一致性hash的由来和原理
2016-05-10 14:52
453 查看
http://blog.codinglabs.org/articles/consistent-hashing.html
在分布式缓存系统中, 如何把数据映射到不同的缓存服务器上,一般会采用hash算法,如共有3台缓存服务器时, h= Hash(key)%3, 这种hash算法的扩展性和容错性不好,当业务增长需要加入新的缓存服务器或者由于某台缓存服务器出现故障,无法使用时,hash的计算将变为:h = Hash(key)%n ,这时,大量的访问将会因为缓存失效,而直接请求数据库,造成数据的负担。
一致性hash的提出即为解决这样的情况。
一致性hash将整个hash值空间看作一个环形结构,如图所示,假设hash值空间为32位整数。
按照顺时针排列,0和2^32-1 重合。
然后将三台缓存服务器映射到换上,映射的关键字可以选用机器ip或者机器名,得到下图:
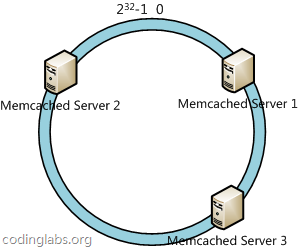
然后,将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。如下图所示:
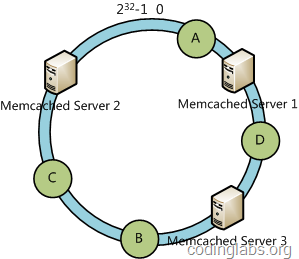
其中,A 映射到server1 上,D映射到server3 上,B和C 映射到server2 上。
假设有新的机器server4加入缓存集群中,计算server4的hash值,并映射到环中。如下图:
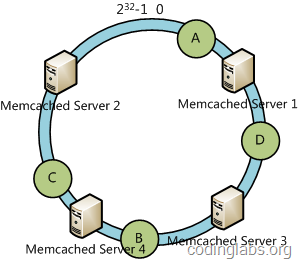
这时,只需改变B的映射关系到server4中即可,其它的都不发生改变。
同理,当从集群中移除某台机器时,只需改变该机器与其逆时针方向上前一个机器之间的数据映射即可。无需对所有数据重新映射。
以上就是一致性hash算法的基础原理。
在分布式缓存系统中, 如何把数据映射到不同的缓存服务器上,一般会采用hash算法,如共有3台缓存服务器时, h= Hash(key)%3, 这种hash算法的扩展性和容错性不好,当业务增长需要加入新的缓存服务器或者由于某台缓存服务器出现故障,无法使用时,hash的计算将变为:h = Hash(key)%n ,这时,大量的访问将会因为缓存失效,而直接请求数据库,造成数据的负担。
一致性hash的提出即为解决这样的情况。
一致性hash将整个hash值空间看作一个环形结构,如图所示,假设hash值空间为32位整数。
按照顺时针排列,0和2^32-1 重合。
然后将三台缓存服务器映射到换上,映射的关键字可以选用机器ip或者机器名,得到下图:
然后,将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。如下图所示:
其中,A 映射到server1 上,D映射到server3 上,B和C 映射到server2 上。
假设有新的机器server4加入缓存集群中,计算server4的hash值,并映射到环中。如下图:
这时,只需改变B的映射关系到server4中即可,其它的都不发生改变。
同理,当从集群中移除某台机器时,只需改变该机器与其逆时针方向上前一个机器之间的数据映射即可。无需对所有数据重新映射。
以上就是一致性hash算法的基础原理。

相关文章推荐
- 最简化模型2——css3分阶段动画效果(经过实测)之转动的div
- 欢迎使用CSDN-markdown编辑器
- PHP Warning: file_get_contents failed to open stream解决办法
- Git 基础 - 获取 Git 仓库
- 开放寻址法解决散列冲突
- 网上收集推荐书籍
- interface,abstract class,abstract interface Java中的接口,抽象类和抽象接口的异同
- 第10、11周-阅读程序(5)d
- IOCP原理
- 键值监听---KVO
- 大型网站技术架构 读书笔记2 大型网站核心架构要素
- java内存模型
- C语言课程设计第三节课作业刘子威
- 大型网站技术架构 读书笔记2 大型网站核心架构要素
- split
- Android 手动显示和隐藏软键盘
- UITextView
- 关于C++和Objective-C混编
- 深入分析 Java 中的中文编码问题
- THINKPHP添加不能为空