Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
2016-04-17 16:37
537 查看
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法
有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/,然后右击空白处,选择“查看网页源代码”,如下所示:
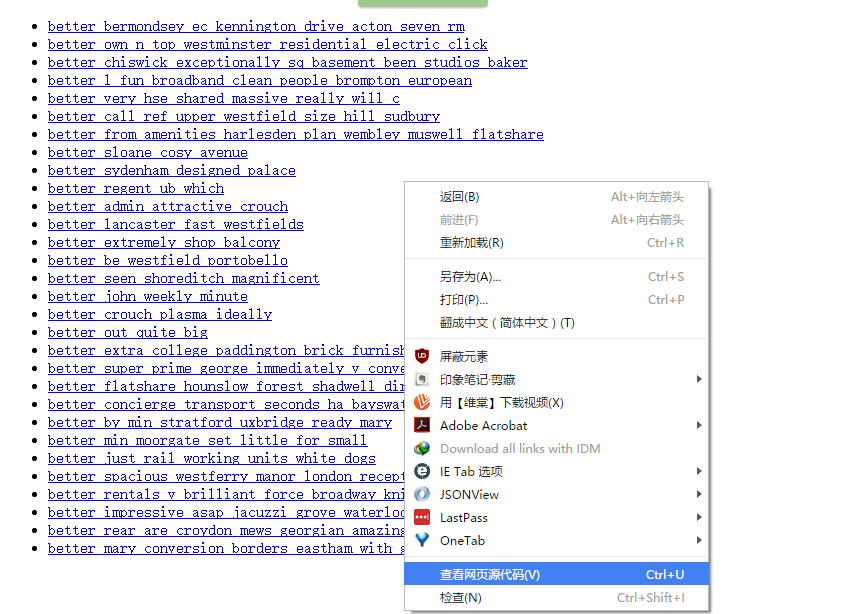
就会发现一片空白

留意到红线处指定了一个名为api.json的文件,于是打开浏览器的调试器中的Network面板,找到名为api.json的标签
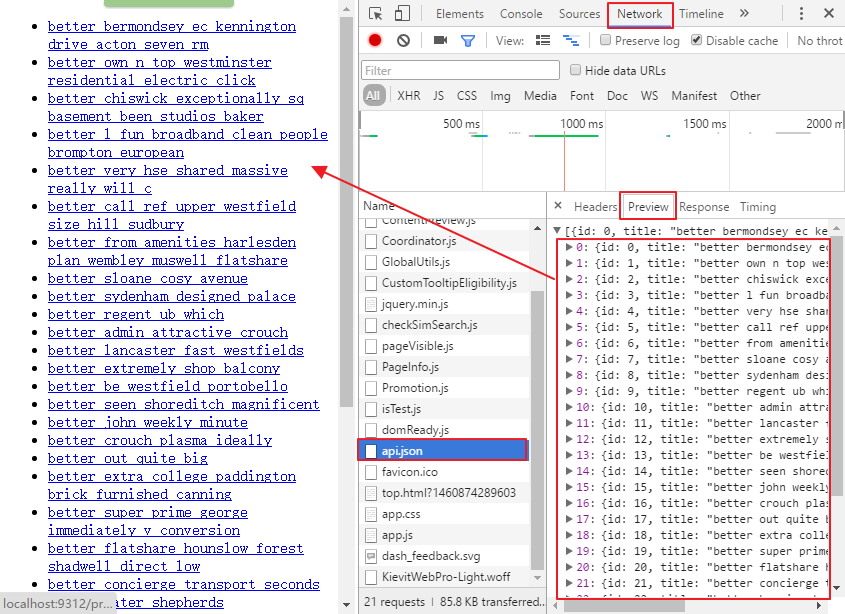
在上图的红色框里就找到了原网页中的内容,这是一个简单的JSON API,有些复杂的API会要求你先登录,发送POST请求,或者返回一些更加有趣的数据结构。Python提供了一个用于解析JSON的库,可以通过语句json.loads(response.body)将JSON数据转变成Python对象
api.py文件的源代码地址:
https://github.com/Kylinlin/scrapybook/blob/master/ch05%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,做以下改动:
将spider名修改为api
将start_urls修改为JSON API的URL,如下
如果在获取这个json的api之前,需要登录,就使用start_request()函数(参考《Learning Scrapy笔记(五)- Scrapy登录网站》)
修改parse函数
上面的js变量是一个列表,每个元素都代表了一个条目,可以使用scrapy shell工具来验证:
有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/,然后右击空白处,选择“查看网页源代码”,如下所示:
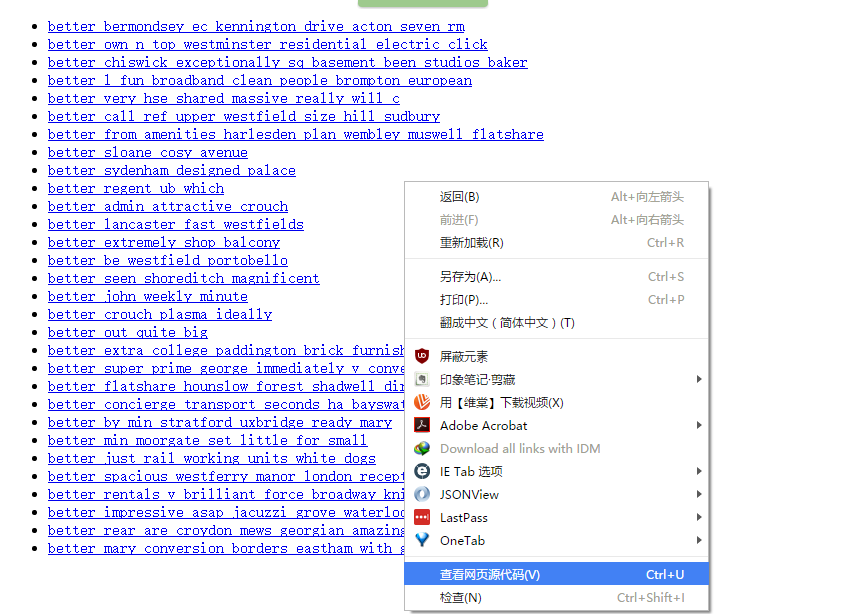
就会发现一片空白

留意到红线处指定了一个名为api.json的文件,于是打开浏览器的调试器中的Network面板,找到名为api.json的标签
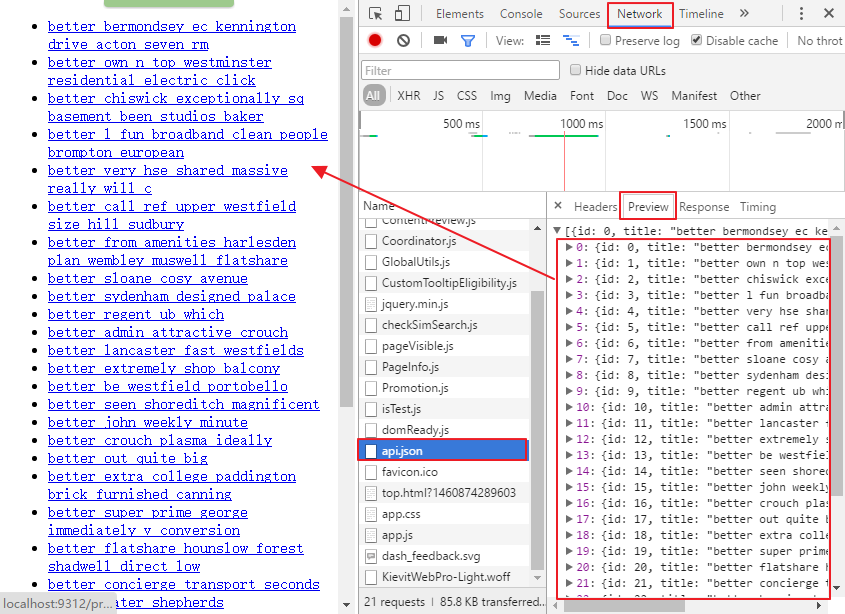
在上图的红色框里就找到了原网页中的内容,这是一个简单的JSON API,有些复杂的API会要求你先登录,发送POST请求,或者返回一些更加有趣的数据结构。Python提供了一个用于解析JSON的库,可以通过语句json.loads(response.body)将JSON数据转变成Python对象
api.py文件的源代码地址:
https://github.com/Kylinlin/scrapybook/blob/master/ch05%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,做以下改动:
将spider名修改为api
将start_urls修改为JSON API的URL,如下
start_urls = ( 'http://web:9312/properties/api.json', )
如果在获取这个json的api之前,需要登录,就使用start_request()函数(参考《Learning Scrapy笔记(五)- Scrapy登录网站》)
修改parse函数
def parse(self, response): base_url = "http://web:9312/properties/" js = json.loads(response.body) for item in js: id = item["id"] url = base_url + "property_%06d.html" % id # 构建一个每个条目的完整url yield Request(url, callback=self.parse_item)
上面的js变量是一个列表,每个元素都代表了一个条目,可以使用scrapy shell工具来验证:
scrapy shell http://web:9312/properties/api.json[/code]
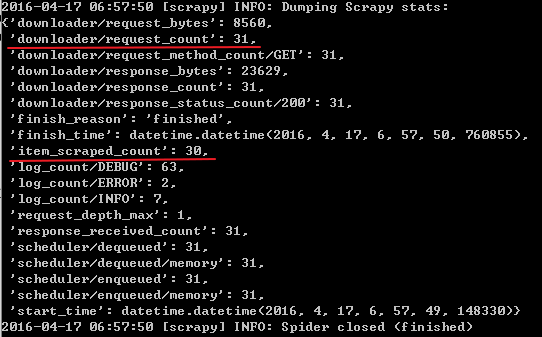
运行该spider:scrapy crawl api
可以看到总共发送了31个request,获取了30个item
再观察上图中使用scrapy shell工具检查js变量的图,其实除了id字段外,还可以获取title字段,所以可以在parse函数中同时获取title字段,并将该字段的值传送到parse_item函数中填充到item里(省去了在parse_item函数中使用xpath来提取title的步骤),修改parse函数如下:title = item["title"] yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,可以在response中提取这个字段l.add_value('title', response.meta['title'], MapCompose(unicode.strip, unicode.title))


相关文章推荐
- javascript中textContent与innerText的异同分析
- js 实现图片自动移动
- js 实现图片位置随意变化
- js--继承
- JS学习3(变量、作用域和内存)
- 【 D3.js 入门系列 --- 2 】 怎样使用数据和选择元素
- 关于js对象属性
- 堆优化 Dijstra单源最短路径算法 2(邻接表)
- js keyup、keypress和keydown事件 详解
- js笔记
- JS区分浏览器页面是刷新还是关闭
- Json----Jackson 下载地址
- javascript VS java
- js组件SlotMachine实现图片切换效果制作抽奖系统
- JSP原理和语法
- move.js
- jsp页面中的EL表达式不被解析的问题
- js实现鼠标监听
- JS中取二维数组中最大值的方法汇总
- 最简单js代码实现select二级联动下拉菜单