Netty - Bytebuf(1)
2016-04-24 00:00
281 查看
Netty - ByteBuf
1.1 原生的ByteBuffer
Java NIO的ByteBuffer被称为字节缓冲区。此类针对字节缓冲区定义了以下六类操作:读写单个字节的绝对和相对 get 和 put 方法;
将此缓冲区的连续字节序列传输到数组中的相对批量 get 方法;
将 byte 数组或其他字节缓冲区中的连续字节序列传输到此缓冲区的相对批量 put 方法;
读写其他基本类型值,并按照特定的字节顺序在字节序列之间转换这些值的绝对和相对 get 和 put 方法;
创建视图缓冲区 的方法,这些方法允许将字节缓冲区视为包含其他基本类型值的缓冲区;
对字节缓冲区进行 compacting、duplicating 和 slicing 的方法。
字节缓冲区可以通过 allocation 方法创建,此方法为该缓冲区的内容分配空间,或通过 wrapping 方法将现有的 byte 数组包装到缓冲区中来创建。
1.1.1 直接与非直接缓冲区
字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则 Java 虚拟机会尽最大努力直接在此缓冲区上执行本机 I/O 操作。也就是说,在每次调用基础操作系统的一个本机 I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。非直接缓冲区写入步骤:
创建一个临时的直接ByteBuffer对象。
将非直接缓冲区的内容复制到临时缓冲中。
使用临时缓冲区执行低层次I/O操作。
临时缓冲区对象离开作用域,并最终成为被回收的无用数据。
如果采用直接缓冲区会少一次复制过程,如果需要循环使用缓冲区,用直接缓冲区可以很大地提高性能。虽然直接缓冲区使JVM可以进行高效的I/o操作,但它使用的内存是操作系统分配的,绕过了JVM堆栈,建立和销毁比堆栈上的缓冲区要更大的开销。
1.1.2 视图缓冲区
ByteBuffer类的视图与它所基于的ByteBuffer类的对象之间的关系类似于过滤流和它所包装的流的关系。最常见的ByteBuffer类的视图是转换成对基本数据类型进行操作的缓冲区对象。这些缓冲区包括CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer和DoubleBuffer等Java类。如asIntBuffer方法在当前ByteBuffer类的对象的基础上创建一个新的IntBuffer类的视图。新创建的视图和原始的ByteBuffer类的对象所共享的不一定是全部的空间,而只是从ByteBuffer类的对象中的当前读写位置到读写限制之间的可用空间。在这个空间范围内,不论是在ByteBuffer类的对象中还是在作为视图的新缓冲区中,对数据所做的修改,对另一个来说都是可见的。除了数据本身之外,两者的读写位置、读写限制和标记位置等都是相互独立的。1.1.3 API
public static ByteBuffer allocateDirect(int capacity)分配新的直接字节缓冲区。
新缓冲区的位置(position)将为零,其界限(limit)将为其容量(capacity),其标记(mark)是不确定的。无论它是否具有底层实现数组,其标记都是不确定的。
public static ByteBuffer allocate(int capacity)
分配一个新的字节缓冲区(非直接)。
新缓冲区的位置将为零,其界限将为其容量,其标记是不确定的。它将具有一个底层实现数组,且其 数组偏移量将为零。

public static ByteBuffer wrap(byte[] array)
将 byte 数组包装到缓冲区中。
新的缓冲区将由给定的 byte 数组支持;也就是说,缓冲区修改将导致数组修改,反之亦然。新缓冲区的容量和界限将为 array.length,其位置将为零,其标记是不确定的。其底层实现数组将为给定数组,并且其数组偏移量将为零。
public static ByteBuffer wrap(byte[] array,
int offset,
int length)
将 byte 数组包装到缓冲区中。
新的缓冲区将由给定的 byte 数组支持;也就是说,缓冲区修改将导致数组修改,反之亦然。新缓冲区的容量将为 array.length,其位置将为 offset,其界限将为 offset + length,其标记是不确定的。其底层实现数组将为给定数组,并且其数组偏移量将为零。

public abstract ByteBuffer slice()
创建新的字节缓冲区,其内容是此缓冲区内容的共享子序列。
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数量,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
bytebuffer2 = byteBuffer1.slice();

public abstract ByteBuffer duplicate()
创建共享此缓冲区内容的新的字节缓冲区。
新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。

public abstract ByteBuffer asReadOnlyBuffer()
创建共享此缓冲区内容的新的只读字节缓冲区。
新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,但新缓冲区将是只读的并且不允许修改共享内容。两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。
如果此缓冲区本身是只读的,则此方法与 duplicate 方法完全相同。
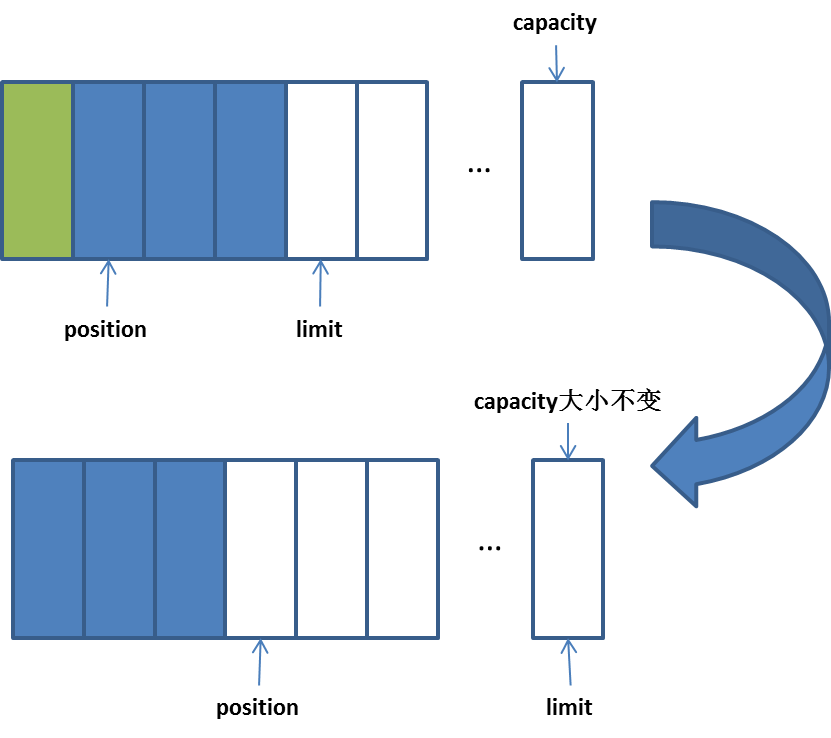
public void flip()
其实就是修改position,limit实现写模式向读模式转换。

public abstract ByteBuffer compact()
压缩此缓冲区(可选操作)。
将缓冲区的当前位置和界限之间的字节(如果有)复制到缓冲区的开始处。即将索引 p = position() 处的字节复制到索引 0 处,将索引 p + 1 处的字节复制到索引 1 处,依此类推,直到将索引 limit() - 1 处的字节复制到索引 n = limit() - 1 - p 处。然后将缓冲区的位置设置为 n+1,并将其界限设置为其容量。如果已定义了标记,则丢弃它。
将缓冲区的位置设置为复制的字节数,而不是零,以便调用此方法后可以紧接着调用另一个相对 put 方法。
相当于切换回读模式:

相关文章推荐
- Netty - ByteBuf (3)
- Riak - 背景篇(2)
- MyCat - 源代码篇(1)
- MyCat - 使用篇(4)
- [转载]微服务实践(五):微服务的事件驱动数据管理
- MyCat - 使用篇(2)
- MyCat - 源代码篇(6)
- Java 7新特性总结 - Java IO
- Canal+Otter - Canal篇(1)
- [转载]微服务实战(四):服务发现的可行方案以及实践案例
- MySQL通信协议栈Java实现-(2)协议包格式
- 正则表达式
- Zookeeper - 开发篇(1)
- Zookeeper - 部署篇
- MyCat - 测试篇
- Java 7新特性总结 - Coin项目新语言特性
- MyCat - 背景篇(1)
- MyCat - 背景篇(2)
- fileUpload文件上传框架组件
- java线程中断处理