并且建议所有级别的代码的缩进建议是相同的--必须,开发规范里建议4个空格)建议不要用table因为如果想把代码在windows上运行,linux和windows的table的定义不同!!!!
好的编辑器能提高开发代码的效率!
所有python,第一行一定要顶到行头! 同一级别的新的都要顶到行头。
变量命名规则:
标识符的第一个字符必须是字母表中的字母(大写或小写)或者一个下划线(‘ _ ’)
标识符名称的其他部分可以由字母(大写或小写)、下划线(‘ _ ’)或数字(0-9)组成。
有效 标识符名称的例子有i、__my_name、name_23和a1b2_c3。
无效 标识符名称的例子有2things、this is spaced out和my-name。
标识符名称是对大小写敏感的。例如,myname和myName不是一个标识符。注意前者中的小写n和后者中的大写N
常量:数值不变的
变量:数值会变动的量
在python中没有常量的,所有的数值都可以改变,但是他依然有个常量的概念,但是是人为的你不去改变他,定义一个常量应该用大写的形式。
AGE = 25 这个就是常量,他是大写的!是约定俗成的。但是他是可以改的!
name = 'fuzj' 这个是变量
##这里需要注意下,设置变量的时候不能设置python自带的内置方法比如type
以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
4. pyc是个什么鬼?
Python是一门解释型语言?我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
pyc文件在py2和py3的区别
python 字节码文件
python3 会创建一个__pycache__目录,存放
python2 在本地生成一个pyc文件
手动执行不能生成pyc文件,只有该py文件被其他py文件调用时,才会生成
而且执行前会比较py和pyc 文件的时间戳,如果不一样则重新编译

相关文章推荐
- Caffe错误boost::python::register_ptr_to_python<boost::shared_ptr<Blob<Dtype> > >();
- 当我学完Python我学了些什么
- python导入自定义模块
- python的tab自动补全
- jieba中文分词(python)
- Michael的Python笔记(一)
- Python基础总结
- Python下载指定页面上图片的方法
- Python基于二分查找实现求整数平方根的方法
- python二分查找算法的递归实现方法
- Python数据类型详解(四)字典:dict
- python编码
- Python基础1
- Python 浮点数运算
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器库
- python lxf
- Caffe搭建:Ubuntu14.04 + CUDA7.5 + opencv3.1+python3.5
- Python爬虫:一些常用的爬虫技巧总结
- Python数据类型详解(四)字典:dict
- python二分查找算法的递归实现方法