天池新人实战赛----阿里移动推荐算法大赛(离线赛与平台赛)
2016-04-13 17:04
435 查看
平台赛最终成绩5/1629,算是没辜负我这10天的付出吧。。。我要去玩有奖金的了0.0
想快速入门,请戳这:机器学习入门----以阿里移动推荐算法大赛为例(较详细)
竞赛题目 (离线赛与平台赛题目一样,只是数据量不一样,离线2000w+条数据,平台11亿+条数据)
在真实的业务场景下,我们往往需要对所有商品的一个子集构建个性化推荐模型。在完成这件任务的过程中,我们不仅需要利用用户在这个商品子集上的行为数据,往往还需要利用更丰富的用户行为数据。定义如下的符号:U——用户集合
I——商品全集
P——商品子集,P ⊆ I
D——用户对商品全集的行为数据集合
商品子集都是偏服务类的商品,涵盖阿里巴巴集团十个主要的商品大类,例如汽车售后服务、摄影服务、餐饮、电影等,其特色是线上购买、线下服务。
那么我们的目标是利用D来构造U中用户对P中商品的推荐模型。
数据说明
本场比赛提供20000用户的完整行为数据以及百万级的商品信息。竞赛数据包含两个部分。
第一部分是用户在商品全集上的移动端行为数据(D),表名为tianchi_fresh_comp_train_user_2w,包含如下字段:
| 字段 | 字段说明 | 提取说明 |
| user_id | 用户标识 | 抽样&字段脱敏 |
| item_id | 商品标识 | 字段脱敏 |
| behavior_type | 用户对商品的行为类型 | 包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4。 |
| user_geohash | 用户位置的空间标识,可以为空 | 由经纬度通过保密的算法生成 |
| item_category | 商品分类标识 | 字段脱敏 |
| time | 行为时间 | 精确到小时级别 |
| 字段 | 字段说明 | 提取说明 |
| item_id | 商品标识 | 抽样&字段脱敏 |
| item_ geohash | 商品位置的空间标识,可以为空 | 由经纬度通过保密的算法生成 |
| item_category | 商品分类标识 | 字段脱敏 |
有了新想法我先在离线赛上实验,成绩有提升我才去平台赛,不过也遇到一些问题,在hive里运行一点问题没有的SQL语句,到了ODPS里就不能用,有很多限制,毕竟数据量大了好几个数量级,处理起来很费资源,不能那么随意的写了。
刚开始没理解题意,我还纳闷为啥给两张表= =
U——用户集合
I——商品全集
P——商品子集,P ⊆ I
D——用户对商品全集的行为数据集合
那么我们的目标是利用D来构造U中用户对P中商品的推荐模型
让我们预测的是用户会购买商品子集里的哪些商品,不是所有的商品。
提示:根据评分规则可以找到一些讨巧的办法~
刚开始没理解题意,提交的结果F1值极低。
[b]去掉非P中商品之后,F1值咔咔的上去了。然后我就赶紧去平台赛了~
[/b]
平台赛
去除非P中商品之后,F1值咔咔的上去了。

快进前50了!

前50了!

借鉴了李强大神团队的PPT,用了GBDT迭代决策树

直接第6了!


前五了!

--odps sql --********************************************************************-- --author:断线纸鸢自由 --create time:2016-04-12 15:12:09 --******************************************************************** describe tianchi_data.tianchi_fresh_comp_train_user_online; Create table tianchi_fresh_comp_train_item as select * from tianchi_data.tianchi_fresh_comp_train_item_online; Create table tianchi_fresh_comp_train_user as select * from tianchi_data.tianchi_fresh_comp_train_user_online; 。。。。。。
我QQ:728972837
离线赛

快到前100了!

前100了!

day3.hql
create external table tianchi_fresh_comp_train_item(item_id string,item_geohash string,item_category string) row format delimited fields terminated by ',' location '/tianchilxitem'; create external table tianchi_fresh_comp_train_user(user_id string,item_id string,behavior_type bigint,user_geohash string,item_category string,time string) row format delimited fields terminated by ',' location '/tianchilx';
hive> source /home/guo/day3.hql;PS:Hive几种导出数据方式
我QQ:728972837
补充:
下文中的准确率其实是精确率,他弄混了!
建议先看这篇:准确率(Accuracy),
精确率(Precision), 召回率(Recall)
补充的原文地址:/article/7987474.html准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
图示表示如下:
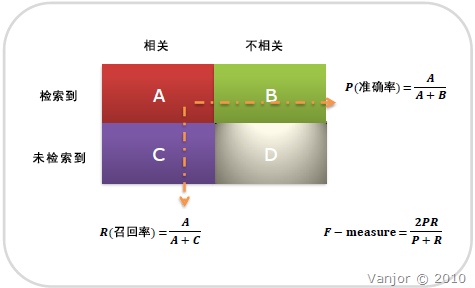
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
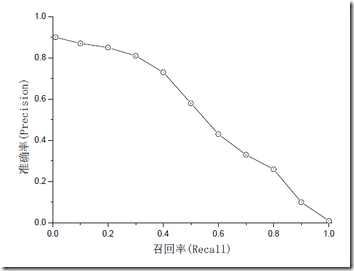
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
[python] view
plaincopy
F1 = 2 * P * R / (P + R)
公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。

相关文章推荐
- 批量更新时更新分布式ID
- pageX-layerX-clientX-offsetX的区别
- xml文件解析(一)
- iOS开发:MJExtension的简单使用
- iOS网络编程1--简介
- 移动端前端UI库—Frozen UI、WeUI、SUI Mobile
- Java中的int和Integer
- 16进制颜色表
- 消息队列中点对点与发布订阅区别
- UML常用图的几种关系的总结
- -stdcall详解
- Eclipse使用技巧 - 4. Eclipse自动注释文件的导出和导入
- Look-alike技术运用实例:有效实现目标粉丝的“爆炸”
- xml文件解析的几种方式
- Java集合(三):Queue队列
- OpenStack安装时Compute节点连不上RabbitMQ
- link和@import两种导入css文件的区别。
- phpstudy APACHE支持.htaccess以及 No input file specified解决方案
- HDFS源码分析之数据块Block、副本Replica
- 为何使用消息系统