延云YDB&&YA100安装部署文档
2016-05-01 17:54
197 查看
YDB:实时在线分析(OLAP)系统:是我们自主研发的一个大型分布式索引系统。旨在为数据总量为万亿级别、每天千亿级别数据增量的项目提供近似实时的数据导入,并提供近似实时响应的多维查询与统计服务。
Ya100:大数据加速器:Spark
SQL的一种新的存储格式。 Ya100比Parquet格式快5~100倍.任意维度组合,过滤,万亿数据秒级响应。Ya100内嵌ydb可以通过kafka进行数据的实时导入。
依赖的硬件配置
一、延云YDB最低配置
1.内存:16G
2.磁盘:至少2块独立的物理硬盘,数据盘与操作系统盘分离。
3.CPU:至少8线程(1颗,4核,8线程)
二、如下场景,延云将不再提供安装技术支持
1.低于最低配置要求的用户。
2.虚拟机用户:hadoop在虚拟机中执行效率很低。
3.32位系统的用户:这类系统最大只有4G内存。
三、延云YDB推荐配置
1.机器内存:128G
2.磁盘:2T*12的磁盘
3.CPU:24线程(2颗,12核,24线程)
YDB依赖的软件环境(需用户自行安装)
1.操作系统
Centos 6.x 64bit
不推荐过老或过新的操作系统,诸多hadoop厂商的发行版在过老或过新的系统上有问题。
2.Java
JDK1.7及以上版本
3.Hadoop
2.0以上版本,需要支持yarn
4.Zookeeper
zookeeper-3.4.5及以上版本
4.Spark版本
1.6.x系列,推荐1.6.1版本。之前的版本运行不了。
Spark只需要编译好的安装包,放到指定磁盘目录即可,您无需安装与部署。
如果您的Hadoop版本交特殊:可以下载spark源码进行编译,编译命令如下
export JAVA_HOME=/install/jdk
export PATH=$JAVA_HOME/bin:$PATH
export MAVEN_OPTS="-Xmx3g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m“
build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.1
-Phive -Phive-thriftserver -DskipTests -Dmaven.test.skip=true
clean package
##################################################
操作系统:基本可用性检查
1.ulimit –n 检查是否是65535而不是默认的1024
否则执行如下三步配置ulimit
第一步:执行 ulimit -n 65535
第二步:编辑/etc/security/limits.conf最后增加如下两行记录
*softnofile 65535
* hard
nofile 65535
第三步:编辑/etc/security/limits.d/90-nproc.conf
将其中的1024也修改为65535
2.确定多台机器之间的时钟时间是否同步,建议配置ntp服务
3.防火墙是否关闭
iptables–F以及通过setup\services等服务里将防火墙关闭
4.Swap是否关闭
Swap会对系统的稳定性带来较大影响,一般hadoop生态圈均禁用swap,禁用方法为执行
swapoff-a
5.检查/proc/sys/vm/overcommit_memory的配置值
如果为2,建议修改为0,否则有可能会出现,明明机器可用物理内存很多,但jvm确申请不了内存的情况。
6.检查语言环境是否UTF8
否则 配置 exportLANG=zh_CN.UTF-8这个环境变量
7.10000端口是否被占用
由于ya100对外的jdbc的服务端口为10000,需要先通过netstat
–npl|grep 10000看看是否有进程已经占用了改端口,如果有,相关服务要先停掉后才能启动ya100,典型场景是,先前这台机器已经启动了别的spark或hive服务,占用了10000端口
依赖的软件:基本可用性检查
1.HDFS检查
打开50070端口,检查hdfs是否启动成功,存储空间分配的是否正确
第一:确保hdfs安装成功,一定要手工通过hadoop–put命令,上传一个文件试一试。
第二:确保将来准备分配给YDB的hdfs目录有读写权限,建议第一次新手安装,取消hdfs的权限验证,配置dfs.permissions.enabled为false,并重启集群
第三:一定要确保dfs.datanode.data.dir的目录配置的是所有的数据盘,而不是配给了系统盘
系统盘一定要与数据盘分离,否则磁盘特别繁忙的时候会造成操作系统很繁忙,zk之类的容易挂掉。
2.YARN检查
打开8088,检查yarn是否启动成功,VCoresTotal
\Memory Total 分配的是否正确。经常有朋友忘记更改yarn的默认配置导致一台128G内存的机器最多只能启动2个进程,只能使用8G内存。
第一:yarn.nodemanager.resource.memory-mb用于配置Yarn当前机器的可用内存,通常配置当前机器剩余可用内存的80%.
第二:yarn.scheduler.minimum-allocation-mb为一个Yarn
container申请内存的最小计费单位,建议调小一些,如128,让计费更精准.
第三:yarn.scheduler.maximum-allocation-mb为一个Yarn
container可以申请最大的内存,建议调整为32768(不一定真用到这些).
第四:yarn.nodemanager.resource.cpu-vcores当前机器可以启动的Yarn container的数量,建议配置为当前机器的cpu的线程数 如24个。
第五:yarn.nodemanager.pmem-check-enabled与yarn.nodemanager.vmem-check-enabled一定要都配置成false,因为1.6版本的spark有BUG,会使用较多的堆外内存,yarn会kill掉相关container,造成服务的不稳定。
第六:mapreduce.application.classpath里面的值是否有配置的jar包并不存在,典型的情况下是找不到lzo的包(许多厂商的安装部署会配置该参数),如果有的jar包找不到,建议注释掉相关依赖,否则可能会造成ydb启动失败;
如默认的hdp集群就要将其中的lzo的配置给注释掉/usr/hdp/${hdp.version}/hadoop/lib/hadoop-lzo-0.6.0.${hdp.version}.jar;
3.Zookeeper检查
第一:要探测zookeeper的2181端口是否启动 可以通过netstat
–npl|grep2181来查看
第二:zookeeper的数据目录别与hdfs的数据盘放在一起,尽量独立一个磁盘,或者放在系统盘,否则数据盘特别繁忙的时候zookeeper本身非常容易挂掉
第三:zookeeper的日志清理要打开,否则会出现系统运行几个月后,zookeeper所在的磁盘硬盘变满的情况,将zoo.cfg里的这两个配置项注释开即可:
autopurge.purgeInterval=24
autopurge.snapRetainCount=30
##################################################
开始部署延云YDB
第一:去延云的官方下载最新的稳定版的YDBhttp://ycloud.net.cn/yyydb
第二:将YDB上传到服务器上,并解压
第三:配置conf目录下的ya100_env.sh环境变量
1.基本环境配置
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_HOME=/usr/hdp/current/hadoop-client
export JAVA_HOME=/usr/jdk64/jdk1.8.0_60
exportSPARK_HOME=/root/software/spark-1.6.1
注意:配置过后大家一定要手工验证下,相关目录的配置文件是否真的存在
2.配置内存与启动的并发数
#为启动的进程数量,切记不要超过yarn总的vcores的数量-1,建议每台机器配置cpu线程数的一半,如12个;
#如果有3台机器,每台机器配置12个的话那么下面这项的值要写36,不要只写12
export YA100_EXECUTORS=12
#启动的进程,每个给分配多少内存
#YA100_EXECUTORS*YA100_MEMORY的大小建议为yarn总内存的3/5(剩下的留给操作系统)
#关于内存控制参数的详细说明,请阅读example下的《3.大家需要了解的几个内存控制的参数.txt》说明
export YA100_MEMORY=2500m
#每个进程内启动的线程数,一般不需要修改
export YA100_CORES=2
#ya100接口程序分配的内存,建议2000m以上
export YA100_DRIVER_MEMORY=3000m
第四:配置conf目录下的ydb_site.yaml环境变量
该文件的配置非常容易出错,要注意如下几点:
1.文件格式必须为utf8格式,切记切记
2.每个配置项的开头必须有个空格,而不tab
3.配置文件中别出现tab
4.注意每个KEY: VALUE之间是有一个空格的,如果value是字符串类型,要用双引号括起来
配置项说明如下:
1.配置Ydb的存储路径的配置ydb.hdfs.path
注意ydb的存储路径与ya100的存储路径不是一个,要分别配置成不同的路径,不能重复
ya100的默认存储路径在conf目录下的hive-site.xml中的hive.metastore.warehouse.dir
Ya100的每张表的存储路径也可以再创建表的时候由location来指定。
2.配置Ydb在实时导入过程中,所使用的临时目录ydb.reader.rawdata.hdfs.path
3.配置ydb httpui服务的端口ydb.httpserver.port默认为1210
4.配置ydb依赖的zookeeper的地址
storm.zookeeper.servers:
- "192.168.1.10"
storm.zookeeper.root: "/ycloud/ydb“
第五:其他ya100/conf目录下的配置文件的说明
1.hive-site.xml hive表的配置,如果想要更改hive的一些配置,如将hive的元数据写入到数据库里,可修改此文件。
2.spark-defaults.conf用于配置spark,如果需要修改spark的默认调度规则,可以修改此配置。
3.init.sql为ya100启动时候的初始化方法,如果我们的业务需要自定义UDF,可以考虑将自定义UDF语句放到这里,通过init.sh来执行
4.driver.log.properties为接口程序的log4j的配置,默认日志记录在logs目录下
5.worker.log.properties为ya100的工作进程的log4j的配置,默认记录在每台机器的yarn的工作目录下。
服务的启动与检查
进入bin目录,执行chmoda+x *.sh
第一:启动spark
./start.sh
第二:spark
服务检查:
1.tail
-f../logs/ya100.log 看是否有报错,当出现如下的日志,表示启动成功

2.打开yarn的8088页面,看启动的container数量以及内存的时候是否正确

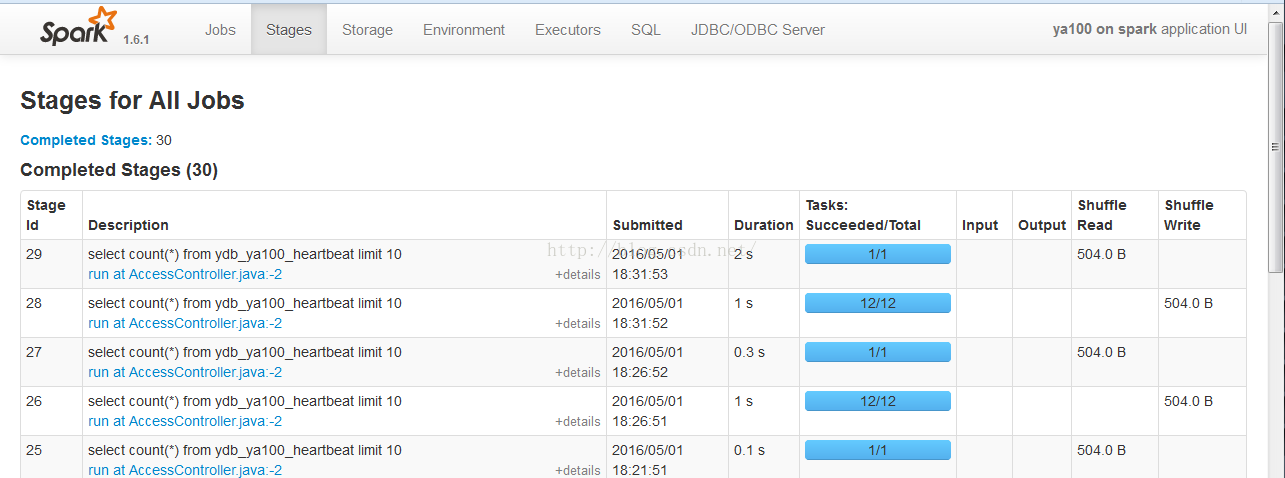
3.看下面是否有ya100 on spark的任务,点击对应的applicationMaster看是否能打开spark的ui页面
第三:启动ydb
./init.sh
第四:YDB服务检查
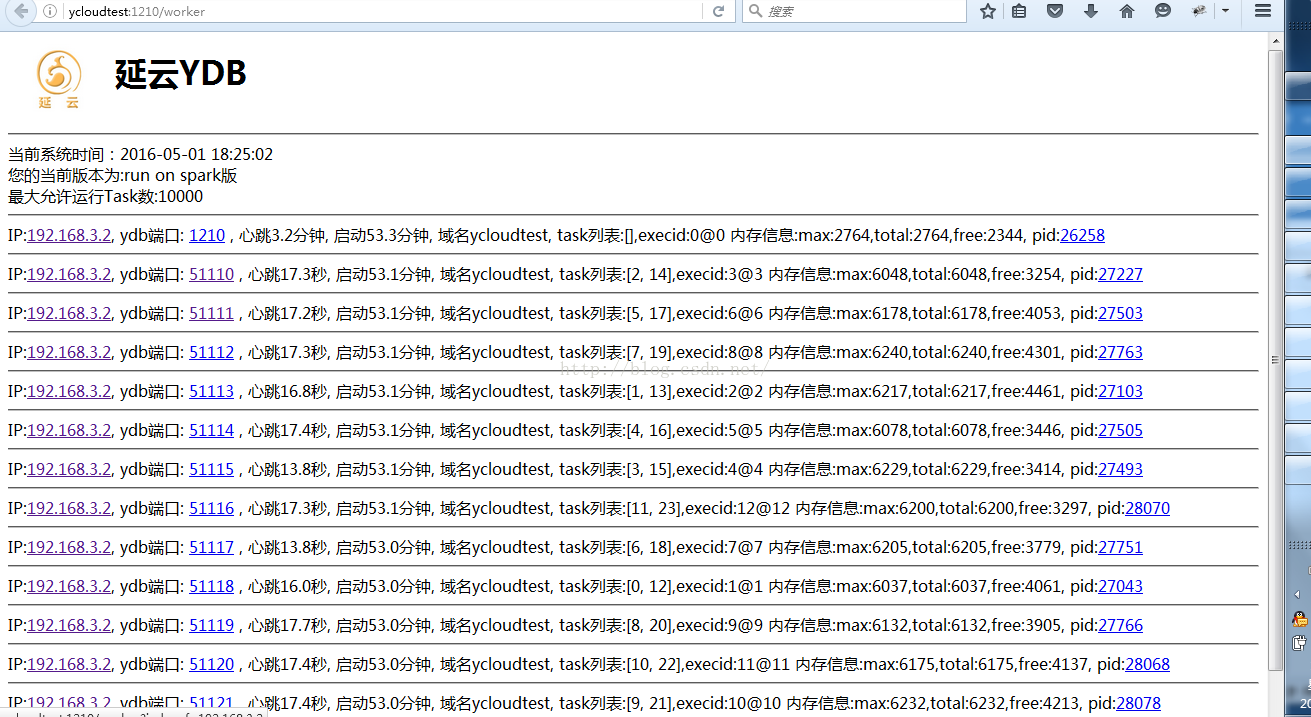
1.通过浏览器打开:1210页面,看是否能打开
2.点开“work工作进程列表”看启动的worker数量是否与在ya100_env.sh里配置的YA100_EXECUTORS数量一致
第五:服务的停止
./stop.sh
##################################################
了解延云ya100、ydb的用法、进行测试、生成演示demo
打开ya100/example目录
第一: ya100_example.sql
包含了 ya100的基本表的创建,查询的使用,数据的导入等。
第二: ydb_example.sql
包含了ydb的表的创建,ya100与ydb表的连接,查询的使用,数据的导入等
第三:如何通过kafka实时导入数据.txt
阐述了Ydb如何通过kafka实时的进行数据导入
第四:”标准性能测试.txt ”
给出了如何用ya100自带的25个用例进行性能比较测试以及标准的tcp-h测试方法
第五:”演示demo搭建.txt”
如何快速的使用ydb生成延云官方提供的演示demo
Ya100与ydb的四种使用方法
1.命令行操作
cd bin
./conn.sh
直接数据命令
./conn.sh -f xxx.sql来执行一个文件里的全部的SQL
2.通过jdbc来连接
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection
conn = DriverManager.getConnection("jdbc:hive2://101.200.130.48:10000/default","ycloud","");
Statement
smst = conn.createStatement();
smst.executeQuery("setya100.spark.filter.tg_2k1v_ly_ya100=;");
smst.executeQuery("setya100.spark.combine.tg_2k1v_ly_ya100=*;");
smst.executeQuery("setya100.spark.top10000.tg_2k1v_ly_ya100=;");
ResultSetrs =smst.executeQuery("selectYcount('*',ya100_pipe)
from tg_2k1v_ly_ya100 limit 300");
while (rs.next()){
for (int i = 0; i < columnNum;i++) {
objArray[i]=rs.getObject(i
+1);
}
rs.close();
smst.close();
conn.close();
3. 旧版YDB接口(为兼容而保留)
http://192.168.112.129:8080/sql?sql=selectindexnum,label fromydbexample
whereydbpartion=‘20151011’ limit 0,100
4.新版web接口
http://192.168.112.129:8080/sparksql?sql=set+ya100.spark.filter.tg_2k1v_ly_ya100%3D%3B+set+ya100.spark.combine.tg_2k1v_ly_ya100%3D*%3B+set+ya100.spark.top10000.tg_2k1v_ly_ya100%3D%3Bselect+indexnum%2Clabel+from+ydbexample+where+ydbpartion%3D%E2%80%9820151011%E2%80%99+limit+100
常见问题FAQ
1.是否在同一个yarn环境下混搭多个不同的环境?
延云产品跟其他对性能要求较高的系统如Hbase一样。虽然支持混搭,但不建议这样做。
通常来说为了避免相互之间造成较严重的影响,一般都是独立的集群。
2.是否可以在虚拟机下运行
延云产品可以运行在虚拟机下,但是由于hadoop运行在虚拟机中性能损耗较大,所以延云跟大数据生态圈中的其他产品一样,真正的生产环境并不推荐使用虚拟机。
3.出现Container released on a *lost* node后服务就挂了
需要先检查下磁盘的使用率是否超过90%,默认yarn会为每台机器保留10%的空间,如果剩余空间较少,yarn就会停掉这些机器上的进程。
4.使用Ya100在进行数据导入的时候,或者进行一些复杂较大的查询时其他查询会卡主。
默认ya100使用Spark的FIFO的调度模式,意味着那个任务先开始,后续的任务必须等待其完成结束后才能开始后续的查询。大家可以编辑ya100目录下的spark-defaults.conf配置文件,将其调度器,更改为公平调度模式,将一部分资源预留给较重要的查询。具体可以参考这个。
http://www.07net01.com/program/658140.html
Ya100:大数据加速器:Spark
SQL的一种新的存储格式。 Ya100比Parquet格式快5~100倍.任意维度组合,过滤,万亿数据秒级响应。Ya100内嵌ydb可以通过kafka进行数据的实时导入。
依赖的硬件配置
一、延云YDB最低配置
1.内存:16G
2.磁盘:至少2块独立的物理硬盘,数据盘与操作系统盘分离。
3.CPU:至少8线程(1颗,4核,8线程)
二、如下场景,延云将不再提供安装技术支持
1.低于最低配置要求的用户。
2.虚拟机用户:hadoop在虚拟机中执行效率很低。
3.32位系统的用户:这类系统最大只有4G内存。
三、延云YDB推荐配置
1.机器内存:128G
2.磁盘:2T*12的磁盘
3.CPU:24线程(2颗,12核,24线程)
YDB依赖的软件环境(需用户自行安装)
1.操作系统
Centos 6.x 64bit
不推荐过老或过新的操作系统,诸多hadoop厂商的发行版在过老或过新的系统上有问题。
2.Java
JDK1.7及以上版本
3.Hadoop
2.0以上版本,需要支持yarn
4.Zookeeper
zookeeper-3.4.5及以上版本
4.Spark版本
1.6.x系列,推荐1.6.1版本。之前的版本运行不了。
Spark只需要编译好的安装包,放到指定磁盘目录即可,您无需安装与部署。
如果您的Hadoop版本交特殊:可以下载spark源码进行编译,编译命令如下
export JAVA_HOME=/install/jdk
export PATH=$JAVA_HOME/bin:$PATH
export MAVEN_OPTS="-Xmx3g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m“
build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.1
-Phive -Phive-thriftserver -DskipTests -Dmaven.test.skip=true
clean package
##################################################
操作系统:基本可用性检查
1.ulimit –n 检查是否是65535而不是默认的1024
否则执行如下三步配置ulimit
第一步:执行 ulimit -n 65535
第二步:编辑/etc/security/limits.conf最后增加如下两行记录
*softnofile 65535
* hard
nofile 65535
第三步:编辑/etc/security/limits.d/90-nproc.conf
将其中的1024也修改为65535
2.确定多台机器之间的时钟时间是否同步,建议配置ntp服务
3.防火墙是否关闭
iptables–F以及通过setup\services等服务里将防火墙关闭
4.Swap是否关闭
Swap会对系统的稳定性带来较大影响,一般hadoop生态圈均禁用swap,禁用方法为执行
swapoff-a
5.检查/proc/sys/vm/overcommit_memory的配置值
如果为2,建议修改为0,否则有可能会出现,明明机器可用物理内存很多,但jvm确申请不了内存的情况。
6.检查语言环境是否UTF8
否则 配置 exportLANG=zh_CN.UTF-8这个环境变量
7.10000端口是否被占用
由于ya100对外的jdbc的服务端口为10000,需要先通过netstat
–npl|grep 10000看看是否有进程已经占用了改端口,如果有,相关服务要先停掉后才能启动ya100,典型场景是,先前这台机器已经启动了别的spark或hive服务,占用了10000端口
依赖的软件:基本可用性检查
1.HDFS检查
打开50070端口,检查hdfs是否启动成功,存储空间分配的是否正确
第一:确保hdfs安装成功,一定要手工通过hadoop–put命令,上传一个文件试一试。
第二:确保将来准备分配给YDB的hdfs目录有读写权限,建议第一次新手安装,取消hdfs的权限验证,配置dfs.permissions.enabled为false,并重启集群
第三:一定要确保dfs.datanode.data.dir的目录配置的是所有的数据盘,而不是配给了系统盘
系统盘一定要与数据盘分离,否则磁盘特别繁忙的时候会造成操作系统很繁忙,zk之类的容易挂掉。
2.YARN检查
打开8088,检查yarn是否启动成功,VCoresTotal
\Memory Total 分配的是否正确。经常有朋友忘记更改yarn的默认配置导致一台128G内存的机器最多只能启动2个进程,只能使用8G内存。
第一:yarn.nodemanager.resource.memory-mb用于配置Yarn当前机器的可用内存,通常配置当前机器剩余可用内存的80%.
第二:yarn.scheduler.minimum-allocation-mb为一个Yarn
container申请内存的最小计费单位,建议调小一些,如128,让计费更精准.
第三:yarn.scheduler.maximum-allocation-mb为一个Yarn
container可以申请最大的内存,建议调整为32768(不一定真用到这些).
第四:yarn.nodemanager.resource.cpu-vcores当前机器可以启动的Yarn container的数量,建议配置为当前机器的cpu的线程数 如24个。
第五:yarn.nodemanager.pmem-check-enabled与yarn.nodemanager.vmem-check-enabled一定要都配置成false,因为1.6版本的spark有BUG,会使用较多的堆外内存,yarn会kill掉相关container,造成服务的不稳定。
第六:mapreduce.application.classpath里面的值是否有配置的jar包并不存在,典型的情况下是找不到lzo的包(许多厂商的安装部署会配置该参数),如果有的jar包找不到,建议注释掉相关依赖,否则可能会造成ydb启动失败;
如默认的hdp集群就要将其中的lzo的配置给注释掉/usr/hdp/${hdp.version}/hadoop/lib/hadoop-lzo-0.6.0.${hdp.version}.jar;
3.Zookeeper检查
第一:要探测zookeeper的2181端口是否启动 可以通过netstat
–npl|grep2181来查看
第二:zookeeper的数据目录别与hdfs的数据盘放在一起,尽量独立一个磁盘,或者放在系统盘,否则数据盘特别繁忙的时候zookeeper本身非常容易挂掉
第三:zookeeper的日志清理要打开,否则会出现系统运行几个月后,zookeeper所在的磁盘硬盘变满的情况,将zoo.cfg里的这两个配置项注释开即可:
autopurge.purgeInterval=24
autopurge.snapRetainCount=30
##################################################
开始部署延云YDB
第一:去延云的官方下载最新的稳定版的YDBhttp://ycloud.net.cn/yyydb
第二:将YDB上传到服务器上,并解压
第三:配置conf目录下的ya100_env.sh环境变量
1.基本环境配置
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_HOME=/usr/hdp/current/hadoop-client
export JAVA_HOME=/usr/jdk64/jdk1.8.0_60
exportSPARK_HOME=/root/software/spark-1.6.1
注意:配置过后大家一定要手工验证下,相关目录的配置文件是否真的存在
2.配置内存与启动的并发数
#为启动的进程数量,切记不要超过yarn总的vcores的数量-1,建议每台机器配置cpu线程数的一半,如12个;
#如果有3台机器,每台机器配置12个的话那么下面这项的值要写36,不要只写12
export YA100_EXECUTORS=12
#启动的进程,每个给分配多少内存
#YA100_EXECUTORS*YA100_MEMORY的大小建议为yarn总内存的3/5(剩下的留给操作系统)
#关于内存控制参数的详细说明,请阅读example下的《3.大家需要了解的几个内存控制的参数.txt》说明
export YA100_MEMORY=2500m
#每个进程内启动的线程数,一般不需要修改
export YA100_CORES=2
#ya100接口程序分配的内存,建议2000m以上
export YA100_DRIVER_MEMORY=3000m
第四:配置conf目录下的ydb_site.yaml环境变量
该文件的配置非常容易出错,要注意如下几点:
1.文件格式必须为utf8格式,切记切记
2.每个配置项的开头必须有个空格,而不tab
3.配置文件中别出现tab
4.注意每个KEY: VALUE之间是有一个空格的,如果value是字符串类型,要用双引号括起来
配置项说明如下:
1.配置Ydb的存储路径的配置ydb.hdfs.path
注意ydb的存储路径与ya100的存储路径不是一个,要分别配置成不同的路径,不能重复
ya100的默认存储路径在conf目录下的hive-site.xml中的hive.metastore.warehouse.dir
Ya100的每张表的存储路径也可以再创建表的时候由location来指定。
2.配置Ydb在实时导入过程中,所使用的临时目录ydb.reader.rawdata.hdfs.path
3.配置ydb httpui服务的端口ydb.httpserver.port默认为1210
4.配置ydb依赖的zookeeper的地址
storm.zookeeper.servers:
- "192.168.1.10"
storm.zookeeper.root: "/ycloud/ydb“
第五:其他ya100/conf目录下的配置文件的说明
1.hive-site.xml hive表的配置,如果想要更改hive的一些配置,如将hive的元数据写入到数据库里,可修改此文件。
2.spark-defaults.conf用于配置spark,如果需要修改spark的默认调度规则,可以修改此配置。
3.init.sql为ya100启动时候的初始化方法,如果我们的业务需要自定义UDF,可以考虑将自定义UDF语句放到这里,通过init.sh来执行
4.driver.log.properties为接口程序的log4j的配置,默认日志记录在logs目录下
5.worker.log.properties为ya100的工作进程的log4j的配置,默认记录在每台机器的yarn的工作目录下。
服务的启动与检查
进入bin目录,执行chmoda+x *.sh
第一:启动spark
./start.sh
第二:spark
服务检查:
1.tail
-f../logs/ya100.log 看是否有报错,当出现如下的日志,表示启动成功
2.打开yarn的8088页面,看启动的container数量以及内存的时候是否正确
3.看下面是否有ya100 on spark的任务,点击对应的applicationMaster看是否能打开spark的ui页面
第三:启动ydb
./init.sh
第四:YDB服务检查
1.通过浏览器打开:1210页面,看是否能打开
2.点开“work工作进程列表”看启动的worker数量是否与在ya100_env.sh里配置的YA100_EXECUTORS数量一致
第五:服务的停止
./stop.sh
##################################################
了解延云ya100、ydb的用法、进行测试、生成演示demo
打开ya100/example目录
第一: ya100_example.sql
包含了 ya100的基本表的创建,查询的使用,数据的导入等。
第二: ydb_example.sql
包含了ydb的表的创建,ya100与ydb表的连接,查询的使用,数据的导入等
第三:如何通过kafka实时导入数据.txt
阐述了Ydb如何通过kafka实时的进行数据导入
第四:”标准性能测试.txt ”
给出了如何用ya100自带的25个用例进行性能比较测试以及标准的tcp-h测试方法
第五:”演示demo搭建.txt”
如何快速的使用ydb生成延云官方提供的演示demo
Ya100与ydb的四种使用方法
1.命令行操作
cd bin
./conn.sh
直接数据命令
./conn.sh -f xxx.sql来执行一个文件里的全部的SQL
2.通过jdbc来连接
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection
conn = DriverManager.getConnection("jdbc:hive2://101.200.130.48:10000/default","ycloud","");
Statement
smst = conn.createStatement();
smst.executeQuery("setya100.spark.filter.tg_2k1v_ly_ya100=;");
smst.executeQuery("setya100.spark.combine.tg_2k1v_ly_ya100=*;");
smst.executeQuery("setya100.spark.top10000.tg_2k1v_ly_ya100=;");
ResultSetrs =smst.executeQuery("selectYcount('*',ya100_pipe)
from tg_2k1v_ly_ya100 limit 300");
while (rs.next()){
for (int i = 0; i < columnNum;i++) {
objArray[i]=rs.getObject(i
+1);
}
rs.close();
smst.close();
conn.close();
3. 旧版YDB接口(为兼容而保留)
http://192.168.112.129:8080/sql?sql=selectindexnum,label fromydbexample
whereydbpartion=‘20151011’ limit 0,100
4.新版web接口
http://192.168.112.129:8080/sparksql?sql=set+ya100.spark.filter.tg_2k1v_ly_ya100%3D%3B+set+ya100.spark.combine.tg_2k1v_ly_ya100%3D*%3B+set+ya100.spark.top10000.tg_2k1v_ly_ya100%3D%3Bselect+indexnum%2Clabel+from+ydbexample+where+ydbpartion%3D%E2%80%9820151011%E2%80%99+limit+100
常见问题FAQ
1.是否在同一个yarn环境下混搭多个不同的环境?
延云产品跟其他对性能要求较高的系统如Hbase一样。虽然支持混搭,但不建议这样做。
通常来说为了避免相互之间造成较严重的影响,一般都是独立的集群。
2.是否可以在虚拟机下运行
延云产品可以运行在虚拟机下,但是由于hadoop运行在虚拟机中性能损耗较大,所以延云跟大数据生态圈中的其他产品一样,真正的生产环境并不推荐使用虚拟机。
3.出现Container released on a *lost* node后服务就挂了
需要先检查下磁盘的使用率是否超过90%,默认yarn会为每台机器保留10%的空间,如果剩余空间较少,yarn就会停掉这些机器上的进程。
4.使用Ya100在进行数据导入的时候,或者进行一些复杂较大的查询时其他查询会卡主。
默认ya100使用Spark的FIFO的调度模式,意味着那个任务先开始,后续的任务必须等待其完成结束后才能开始后续的查询。大家可以编辑ya100目录下的spark-defaults.conf配置文件,将其调度器,更改为公平调度模式,将一部分资源预留给较重要的查询。具体可以参考这个。
http://www.07net01.com/program/658140.html

相关文章推荐
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- 延云YDB&&YA100安装部署文档
- JSON入门总结
- read the python code and predict the results --- from <Learn Python The Hard Way>
- Python 装饰器
- nyoj 36最长公共子序列&&nyoj 37 回文字符串
- IIS的安装和牛腩发布
- UITableViewCell图片视差效果
- Java必知必会:异常机制详解
- 学习进度第九周
- 《Head First-Chapter4》工厂模式
- java.lang.NoSuchMethodException: org.apache.catalina.deploy.WebXml addServlet
- 搭建RHEL实验环境
- MAC 环境下的Lua配置