MapReduce
2016-04-14 14:24
183 查看
MapReduce框架有效地解决了海量数据的离线批处理问题,在各大互联网公司得到广泛的应用。事实已经证明了MapReduce的巨大影响力,以至于引发了一系列的扩展和改进。
MapReduce框架包含三种角色:主控进程(Master)用于执行任务划分、调度、任务之间的协调等;Map工作进程(Map Worker,简称Map进程)以及Reduce工作进程(Reduce Worker,简称Reduce进程)分别用于执行Map任务和Reduce任务。
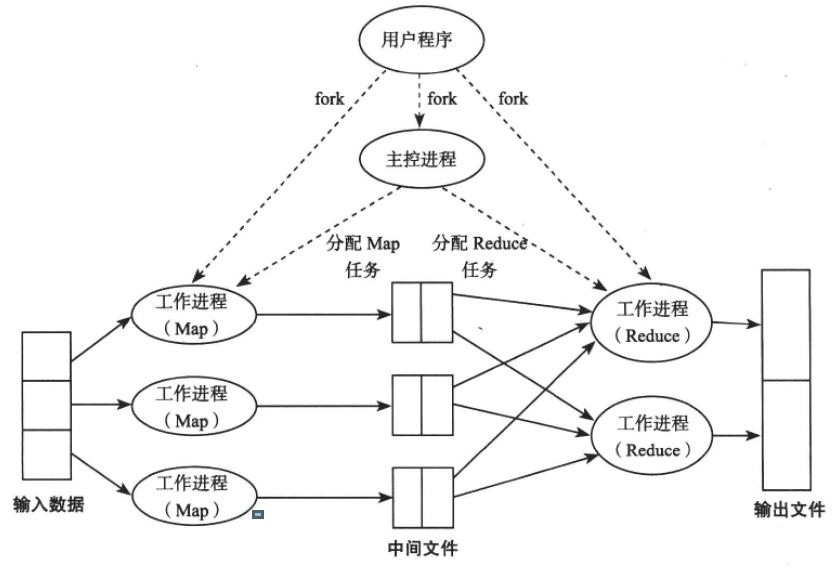
MapReduce任务执行流程如下:
1)首先从用户提交的程序fork出主控进程,主控进程启动后将切分任务并根据输入文件所在的位置和集群信息选择机器fork出Map或者Reduce进程;用户提交的程序可以根据不同的命令行参数执行不同的行为。
2)主控进程将切分好的任务分配给Map进程和Reduce进程执行,任务切分和任务分配可以并行执行。
3)Map进程执行Map任务:读取相应的输入文件,根据指定的输入格式不断读取key,valu对并对每一个key,value对执行用户自定义的Map函数。
4)Map进程执行用户定义的Map函数:不断地往本地内存缓冲区输出中间key,value对结果,等到缓冲区超过一定大小时写入到本地磁盘中。Map进程根据分割(partition)函数将中间结果组成R份,便于后续Reduce进程获取。
5)Map任务执行完成时,Map进程通过心跳向主控进程汇报,主控进程进一步将该信息通知Reduce进程。Reduce进程向Map进程请求传输生成的中间结果数据。这个过程称为Shuffle。当Reduce进程获取完所有的Map任务生成的中间结果时,需要进行排序操作。
6)Reduce进程执行Reduce任务:对中间结果的每一个相同的key及value集合,执行用户自定义的Reduce函数。Reduce函数的输出结果被写入到最终的输出结果,例如分布式文件系统Google File System或者分布式表格系统Bigtable。
MapReduce框架实现时主要做了两点优化:
1)本地化:尽量将任务分配给离输入文件最近的Map进程,如同一台机器或者同一个机架。通过本地化策略,能够大大减少传输的数据量。
2)备份任务:如果某个Map或者Reduce任务执行时间较长,主控进程会生成一个该任务的备份并分配给另外一个空闲的Map或者Reduce进程。在大集群环境下,即使所有的机器配置相同,机器的负载不同也会导致处理能力相差很大,通过备份任务减少“拖后腿”的任务,从而降低整个作业的总体执行时间。
MapReduce框架包含三种角色:主控进程(Master)用于执行任务划分、调度、任务之间的协调等;Map工作进程(Map Worker,简称Map进程)以及Reduce工作进程(Reduce Worker,简称Reduce进程)分别用于执行Map任务和Reduce任务。
MapReduce任务执行流程如下:
1)首先从用户提交的程序fork出主控进程,主控进程启动后将切分任务并根据输入文件所在的位置和集群信息选择机器fork出Map或者Reduce进程;用户提交的程序可以根据不同的命令行参数执行不同的行为。
2)主控进程将切分好的任务分配给Map进程和Reduce进程执行,任务切分和任务分配可以并行执行。
3)Map进程执行Map任务:读取相应的输入文件,根据指定的输入格式不断读取key,valu对并对每一个key,value对执行用户自定义的Map函数。
4)Map进程执行用户定义的Map函数:不断地往本地内存缓冲区输出中间key,value对结果,等到缓冲区超过一定大小时写入到本地磁盘中。Map进程根据分割(partition)函数将中间结果组成R份,便于后续Reduce进程获取。
5)Map任务执行完成时,Map进程通过心跳向主控进程汇报,主控进程进一步将该信息通知Reduce进程。Reduce进程向Map进程请求传输生成的中间结果数据。这个过程称为Shuffle。当Reduce进程获取完所有的Map任务生成的中间结果时,需要进行排序操作。
6)Reduce进程执行Reduce任务:对中间结果的每一个相同的key及value集合,执行用户自定义的Reduce函数。Reduce函数的输出结果被写入到最终的输出结果,例如分布式文件系统Google File System或者分布式表格系统Bigtable。
MapReduce框架实现时主要做了两点优化:
1)本地化:尽量将任务分配给离输入文件最近的Map进程,如同一台机器或者同一个机架。通过本地化策略,能够大大减少传输的数据量。
2)备份任务:如果某个Map或者Reduce任务执行时间较长,主控进程会生成一个该任务的备份并分配给另外一个空闲的Map或者Reduce进程。在大集群环境下,即使所有的机器配置相同,机器的负载不同也会导致处理能力相差很大,通过备份任务减少“拖后腿”的任务,从而降低整个作业的总体执行时间。

相关文章推荐
- 插件管理框架 for Delphi(一)
- 使用CSS框架布局的缺点和优点小结
- 基于.NET平台常用的框架和开源程序整理
- 列举PHP的Yii 2框架的开发优势
- Windows窗体的.Net框架绘图技术实现方法
- 浅谈JavaScript 框架分类
- 轻量级javascript 框架Backbone使用指南
- javascript实现框架高度随内容改变的方法
- JS刷新框架外页面七种实现代码
- 超赞的动手创建JavaScript框架的详细教程
- 深入探讨前端框架react
- 简单介绍不用库(框架)自己写ajax
- asp.net4.0框架下验证机制失效的原因及处理办法
- 插件管理框架 for Delphi(二)
- 零基础学习AJAX之AJAX框架
- Ajax 框架学习笔记
- Flex中最好的MVC框架Mate框架
- JavaScript 异步调用框架 (Part 4 - 链式调用)
- JavaScript 异步调用框架 (Part 2 - 用例设计)
- 为什么使用框架 使用框架的优缺点