列表解析及生成器表达式的效率问题
2016-04-18 05:48
423 查看
列表解析(List Comprehensions),来自函数式的编程语言Haskell。是一个非常有用,简单而且灵活的工具,可以动态地创建列表。自Python2.0,列表开始加入到Python中,里面有lambda,map,filter等,使Python具备一个很重要的功能:函数式编程。使Python语言有了个革命性的发展.也提供用户一个强大工具,只用一行代码就可以创建包含特定内容的列表。
其基本格式:
[expr
for item in iterable if
condition]
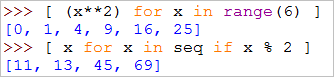
比如下面两个例子,即可以用map, filter等来实现

也可以使用列表解析来实现
列表解析的一个不足就是必要生成所有的数据,用以创建整个列表。这可能对有大量数据的迭代器有负面效应,存在严重效率问题.生成器表达式自Python2.4被引入,与列表解析非常相似,语法也相似。不过它不会真正创建数字列表,而是返回一个生成器,这个生成器在每次计算出一条数据后,把这条数据yield(产生)出来,生成器表达式使用了lazy
evaluation(延迟计算),所以它在内存使用上更有效。生成器表达式格式:
(expr for item
in iterable if condition)
下面举个例子来说明:
【测试文件】
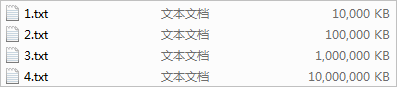
准备了四个文件: 1.txt 2.txt 3.txt 4.txt
文件大小分别为: 10M 100M 1G 10G
【测试内容】测试上述四个文件所有非空字符的数目
【测试项目】列表解析
VS 生成器表达式
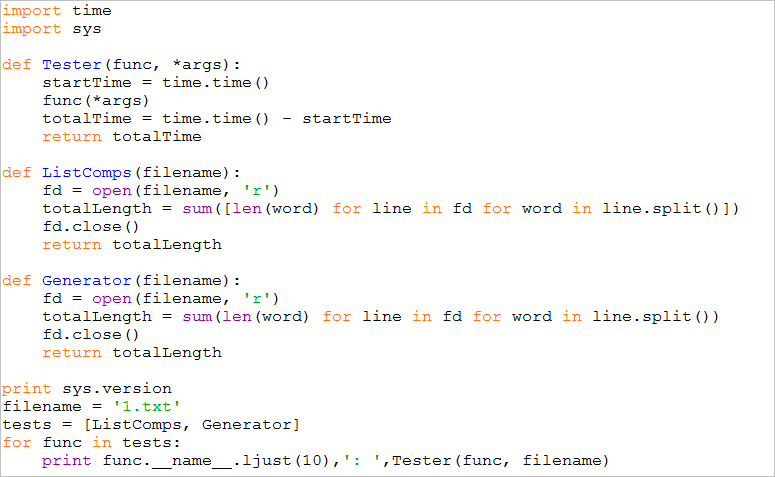
【测试脚本】
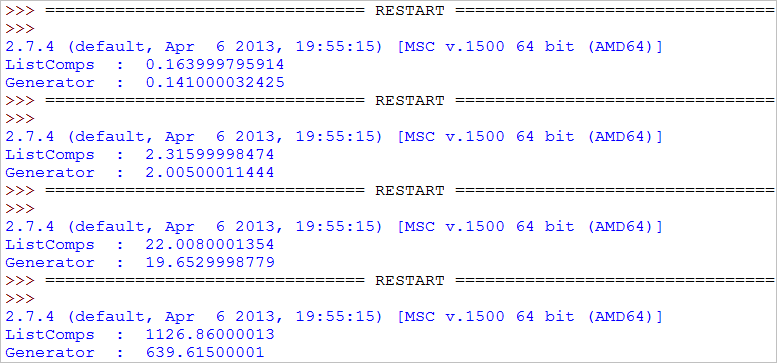
【测试结果】
【测试分析】
1. 当数据比较小时,使用生成器表达式所耗时间比列表解析要稍微快些
2. 当数据比较大时,比如接近PC机内存的总量时,用后者速度要快的多!
其基本格式:
[expr
for item in iterable if
condition]
比如下面两个例子,即可以用map, filter等来实现
也可以使用列表解析来实现
列表解析的一个不足就是必要生成所有的数据,用以创建整个列表。这可能对有大量数据的迭代器有负面效应,存在严重效率问题.生成器表达式自Python2.4被引入,与列表解析非常相似,语法也相似。不过它不会真正创建数字列表,而是返回一个生成器,这个生成器在每次计算出一条数据后,把这条数据yield(产生)出来,生成器表达式使用了lazy
evaluation(延迟计算),所以它在内存使用上更有效。生成器表达式格式:
(expr for item
in iterable if condition)
下面举个例子来说明:
【测试文件】
准备了四个文件: 1.txt 2.txt 3.txt 4.txt
文件大小分别为: 10M 100M 1G 10G
【测试内容】测试上述四个文件所有非空字符的数目
【测试项目】列表解析
VS 生成器表达式
【测试脚本】
【测试结果】
【测试分析】
1. 当数据比较小时,使用生成器表达式所耗时间比列表解析要稍微快些
2. 当数据比较大时,比如接近PC机内存的总量时,用后者速度要快的多!

相关文章推荐
- leetcode 21. Merge Two Sorted Lists
- 58. Length of Last Word
- leetcode 23. Merge k Sorted Lists(堆||分治法)
- Remove the duplicates from sorted array
- MySQL没有 data 目录的解决方法
- 编写递归函数来使字符串逆序
- My new personal homepage
- 函数的调用原理——栈桢
- 打开了曾经作为程序员的编程博客,心中多少有些怀念程序中的
- 【Leetcode】8.String to Integer (atoi) 解题
- 批量检查代理ip是否可用 curl-multi php检测ip代理是否有效
- 人工智能60年:智能机器是什么?
- win32程序中调用控制台程序
- 谷歌的绩效管理
- bdwk标题
- Android——黑名单管理(二)
- 清除NT Kernel占用80端口
- C/C++系列之如何实现一个avi格式的播放器
- 【Leetcode】7.Reverse Integer 解题
- windows编程之音频设备的捕获