Python语法点滴
2016-04-14 14:29
375 查看
格式化字符串转换成字典问题: “a=1,b=2,c=3”要转换成字典: { ‘a’:1, ‘b’:2, ‘c’:3} 有什么方便快捷的方法呢? 解答: s = 'a=1,b=2,c=3' dict((l.split('=') for l in s.split(','))) 如果 要把value转换成int型的 d = dict(((lambda i: (i[0], int(i[1])))(l.split('=')) for l in s.split(','))) http://www.360doc.com/content/15/0331/11/5711743_459502912.shtml |
| string: string.capitalize() 把字符串的第一个字符大写 string.startswith(obj) string.endswith(obj) string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 [b]string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常. [b]string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 string.lower() string.upper() [b]string.strip([obj]) string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())[/b][/b][/b] |
| List 函数: len() max() min() list(seq) 方法: list.append(obj) list.extend(seq) list.count(obj) list.index(obj) list.insert(index, obj) list.pop(obj=list[-1]) list.remove(obj) list.reverse() == list[::-1]Tuple只有对应的函数,最后一个为tuple(seq) |
| 字典 radiansdict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里del adict[key] |
| set set.add(key) set.remove(key) set1 & set2 set1 | set2 |
函数def add_end(L=[]):
L.append('END')
return L>>> add_end() ['END'] >>> add_end() ['END', 'END'] 原因解释如下:Python函数在定义的时候,默认参数 L的值就被计算出来了,即 [],因为默认参数 L也是一个变量,它指向对象 [],每次调用该函数,如果改变了 L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的 []了。所以,定义默认参数要牢记一点:默认参数必须指向不变对象!可变参数:在函数内部,参数 numbers接收到的是一个tuple def calc(*numbers): sum = 0 for n in numbers: sum = sum + n * n return sum >>> nums = [1, 2, 3] >>> calc(*nums) 关键字参数 def func(a, b, c=0, *args, **kw): print 'a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw >>> args = (1, 2, 3, 4)
>>> kw = {'x': 99}
>>> func(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'x': 99}所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。 |
enumerate >>> for i, value in enumerate(['A', 'B', 'C']): ... print i, value ... 0 A 1 B 2 CIn [15]: range(4) Out[15]: [0, 1, 2, 3] |
map reduce filter>>> def f(x): ... return x * x ... >>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) [1, 4, 9, 16, 25, 36, 49, 64, 81]reduce把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是: reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4) filter()把传入的函数依次作用于每个元素,然后根据返回值是 True还是 False决定保留还是丢弃该元素 def is_odd(n): return n % 2 == 1 filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]) # 结果: [1, 5, 9, 15] |
| 排序sorted(iterable, cmp=None, key=None, reverse=False) >>>L = [('b',2),('a',1),('c',3),('d',4)] >>>print sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) [('a', 1), ('b', 2), ('c', 3), ('d', 4)]>>>print sorted(L, key=lambda x:x[1])) [('a', 1), ('b', 2), ('c', 3), ('d', 4)]注:效率key>cmp(key比cmp快)在Sorting Keys中:我们看到,此时排序过的L是仅仅按照第二个关键字来排的,如果我们想用第二个关键字 排过序后再用第一个关键字进行排序呢? >>> L = [('d',2),('a',4),('b',3),('c',2)] >>> print sorted(L, key=lambda x:(x[1],x[0])) >>>[('c', 2), ('d', 2), ('b', 3), ('a', 4)] 字典排序按value排序 sorted(dict.items(), lambda x, y: cmp(x[1], y[1])) #降序 sorted(dict.items(), lambda x, y: cmp(x[1], y[1]), reverse=True) |
获取对象信息>>> import types
>>> type('abc')==types.StringType
True
>>> type(u'abc')==types.UnicodeType
True
>>> type([])==types.ListType
True
>>> type(str)==types.TypeType
Trueisinstance() >>> isinstance('a', str)
True
>>> isinstance(u'a', unicode)
True
>>> isinstance('a', unicode)
False |
| collections https://docs.python.org/2/library/collections.htmlnamedtuple >>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2OrderedDict >>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])Counter Counter实际上也是 dict的一个子类 |
| 多进程import signalfrom multiprocessing import cpu_count, Pool CPU_COUNT = cpu_count()def init_worker(): signal.signal(signal.SIGINT, signal.SIG_IGN)# 需要返回结果用mappool = Pool(processes=CPU_COUNT, initializer=init_worker, maxtasksperchild=400) return_list = pool.map(func, iterable_object) pool.close() pool.join()#不需要返回结果用apply_asyncpool = Pool(processes=CPU_COUNT, initializer=init_worker, maxtasksperchild=400) for filename in train_label2['md5']: pool.apply_async(cp_test_file, (filename,)) pool.close() pool.join()多线程 import Queue import threading class WorkManager(object): def __init__(self, start_id, end_id, thread_num=20): self.work_queue = Queue.Queue() self.threads = [] self.__init_work_queue(start_id, end_id) self.__init_thread_pool(thread_num) def __init_thread_pool(self, thread_num): for i in range(thread_num): self.threads.append(Work(self.work_queue)) def __init_work_queue(self, start_id, end_id): for i in range(start_id, end_id + 1): # 任务入队,Queue内部实现了同步机制 self.work_queue.put((get_sig_1, i)) def wait_allcomplete(self): for item in self.threads: if item.isAlive(): item.join() class Work(threading.Thread): def __init__(self, work_queue): threading.Thread.__init__(self) self.work_queue = work_queue self.start() def run(self): # 死循环,从而让创建的线程在一定条件下关闭退出 while True: try: do, args = self.work_queue.get(block=False) # 任务异步出队,Queue内部实现了同步机制 do(args) self.work_queue.task_done() # 通知系统任务完成 except: break |
| logging import logging.handlerslog = logging.getLogger() formatter = logging.Formatter("%(asctime)s [%(name)s] %(levelname)s: %(message)s") fh = logging.handlers.WatchedFileHandler(os.path.join(root_dir, 'pe_analyzer.log')) fh.setFormatter(formatter) log.addHandler(fh) ch = logging.StreamHandler() ch.setFormatter(formatter) log.addHandler(ch) log.setLevel(logging.INFO) log.info('imp_x.shape: %s, ops_x.shape: %s, imp_y.shape: %s' % (imp_x.shape, ops_x.shape, imp_y.shape)) log.info('train_label.shape: %s', train_label.shape) |
二维数组拉平成一维数组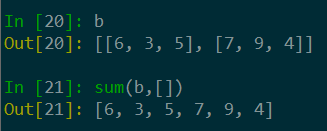 |

相关文章推荐
- Python 特殊语法:filter、map、reduce、lambda
- dnspod 动态域名更新客户端 in python
- python下划线变量的含义
- Python3:re.complie用法
- 安装PIL,注册表不能识别Python2.7
- Selenium2 Python 自动化测试实战学习笔记(四)
- Python教程11-14
- Python报错UnicodeDecodeError: ascii codec can t deco
- Python教程8-10
- python学习笔记(excel中处理日期格式)
- Python不同版本切换
- 更新Python以及随后的nose,easy_install,pip,numpy,scipy和theano
- 第六篇——初尝Python,意犹未尽
- Python CPU,内存实时获取
- Python爬虫爬验证码实现功能详解
- Python 迭代器工具包
- 【Python数据分析】四级成绩分布 -matplotlib,xlrd 应用
- Python基础入门
- python 解释器内建函数001
- Python Pymongo中Connection()与MongoClient()差异