第84课:StreamingContext、DStream、Receiver深度剖析
2016-04-28 09:35
190 查看
本课分成四部分讲解,第一部分对StreamingContext功能及源码剖析;第二部分对DStream功能及源码剖析;第三部分对Receiver功能及源码剖析;最后一部分将StreamingContext、DStream、Receiver结合起来分析其流程。
一、StreamingContext功能及源码剖析:1、 通过Spark Streaming对象jssc,创建应用程序主入口,并连上Driver,接收数据服务端口9999写入源数据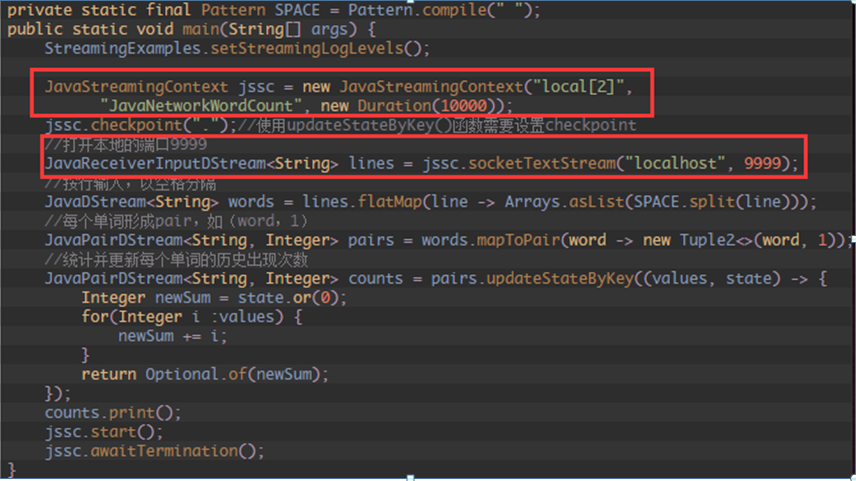
2、 Spark Streaming的主要功能有:主程序的入口;
提供了各种创建DStream的方法接收各种流入的数据源(例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等);
通过构造函数实例化Spark Streaming对象时,可以指定master URL、appName、或者传入SparkConf配置对象、或者已经创建的SparkContext对象;
将接收的数据流传入DStreams对象中;
通过Spark Streaming对象实例的start方法来启动当前应用程序的流计算框架或通过stop方法结束当前应用程序的流计算框架;

二、DStream功能及源码剖析:1、 DStream是RDD的模板,DStream是抽象的,RDD也是抽象2、 DStream的具体实现子类如下图所示:

3、 以StreamingContext实例的socketTextSteam方法为例,其执行完的结果返回DStream对象实例,其源码调用过程如下图:

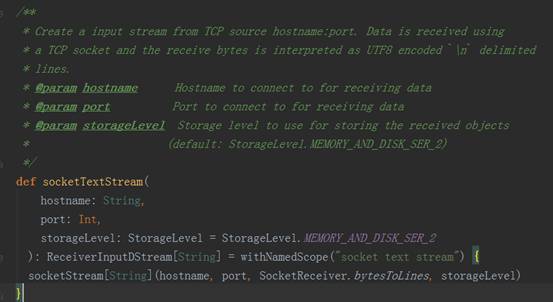
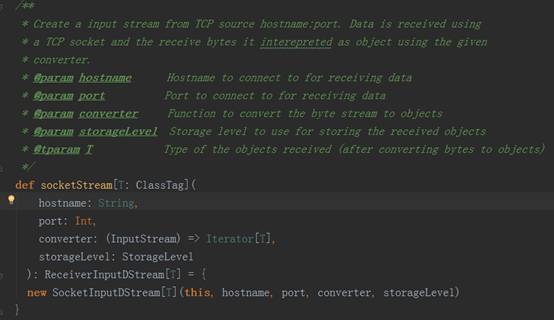
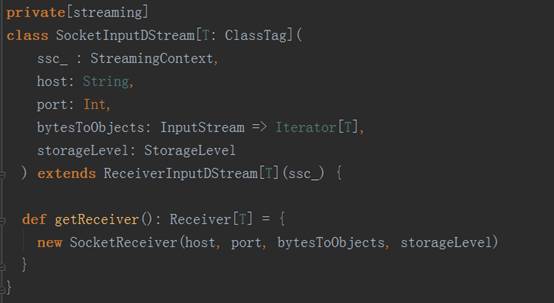
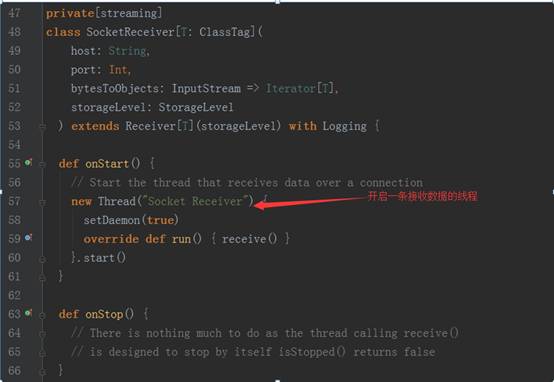
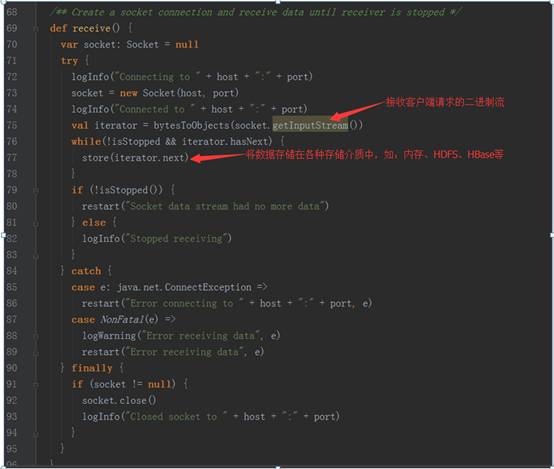
socket.getInputStream获取数据,while循环来存储数据(内存、磁盘)三、Receiver功能及源码剖析:1、Receiver代表数据的输入,接收外部输入的数据,如从Kafka上抓取数据;2、Receiver运行在Worker节点上;3、Receiver在Worker节点上抓取Kafka分布式消息框架上的数据时,具体实现类是KafkaReceiver;4、Receiver是抽象类,其抓取数据的实现子类如下图所示:
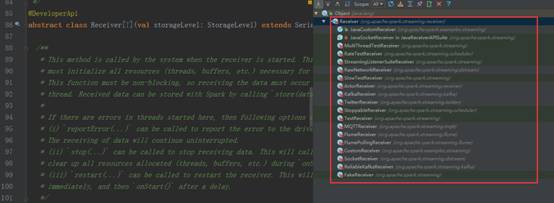
5、 如果上述实现类都满足不了您的要求,您自己可以定义Receiver类,只需要继承Receiver抽象类来实现自己子类的业务需求。四、StreamingContext、DStream、Receiver结合流程分析:
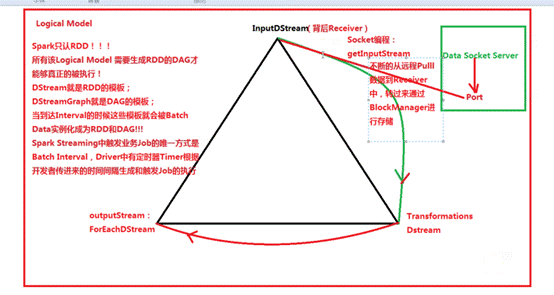
(1)inputStream代表了数据输入流(如:Socket、Kafka、Flume等)(2)Transformation代表了对数据的一系列操作,如flatMap、map等(3)outputStream代表了数据的输出,例如wordCount中的println方法:


数据在流进来之后,最终还是基于RDD进行执行,在处理流进来的数据时是DStream进行Transformation,StreamingContext会根据Transformation生成DStreamGraph,而DStreamGraph就是DAG的模板,这个模板是被框架托管的。当我们指定时间间隔的时候,Spark Streaming框架会自动触发Job,所以在开发者编写好的Spark代码时(如:flatMap、collect、print),不会导致job的运行,job运行是
Spark Streaming框架自动产生的。总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,
只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
备注:资料来源于:DT_大数据梦工厂(IMF传奇行动绝密课程)更多私密内容,请关注微信公众号:DT_Spark如果您对大数据Spark感兴趣,可以免费听由王家林老师每天晚上20:00开设的Spark永久免费公开课,地址YY房间号:68917580
相关文章推荐
- javascript prototype,executing,context,closure
- android基础教程之context使用详解
- Android编程中context及全局变量实例详解
- Android编程获取全局Context的方法
- 详解Android中的Context抽象类
- 深入解析Android App开发中Context的用法
- Python的Django框架中的Context使用
- 详解Django框架中用context来解析模板的方法
- 在Django的通用视图中处理Context的方法
- 在Django框架中编写Context处理器的方法
- eclipse 开发 spark Streaming wordCount
- Spark Streaming初探
- 如何找回Notepad++的右键菜单
- spark内存概述
- PHP使用stream_context_create()模拟POST/GET请求的方法
- Context与Application Context
- spring中context:property-placeholder/元素
- context 和 getApplicationContext()
- java中context上下探微
- javaweb域对象-ServletContext