Hadoop之MapReduce自定义二次排序流程实例详解
2016-04-07 00:00
561 查看
摘要: Hadoop之MapReduce自定义二次排序流程实例详解
1.如何解决MapReduce二次排序?
2.Map端如何处理?
3.Reduce端如何处理?
4.MapReduce二次排序是如何具体实现的呢?
一、概述
MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的。在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。对于二次排序的实现,网络上已经有很多人分享过了,但是对二次排序的实现的原理以及整个MapReduce框架的处理流程的分析还是有非常大的出入,而且部分分析是没有经过验证的。本文将通过一个实际的MapReduce二次排序例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和map、reduce端的日志来验证所描述的处理流程的正确性。
二、需求描述
1、输入数据:
sort1 1
sort2 3
sort2 77
sort2 54
sort1 2
sort6 22
sort6 221
sort6 20
2、目标输出
sort1 1,2
sort2 3,54,77
sort6 20,22,221
三、解决思路
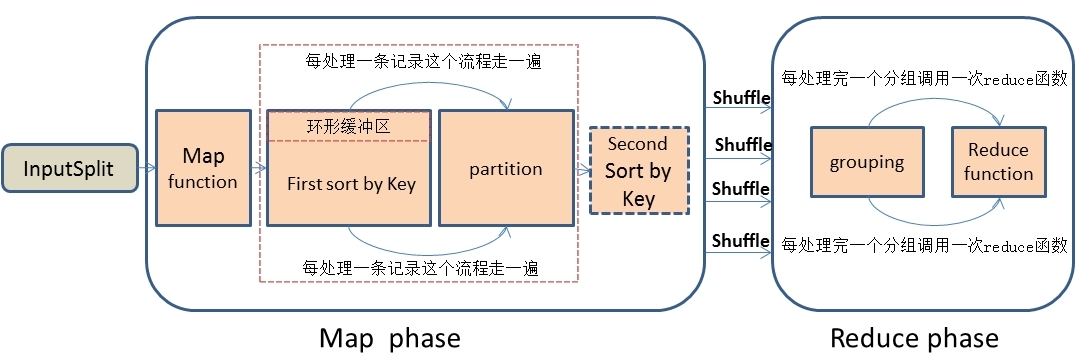
1、首先,在思考解决问题思路时,我们先应该深刻的理解MapReduce处理数据的整个流程,这是最基础的,不然的话是不可能找到解决问题的思路的。我描述一下MapReduce处理数据的大概简单流程:首先,MapReduce框架通过getSplit方法实现对原始文件的切片之后,每一个切片对应着一个map task,inputSplit输入到Map函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过shuffle操作将数据传输到reduce task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照Key值进行分组,然后没处理完一个分组之后就会去调用一次reduce函数,最终输出结果。大概流程我画了一下,如下图:
2、具体解决思路
(1)Map端处理:
根据上面的需求,我们有一个非常明确的目标就是要对第一列相同的记录合并,并且对合并后的数字进行排序。我们都知道MapReduce框架不管是默认排序或者是自定义排序都只是对Key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的Key值和其对应的数据组合成一个新的Key值,然后新的Key值对应的还是之前的数字。那么我们就可以将原始数据的map输出变成类似下面的数据结构:
{[sort1,1],1}
{[sort2,3],3}
{[sort2,77],77}
{[sort2,54],54}
{[sort1,2],2}
{[sort6,22],22}
{[sort6,221],221}
{[sort6,20],20}
那么我们只需要对[]里面的新key值进行排序就ok了。然后我们需要自定义一个分区处理器,因为我的目标不是想将新key相同的传到同一个reduce中,而是想将新key中的第一个字段相同的才放到同一个reduce中进行分组合并,所以我们需要根据新key值中的第一个字段来自定义一个分区处理器。通过分区操作后,得到的数据流如下:
Partition1:{[sort1,1],1}、{[sort1,2],2}
Partition2:{[sort2,3],3}、{[sort2,77],77}、{[sort2,54],54}
Partition3:{[sort6,22],22}、{[sort6,221],221}、{[sort6,20],20}
分区操作完成之后,我调用自己的自定义排序器对新的Key值进行排序。
{[sort1,1],1}
{[sort1,2],2}
{[sort2,3],3}
{[sort2,54],54}
{[sort2,77],77}
{[sort6,20],20}
{[sort6,22],22}
{[sort6,221],221}
(2)Reduce端处理:
经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端对按照组合键的第一个字段来进行分组,并且没处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理输出。最终的各个分组的数据结构变成类似下面的数据结构:
{sort1,[1,2]}
{sort2,[3,54,77]}
{sort6,[20,22,221]}
四、具体实现
1、自定义组合键
package com.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.Hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义组合键
* @author zenghzhaozheng
*/
public class CombinationKey implements WritableComparable<CombinationKey>{
private static final Logger logger = LoggerFactory.getLogger(CombinationKey.class);
private Text firstKey;
private IntWritable secondKey;
public CombinationKey() {
this.firstKey = new Text();
this.secondKey = new IntWritable();
}
public Text getFirstKey() {
return this.firstKey;
}
public void setFirstKey(Text firstKey) {
this.firstKey = firstKey;
}
public IntWritable getSecondKey() {
return this.secondKey;
}
public void setSecondKey(IntWritable secondKey) {
this.secondKey = secondKey;
}
@Override
public void readFields(DataInput dateInput) throws IOException {
// TODO Auto-generated method stub
this.firstKey.readFields(dateInput);
this.secondKey.readFields(dateInput);
}
@Override
public void write(DataOutput outPut) throws IOException {
this.firstKey.write(outPut);
this.secondKey.write(outPut);
}
/**
* 自定义比较策略
* 注意:该比较策略用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,
* 发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整)
*/
@Override
public int compareTo(CombinationKey combinationKey) {
logger.info("-------CombinationKey flag-------");
return this.firstKey.compareTo(combinationKey.getFirstKey());
}
}
说明:在自定义组合键的时候,我们需要特别注意,一定要实现WritableComparable接口,并且实现compareTo方法的比较策略。这个用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整),但是其对我们最终的二次排序结果是没有影响的。我们二次排序的最终结果是由我们的自定义比较器决定的。
2、自定义分区器
package com.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分区
* @author zengzhaozheng
*/
public class DefinedPartition extends Partitioner<CombinationKey,IntWritable>{
private static final Logger logger = LoggerFactory.getLogger(DefinedPartition.class);
/**
* 数据输入来源:map输出
* @author zengzhaozheng
* @param key map输出键值
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
*/
@Override
public int getPartition(CombinationKey key, IntWritable value,int numPartitions) {
logger.info("--------enter DefinedPartition flag--------");
/**
* 注意:这里采用默认的hash分区实现方法
* 根据组合键的第一个值作为分区
* 这里需要说明一下,如果不自定义分区的话,mapreduce框架会根据默认的hash分区方法,
* 将整个组合将相等的分到一个分区中,这样的话显然不是我们要的效果
*/
logger.info("--------out DefinedPartition flag--------");
return (key.getFirstKey().hashCode()&Integer.MAX_VALUE)%numPartitions;
}
}
说明:具体说明看代码注释。
3、自定义比较器
package com.mr;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义二次排序策略
* @author zengzhaoheng
*/
public class DefinedComparator extends WritableComparator {
private static final Logger logger = LoggerFactory.getLogger(DefinedComparator.class);
public DefinedComparator() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable combinationKeyOne,
WritableComparable CombinationKeyOther) {
logger.info("---------enter DefinedComparator flag---------");
CombinationKey c1 = (CombinationKey) combinationKeyOne;
CombinationKey c2 = (CombinationKey) CombinationKeyOther;
/**
* 确保进行排序的数据在同一个区内,如果不在同一个区则按照组合键中第一个键排序
* 另外,这个判断是可以调整最终输出的组合键第一个值的排序
* 下面这种比较对第一个字段的排序是升序的,如果想降序这将c1和c2���过来(假设1)
*/
if(!c1.getFirstKey().equals(c2.getFirstKey())){
logger.info("---------out DefinedComparator flag---------");
return c1.getFirstKey().compareTo(c2.getFirstKey());
}
else{//按照组合键的第二个键的升序排序,将c1和c2倒过来则是按照数字的降序排序(假设2)
logger.info("---------out DefinedComparator flag---------");
return c1.getSecondKey().get()-c2.getSecondKey().get();//0,负数,正数
}
/**
* (1)按照上面的这种实现最终的二次排序结果为:
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
* (2)如果实现假设1,则最终的二次排序结果为:
* sort6 20,22,221
* sort2 3,54,77
* sort1 1,2
* (3)如果实现假设2,则最终的二次排序结果为:
* sort1 2,1
* sort2 77,54,3
* sort6 221,22,20
*/
}
}
说明:自定义比较器决定了我们二次排序的结果。自定义比较器需要继承WritableComparator类,并且重写compare方法实现自己的比较策略。具体的排序问题请看注释。
1.如何解决MapReduce二次排序?
2.Map端如何处理?
3.Reduce端如何处理?
4.MapReduce二次排序是如何具体实现的呢?
一、概述
MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的。在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。对于二次排序的实现,网络上已经有很多人分享过了,但是对二次排序的实现的原理以及整个MapReduce框架的处理流程的分析还是有非常大的出入,而且部分分析是没有经过验证的。本文将通过一个实际的MapReduce二次排序例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和map、reduce端的日志来验证所描述的处理流程的正确性。
二、需求描述
1、输入数据:
sort1 1
sort2 3
sort2 77
sort2 54
sort1 2
sort6 22
sort6 221
sort6 20
2、目标输出
sort1 1,2
sort2 3,54,77
sort6 20,22,221
三、解决思路
1、首先,在思考解决问题思路时,我们先应该深刻的理解MapReduce处理数据的整个流程,这是最基础的,不然的话是不可能找到解决问题的思路的。我描述一下MapReduce处理数据的大概简单流程:首先,MapReduce框架通过getSplit方法实现对原始文件的切片之后,每一个切片对应着一个map task,inputSplit输入到Map函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过shuffle操作将数据传输到reduce task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照Key值进行分组,然后没处理完一个分组之后就会去调用一次reduce函数,最终输出结果。大概流程我画了一下,如下图:
2、具体解决思路
(1)Map端处理:
根据上面的需求,我们有一个非常明确的目标就是要对第一列相同的记录合并,并且对合并后的数字进行排序。我们都知道MapReduce框架不管是默认排序或者是自定义排序都只是对Key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的Key值和其对应的数据组合成一个新的Key值,然后新的Key值对应的还是之前的数字。那么我们就可以将原始数据的map输出变成类似下面的数据结构:
{[sort1,1],1}
{[sort2,3],3}
{[sort2,77],77}
{[sort2,54],54}
{[sort1,2],2}
{[sort6,22],22}
{[sort6,221],221}
{[sort6,20],20}
那么我们只需要对[]里面的新key值进行排序就ok了。然后我们需要自定义一个分区处理器,因为我的目标不是想将新key相同的传到同一个reduce中,而是想将新key中的第一个字段相同的才放到同一个reduce中进行分组合并,所以我们需要根据新key值中的第一个字段来自定义一个分区处理器。通过分区操作后,得到的数据流如下:
Partition1:{[sort1,1],1}、{[sort1,2],2}
Partition2:{[sort2,3],3}、{[sort2,77],77}、{[sort2,54],54}
Partition3:{[sort6,22],22}、{[sort6,221],221}、{[sort6,20],20}
分区操作完成之后,我调用自己的自定义排序器对新的Key值进行排序。
{[sort1,1],1}
{[sort1,2],2}
{[sort2,3],3}
{[sort2,54],54}
{[sort2,77],77}
{[sort6,20],20}
{[sort6,22],22}
{[sort6,221],221}
(2)Reduce端处理:
经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端对按照组合键的第一个字段来进行分组,并且没处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理输出。最终的各个分组的数据结构变成类似下面的数据结构:
{sort1,[1,2]}
{sort2,[3,54,77]}
{sort6,[20,22,221]}
四、具体实现
1、自定义组合键
package com.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.Hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义组合键
* @author zenghzhaozheng
*/
public class CombinationKey implements WritableComparable<CombinationKey>{
private static final Logger logger = LoggerFactory.getLogger(CombinationKey.class);
private Text firstKey;
private IntWritable secondKey;
public CombinationKey() {
this.firstKey = new Text();
this.secondKey = new IntWritable();
}
public Text getFirstKey() {
return this.firstKey;
}
public void setFirstKey(Text firstKey) {
this.firstKey = firstKey;
}
public IntWritable getSecondKey() {
return this.secondKey;
}
public void setSecondKey(IntWritable secondKey) {
this.secondKey = secondKey;
}
@Override
public void readFields(DataInput dateInput) throws IOException {
// TODO Auto-generated method stub
this.firstKey.readFields(dateInput);
this.secondKey.readFields(dateInput);
}
@Override
public void write(DataOutput outPut) throws IOException {
this.firstKey.write(outPut);
this.secondKey.write(outPut);
}
/**
* 自定义比较策略
* 注意:该比较策略用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,
* 发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整)
*/
@Override
public int compareTo(CombinationKey combinationKey) {
logger.info("-------CombinationKey flag-------");
return this.firstKey.compareTo(combinationKey.getFirstKey());
}
}
说明:在自定义组合键的时候,我们需要特别注意,一定要实现WritableComparable接口,并且实现compareTo方法的比较策略。这个用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整),但是其对我们最终的二次排序结果是没有影响的。我们二次排序的最终结果是由我们的自定义比较器决定的。
2、自定义分区器
package com.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分区
* @author zengzhaozheng
*/
public class DefinedPartition extends Partitioner<CombinationKey,IntWritable>{
private static final Logger logger = LoggerFactory.getLogger(DefinedPartition.class);
/**
* 数据输入来源:map输出
* @author zengzhaozheng
* @param key map输出键值
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
*/
@Override
public int getPartition(CombinationKey key, IntWritable value,int numPartitions) {
logger.info("--------enter DefinedPartition flag--------");
/**
* 注意:这里采用默认的hash分区实现方法
* 根据组合键的第一个值作为分区
* 这里需要说明一下,如果不自定义分区的话,mapreduce框架会根据默认的hash分区方法,
* 将整个组合将相等的分到一个分区中,这样的话显然不是我们要的效果
*/
logger.info("--------out DefinedPartition flag--------");
return (key.getFirstKey().hashCode()&Integer.MAX_VALUE)%numPartitions;
}
}
说明:具体说明看代码注释。
3、自定义比较器
package com.mr;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义二次排序策略
* @author zengzhaoheng
*/
public class DefinedComparator extends WritableComparator {
private static final Logger logger = LoggerFactory.getLogger(DefinedComparator.class);
public DefinedComparator() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable combinationKeyOne,
WritableComparable CombinationKeyOther) {
logger.info("---------enter DefinedComparator flag---------");
CombinationKey c1 = (CombinationKey) combinationKeyOne;
CombinationKey c2 = (CombinationKey) CombinationKeyOther;
/**
* 确保进行排序的数据在同一个区内,如果不在同一个区则按照组合键中第一个键排序
* 另外,这个判断是可以调整最终输出的组合键第一个值的排序
* 下面这种比较对第一个字段的排序是升序的,如果想降序这将c1和c2���过来(假设1)
*/
if(!c1.getFirstKey().equals(c2.getFirstKey())){
logger.info("---------out DefinedComparator flag---------");
return c1.getFirstKey().compareTo(c2.getFirstKey());
}
else{//按照组合键的第二个键的升序排序,将c1和c2倒过来则是按照数字的降序排序(假设2)
logger.info("---------out DefinedComparator flag---------");
return c1.getSecondKey().get()-c2.getSecondKey().get();//0,负数,正数
}
/**
* (1)按照上面的这种实现最终的二次排序结果为:
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
* (2)如果实现假设1,则最终的二次排序结果为:
* sort6 20,22,221
* sort2 3,54,77
* sort1 1,2
* (3)如果实现假设2,则最终的二次排序结果为:
* sort1 2,1
* sort2 77,54,3
* sort6 221,22,20
*/
}
}
说明:自定义比较器决定了我们二次排序的结果。自定义比较器需要继承WritableComparator类,并且重写compare方法实现自己的比较策略。具体的排序问题请看注释。

相关文章推荐
- Hadoop Mapreduce分区、分组、二次排序过程详解
- Linux内核如何装载和启动一个可执行程序
- Activity有四种加载模式:standard(默认), singleTop, singleTask和 singleInstance
- 初识openstack
- 20135202闫佳歆--week 7 Linux内核如何装载和启动一个可执行程序--实验及总结
- 启动文件系统Kernel panic - not syncing: Attempted to kill init! 报错
- Nginx
- 例解 Linux 下 Make 命令
- Linux高性能服务器编程笔记1
- Linux 升级 Python 至 3.x
- Linux 升级 Python 至 3.x
- Opengl新手入门用什么书?
- 为什么需要架构图,怎么画?
- Linux 常用命令
- Linux下安装JDK1.8
- Linux内核分析第七周总结
- hadoop-2.6.0伪分布式单机安装傻瓜教程
- Could not find Developer Disk Image
- Hadoop学习笔记(1):WordCount程序的实现与总结
- openwrt开发<2>环境搭建