hive1.2.1源码导入eclipse
2016-05-10 09:59
155 查看
http://www.aboutyun.com/thread-18338-1-1.html
软件版本:
hive1.2.1 ,eclipse4.5,maven3.2 ,JDK1.7
软件准备:
hive:

环境准备:
(1). 安装好的Hadoop集群(伪分布式亦可);
(2) linux 下maven环境;(这里需要说下,maven编译hive,在windows下是不通的,因为里面需要bash的支持,所以直接使用linux编译hive就好)
0. 编译前,建议把maven的local_reposity 配置下,同时配置源如下(开源中国的maven源,相对国外的源较快):
[Java] 纯文本查看 复制代码
?
1. 编译Hive,下载hive1.2.1的源码,并解压到linux某目录,按照下面的命令进行编译(进入hive源码解压后路径):
(1)mvn clean install -DskipTests -Phadoop-2
[Java] 纯文本查看 复制代码
?
(2)清空相关输出:mvn eclipse:clean
(3)编译成eclipse工程:
mvn eclipse:eclipse -DdownloadSources -DdownloadJavadocs -Phadoop-2
[Java] 纯文本查看 复制代码
?
这个过程会比较慢;编译后,文件大小大概有:391M左右
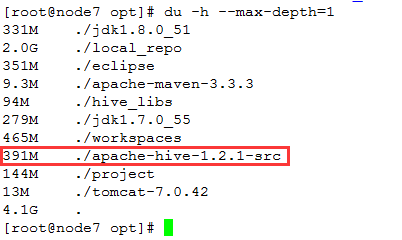
2. 编译后工程导入eclipse中
这里导入需要分为两种情况,分为导入windows下的eclipse和导入linux下的eclipse中;(因为一般使用机器都是windows的,所以如果可以使用windows,则最好)
2.1 工程导入windows的eclipse中;
打开eclipse,右键-> Import ,选择编译后的文件夹(这里需要把编译后的文件下载到windows上);即可看到如下的界面:
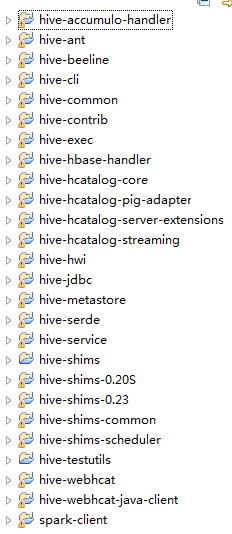
当然,这里会有些错误,比如jdk/tool.jar找不到等等,这个是因为编译的jdk和windows的jdk不一样,调整下即可。
(1)运行 hive-cli 工程的CliDriver(当然,要先启动hive相关进行,hive --service metastore & ; hive --service hiveserver2 &)
运行后会直接报错,说 driver “hive-site.xml ”not in Classpath 什么的错误,修改方法:
打开hive-common工程的本地目录的target/test-classes路径

修改里面的core-site.xml 以及hive-site.xml ,这里面的配置就参考hadoop集群以及hive的配置即可
然后再次运行CliDriver,发现报下面的错误:
[Plain Text] 纯文本查看 复制代码
?
这个是版本不匹配的错误,通过打印java的classpath,发现hadoop1的jar包在hadoop2的jar包前面
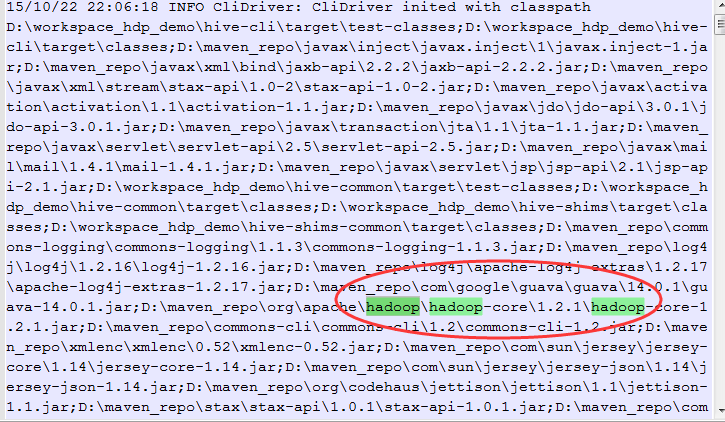
这样子肯定是有 问题的,集群都使用的是hadoop2的版本,但是代码却用的hadoop1,这样报这个错就没啥奇怪的了。那问题是出在了哪呢?
通过查看hive-shims-common工程,发现其工程的依赖只有hadoop1,没有hadoop2,而hive-cli工程也是依赖hive-shims-common工程,这也就解释了为什么Java的classpath里面hadoop1的jar包在hadoop2前面了。
此路不通!
(2)运行hive-beeline工程的BeeLine
直接运行,进入beeline交互式命令终端,如下图:

发现是可以连接hive的,比如mr查询:
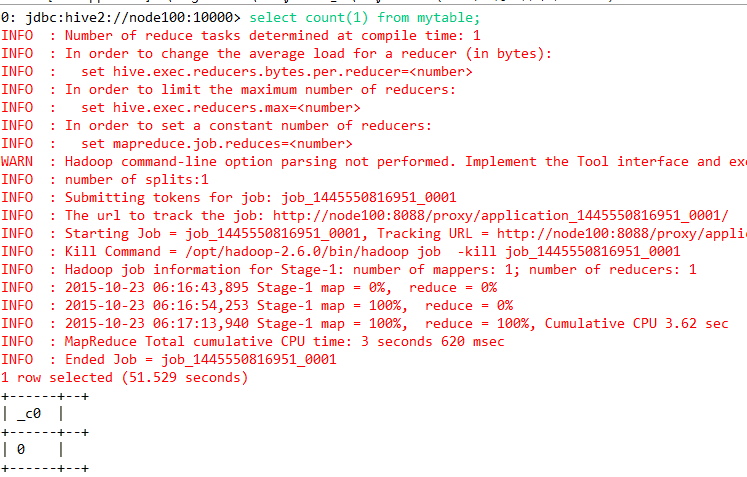
但是这个不可以调试,即使用debug模式,仍然不能调试。
所以对于阅读源码,查看调用关系来说这种模式也不是很好。
2.2 导入到linux的eclipse工程
此导入和windows不无差别。
3. 直接新建工程,使用编译后的hive jar包(此处的jar包不是指自己编译的,而是官网直接提供的),就apache-hive-1.2.1-bin.tar.gz文件。
3.1 在windows的eclipse中新建hive工程
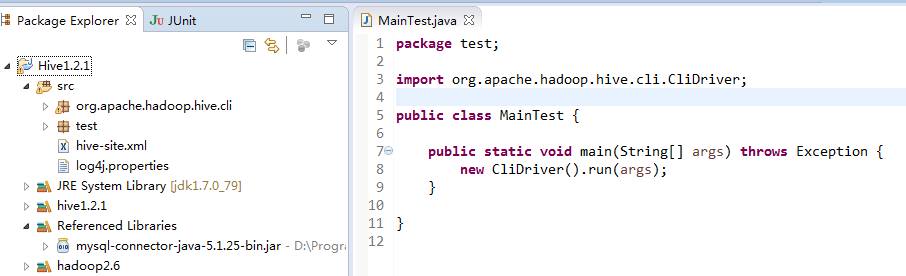
同时新建一个类,如上图所示。
这里还需要注意:
a. 引入编译后的hive的lib包的所有jar包;
b. 引入MySQL的连接jar包;
c. 引入hadoop的相关jar包
(1)写一个测试程序,调用CliDriver,出现下面的错误:
[Java] 纯文本查看 复制代码
?
通过跟踪排查,发现是windows中的hadoop没有配置winutils.exe 所致也就是最开始的错误:
[AppleScript] 纯文本查看 复制代码
?
(如果只是windows提交mr任务,这个没有配置,也是可以的,但是在hive源码里面有一个检查,如果是windows提交查询的话,需要检查,没有就会报空指针异常);这个错误可以google之来修改,这里不说,下面也就没有再在这条路下面走了。
(2)写一个调用程序,运行BeeLine,这个没有测试。
3.2 linux的eclipse新建hive工程:
建立的工程和windows并无二致,如下:
同样编写程序调用CliDriver,Debug运行,如下所示(需要注意我在这里并没有配置hadoop相关目录):
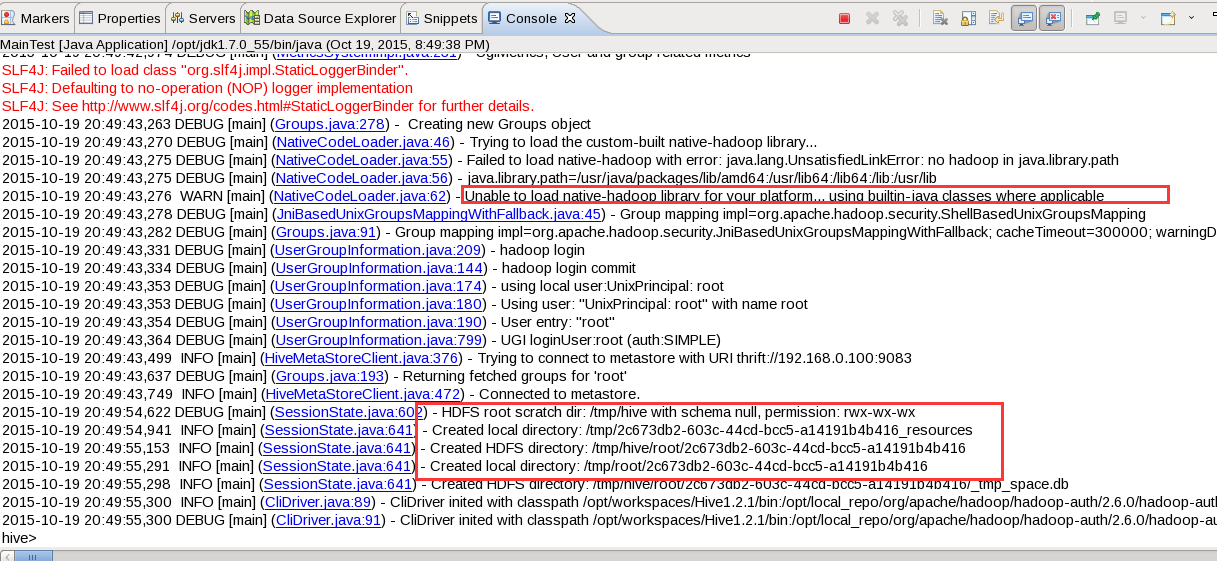
做一个查询,看是否可以启动debug模式:
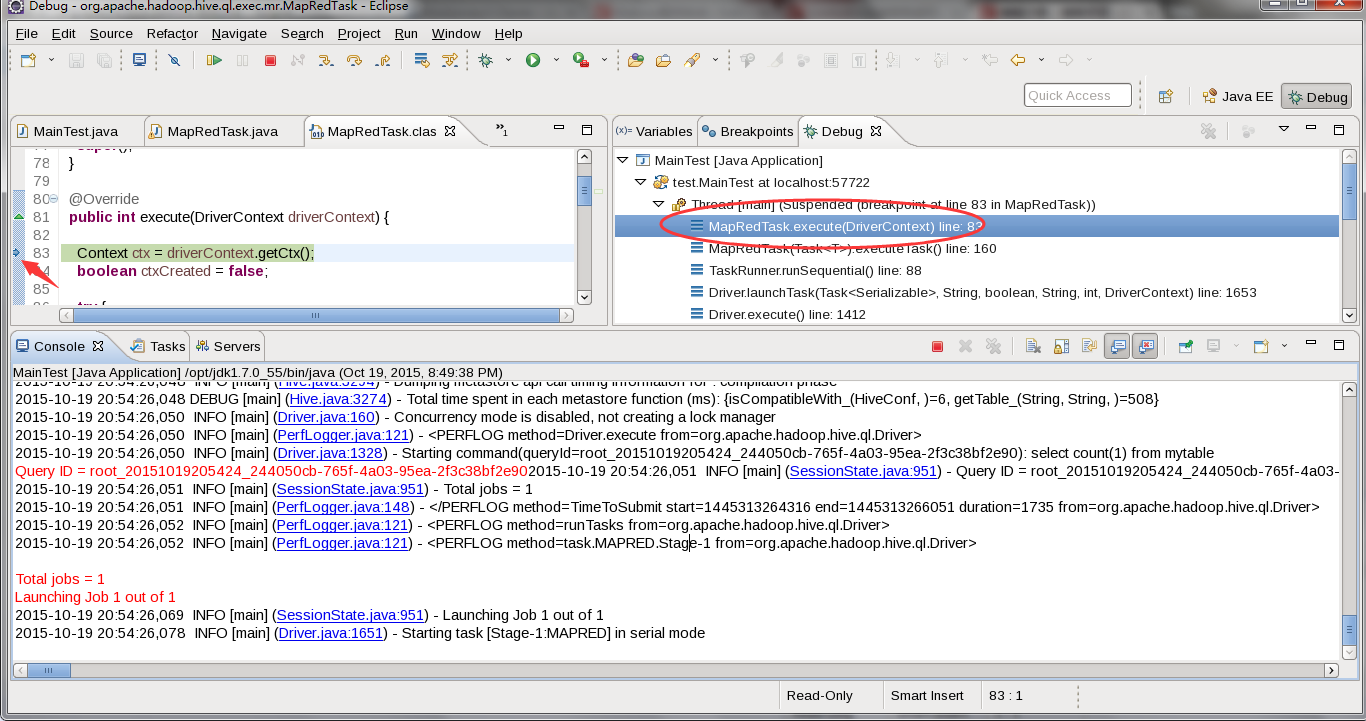
这里看到的确是进入了debug模式。
如何添加源码?看下图
4. 总结:
(1) hive1.2.1目前使用源码编译得到的版本,并不支持hadoop2的调试;(就个人所作的工作的结果来看);
(2)hive1.2.1使用eclipse调试源码可以使用新建工程的方式,然后导入官网编译的hive包及hadoop包进行调试,同时需要注意一般需要在linux环境下调试,如果需要在windows下调试,需要安装winutils.exe ;
软件版本:
hive1.2.1 ,eclipse4.5,maven3.2 ,JDK1.7
软件准备:
hive:
环境准备:
(1). 安装好的Hadoop集群(伪分布式亦可);
(2) linux 下maven环境;(这里需要说下,maven编译hive,在windows下是不通的,因为里面需要bash的支持,所以直接使用linux编译hive就好)
0. 编译前,建议把maven的local_reposity 配置下,同时配置源如下(开源中国的maven源,相对国外的源较快):
[Java] 纯文本查看 复制代码
?
(1)mvn clean install -DskipTests -Phadoop-2
[Java] 纯文本查看 复制代码
?
(3)编译成eclipse工程:
mvn eclipse:eclipse -DdownloadSources -DdownloadJavadocs -Phadoop-2
[Java] 纯文本查看 复制代码
?
2. 编译后工程导入eclipse中
这里导入需要分为两种情况,分为导入windows下的eclipse和导入linux下的eclipse中;(因为一般使用机器都是windows的,所以如果可以使用windows,则最好)
2.1 工程导入windows的eclipse中;
打开eclipse,右键-> Import ,选择编译后的文件夹(这里需要把编译后的文件下载到windows上);即可看到如下的界面:
当然,这里会有些错误,比如jdk/tool.jar找不到等等,这个是因为编译的jdk和windows的jdk不一样,调整下即可。
(1)运行 hive-cli 工程的CliDriver(当然,要先启动hive相关进行,hive --service metastore & ; hive --service hiveserver2 &)
运行后会直接报错,说 driver “hive-site.xml ”not in Classpath 什么的错误,修改方法:
打开hive-common工程的本地目录的target/test-classes路径
修改里面的core-site.xml 以及hive-site.xml ,这里面的配置就参考hadoop集群以及hive的配置即可
然后再次运行CliDriver,发现报下面的错误:
[Plain Text] 纯文本查看 复制代码
?
这样子肯定是有 问题的,集群都使用的是hadoop2的版本,但是代码却用的hadoop1,这样报这个错就没啥奇怪的了。那问题是出在了哪呢?
通过查看hive-shims-common工程,发现其工程的依赖只有hadoop1,没有hadoop2,而hive-cli工程也是依赖hive-shims-common工程,这也就解释了为什么Java的classpath里面hadoop1的jar包在hadoop2前面了。
此路不通!
(2)运行hive-beeline工程的BeeLine
直接运行,进入beeline交互式命令终端,如下图:
发现是可以连接hive的,比如mr查询:
但是这个不可以调试,即使用debug模式,仍然不能调试。
所以对于阅读源码,查看调用关系来说这种模式也不是很好。
2.2 导入到linux的eclipse工程
此导入和windows不无差别。
3. 直接新建工程,使用编译后的hive jar包(此处的jar包不是指自己编译的,而是官网直接提供的),就apache-hive-1.2.1-bin.tar.gz文件。
3.1 在windows的eclipse中新建hive工程
同时新建一个类,如上图所示。
这里还需要注意:
a. 引入编译后的hive的lib包的所有jar包;
b. 引入MySQL的连接jar包;
c. 引入hadoop的相关jar包
(1)写一个测试程序,调用CliDriver,出现下面的错误:
[Java] 纯文本查看 复制代码
?
[AppleScript] 纯文本查看 复制代码
?
(2)写一个调用程序,运行BeeLine,这个没有测试。
3.2 linux的eclipse新建hive工程:
建立的工程和windows并无二致,如下:
同样编写程序调用CliDriver,Debug运行,如下所示(需要注意我在这里并没有配置hadoop相关目录):
做一个查询,看是否可以启动debug模式:
这里看到的确是进入了debug模式。
如何添加源码?看下图
4. 总结:
(1) hive1.2.1目前使用源码编译得到的版本,并不支持hadoop2的调试;(就个人所作的工作的结果来看);
(2)hive1.2.1使用eclipse调试源码可以使用新建工程的方式,然后导入官网编译的hive包及hadoop包进行调试,同时需要注意一般需要在linux环境下调试,如果需要在windows下调试,需要安装winutils.exe ;

相关文章推荐
- 69 个经典 Spring 面试题和答案
- How to Install OpenJDK 8 in Ubuntu 14.04 & 12.04 LTS
- JavaBean中DAO设计模式介绍 .
- java中的 FileWriter类 和 FileReader类的一些基本用法
- Spring事务:调用同一个类中的方法
- 两个好用的eclipse js编辑器插件
- java可变参数总结
- java-获取.csv文件里的数据,并且获取文件夹下所含有对象的个数
- java中Cookie的使用
- SpringBoot 模板引擎 Template engines
- Java——ThreadLocal类
- 举例讲解Java设计模式编程中Decorator装饰者模式的运用
- Java——ThreadLocal类
- javaoop从 封装到继承
- Java class 文件结构及解析
- JAVA并发实现五(生产者和消费者模式wait和notify方式实现)
- Java实现定时任务的三种方法
- Spring结合java Quartz配置实例代码
- eclipse svn同步时忽略某些文件类型和文件夹
- Java中Comparable和Comparator的辨析