查找 -数据结构
2016-04-30 12:37
323 查看
查找 -数据结构
几种查找算法:顺序查找,折半查找,分块查找,散列表
一、顺序查找的基本思想:从表的一端开始,向另一端逐个按给定值kx 与关键码进行比较,若找到,查找成功,并给出数据元素在表中的位置;若整个表检测完,仍未找到与kx 相同的关键码,则查找失败,给出失败信息。
说白了就是,从头到尾,一个一个地比,找着相同的就成功,找不到就失败。很明显的缺点就是查找效率低。
【适用性】:适用于线性表的顺序存储结构和链式存储结构。
平均查找长度=(n+1)/2.
【顺序查找优缺点】:
缺点:是当n 很大时,平均查找长度较大,效率低;
优点:是对表中数据元素的存储没有要求。另外,对于线性链表,只能进行顺序查找。
二、有序表的折半查找基本思想:
在有序表中,取中间元素作为比较对象,若给定值与中间元素的关键码相等,则查找成功;若给定值小于中间元素的关键码,则在中间元素的左半区继续查找;若给定值大于中间元素的关键码,则在中间元素的右半区继续查找。不断重复上述查找过程,直到查找成功,或所查找的区域无数据元素,查找失败。
【步骤】
① low=1;high=length; // 设置初始区间
② 当low>high 时,返回查找失败信息// 表空,查找失败
③ low≤high,mid=(low+high)/2; //确定该区间的中点位置
a. 若kx<tbl.elem[mid].key,high = mid-1;转② // 查找在左半区进行
b. 若kx>tbl.elem[mid].key,low = mid+1; 转② // 查找在右半区进行
c. 若kx=tbl.elem[mid].key,返回数据元素在表中位置// 查找成功
有序表按关键码排列如下:
7,14,18,21,23,29,31,35,38,42,46,49,52
在表中查找关键码为14 的数据元素:

【算法实现】
[cpp] view plain copy
print?
int Binary_Search(ElemType a[], ElemType kx, int length)
{
int mid,low,high, flag = 0;
low = 0; high = length; /* ①设置初始区间*/
while(low <= high) /* ②表空测试*/
{ /* 非空,进行比较测试*/
mid = (low + high)/2; /* ③得到中点*/
if(kx < a[mid]) high = mid-1; /* 调整到左半区*/
else if(kx > a[mid]) low = mid+1; /* 调整到右半区*/
else { /* 查找成功,元素位置设置到flag 中*/
flag=mid;
break;
}
}
return flag;
}
【性能分析】
平均查找长度=Log2(n+1)-1
从折半查找过程看,以表的中点为比较对象,并以中点将表分割为两个子表,对定位到的子表继续这种操作。所以,对表中每个数据元素的查找过程,可用二叉树来描述,称这个描述查找过程的二叉树为判定树。

(7,14,18,21,23,29,31,35,38,42,46,49,52)折半查找的判定树
可以看到,查找表中任一元素的过程,即是判定树中从根到该元素结点路径上各结点关键码的比较次数,也即该元素结点在树中的层次数。对于n 个结点的判定树,树高为k,则有2k-1 -1<n≤2k-1,即k-1<log2(n+1)≤k,所以k= 。因此,折半查找在查找成功时,所进行的关键码比较次数至多为。
接下来讨论折半查找的平均查找长度。为便于讨论,以树高为k 的满二叉树(n=2k-1)为例。假设表中每个元素的查找是等概率的,即Pi= ,则树的第i 层有2i-1 个结点,因此,折半查找的平均查找长度为:
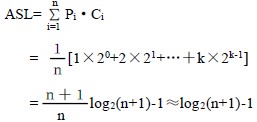
所以,折半查找的时间效率为O(log2n)。
注:
虽然折半查找的效率高,但是要将表按关键字排序。而排序本身是一种很费时的运算,所以二分法比较适用于顺序存储结构。为保持表的有序性,在顺序结构中插入和删除都必须移动大量的结点。因此,折半查找特别适用于那种一经建立就很少改动而又经常需要查找的线性表。
三、分块查找(索引查找)的基本思想:
分块查找又称索引顺序查找,是对顺序查找的一种改进。分块查找要求将查找表分成 若干个子表,并对子表建立索引表,查找表的每一个子表由索引表中的索引项确定。索引 项包括两个字段:关键码字段(存放对应子表中的最大关键码值) ;指针字段(存放指向对 应子表的指针) ,并且要求索引项按关键码字段有序。查找时,先用给定值kx 在索引表中 检测索引项,以确定所要进行的查找在查找表中的查找分块(由于索引项按关键码字段有序,可用顺序查找或折半查找) ,然后,再对该分块进行顺序查找。
如关键码集合为:
(22,12,13,9,20,33,42,44,38,24,48,60,58,74,49,86,53)
按关键码值31,62,88 分为三块建立的查找表及其索引表如下:

设表共n个结点,分b块,s=n/b
(分块查找索引表)平均查找长度=Log2(n/s+1)+s/2
(顺序查找索引表)平均查找长度=(S2+2S+n)/(2S)
注:
分块查找的优点是在表中插入或删除一个记录时,只要找到该记录所属块,就在该块中进行插入或删除运算(因块内无序,所以不需要大量移动记录)。它主要代价是增加一个辅助数组的存储控件和将初始表分块排序的运算。
它的性能介于顺序查找和二分查找之间。

相关文章推荐
- 数据结构修改后,序列化到本地的数据读取错误
- 【数据结构与算法】十五 平衡二叉树
- Java千百问_06数据结构(002)_java有哪8种基本数据类型
- Java千百问_06数据结构(001)_java中数据类型是什么
- springmvc中的RequestBody自动注入List, Map, String数据结构的数据
- 链表的倒序打印
- poj 初级训练计划数据结构总结
- 一、hbase的核心数据结构
- 数据结构与算法分析(1)引论
- C语言数据结构学习网站
- hdu 4193(单调队列)
- 快速排序
- delphi.数据结构.链表
- 集合框架(用LinkedList模拟栈数据结构的集合并测试案例)
- 数据结构排序算法之归并排序
- 冒泡排序
- 希尔排序
- 数据结构之字符串ADT
- 数据结构与算法——有向无环图的拓扑排序C++实现
- 排序算法性能比较练习——《数据结构、算法与应用》