最近在处理Cocoa NSString时, 遇到一些字符编码的问题
2016-04-14 15:16
651 查看
最近在处理Cocoa NSString时, 遇到一些字符编码的问题, 从而引出一个遍历NSString每一个字符的"正确"方式! 很有趣.
NSString是UTF-16编码的, 也就是16位的unichar字符的序列. 所以, 一般遍历其每一个字符的方法就是:
但是, 我们平常书写的字符, 并不全部都是用唯一的一个16位字符来表示, 而是有一部分用两个16位字符来表示, 这就是surrogate pairs的概念. 如果还是用上面的方法遍历字符串, 就会出现"断字". 例如图中这个Apple Color Emoji的"THUMBS UP SIGN"字符, 其实是用2个16位unichar来表示, 它的Unicode是U+1F44D, 用(U+D83D U+DC4D)两个字符来表示.
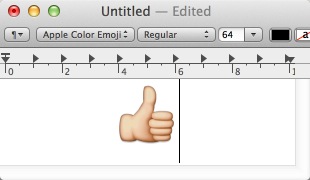
还好, NSString的
一次遍历一个子串, 而不是遍历一个unichar了.
相关资料:
Wikipedia: UTF-16
Apple开发者文档:
Characters and Grapheme Clusters
iOS 正确接收 HTTP chunked 数据的方法
Cpy是如何打败Python的
SSDB存储集群
通过 HTTP POST 发送二进制数据
Posted by ideawu at 2013-06-12 12:26:39
NSString是UTF-16编码的, 也就是16位的unichar字符的序列. 所以, 一般遍历其每一个字符的方法就是:
for(int i=0; i<str.length; i++){
unichar ch = [str characterAtIndex: i];
}但是, 我们平常书写的字符, 并不全部都是用唯一的一个16位字符来表示, 而是有一部分用两个16位字符来表示, 这就是surrogate pairs的概念. 如果还是用上面的方法遍历字符串, 就会出现"断字". 例如图中这个Apple Color Emoji的"THUMBS UP SIGN"字符, 其实是用2个16位unichar来表示, 它的Unicode是U+1F44D, 用(U+D83D U+DC4D)两个字符来表示.
还好, NSString的
rangeOfComposedCharacterSequencesForRange:和
rangeOfComposedCharacterSequenceAtIndex:两个方法可以用来处理这种情况. 所以, 真正正确的遍历NSString的每一个字符的方法就是这样了:
NSRange range;
for(int i=0; i<str.length; i+=range.length){
range = [str rangeOfComposedCharacterSequenceAtIndex:i];
NSString *s = [str attributedSubstringFromRange:range];
}一次遍历一个子串, 而不是遍历一个unichar了.
相关资料:
Wikipedia: UTF-16
Apple开发者文档:
Characters and Grapheme Clusters
Related posts:
JavaScript+CSS实现数据表格条纹iOS 正确接收 HTTP chunked 数据的方法
Cpy是如何打败Python的
SSDB存储集群
通过 HTTP POST 发送二进制数据
Posted by ideawu at 2013-06-12 12:26:39

相关文章推荐
- ubunbu 12.04中安装xrdp建立远程桌面
- iOS开发系列--音频播放、录音、视频播放、拍照、视频录制
- NKWebView的简单使用
- [Magento SQL] 返回产品SKU,Stutus(上下架状态)和库存
- ActionInvocation的理解
- Windows 10 LNK File分析
- 【bzoj2834】【回家的路】【最短路】
- iOS label自适应宽度 左端对齐 自动换行
- Maven---入门
- ZZULIOJ-1876 礼上往来(全错位排列)
- 线程-001-线程简介
- 强化学习笔记1
- js时间段判断的函数
- 更新table1字段b的值为原值拼接table2的b字段的值
- PopupWindow不设置背景,弹窗不消失,但是事件向下传递
- 深度理解spring的IOC
- SpringMVC中拦截器的使用
- 兼容性问题
- scala知识点(一)
- 原生js实现autocomplete插件